




 本文介绍了自然场景下的文本检测和识别OCR技术,包括传统方法和深度学习方法。重点讨论了场景文字识别面临的挑战,如背景多样化、形状和方向变化,以及深度学习模型如CTPN、TextBoxes和FOTS在解决这些问题上的应用。OCR的基本步骤包括图像预处理、文本检测和识别,现代方法倾向于使用端到端模型以提高实时性和准确性。
本文介绍了自然场景下的文本检测和识别OCR技术,包括传统方法和深度学习方法。重点讨论了场景文字识别面临的挑战,如背景多样化、形状和方向变化,以及深度学习模型如CTPN、TextBoxes和FOTS在解决这些问题上的应用。OCR的基本步骤包括图像预处理、文本检测和识别,现代方法倾向于使用端到端模型以提高实时性和准确性。
自然场景下的文本检测和识别OCR概述
最近组里有个项目是关于中国能效标识的数据识别,大概是说希望利用计算机视觉的方法得到下图中的ROI并识别ROI里面的字内容。
我国能效标识制度2005年3月1日开始实施 根据《办法》的规定,国家发展和改革委员会、质检总局和国家认监委制定并发布了《中华人民共和国实行能源效率标识的产品目录(第一批)》、《中国能源效率标识基本样式》、《家用电冰箱能源效率标识实施规则》和《房间空气调节器能源效率标识实施规则》(2004年71号),自2005年3月1日起将率先从冰箱、空调这两个产品开始实施能源效率标识制度。
能效标识为蓝白背景,顶部标有“中国能效标识”(CHINA ENERGY LABEL)字样,背部有粘性,要求粘贴在产品的正面面板上。标识的结构可分为背景信息栏、能源效率等级展示栏和产品相关指标展示栏。作为一种信息标识,能效标识直观地明示了用能产品的能源效率等级、能源消耗指标以及其他比较重要的性能指标,而能源效率等级是判断产品是否节能的最重要指标,产品的能源效率等级越低,表示能源效率越高,节能效果越好,越省电。我国的能效标识将能效分为1、2、3、4、5共五个等级,等级1表示产品达到国际先进水平,最节电,即耗能最低;等级2 表示比较节电;等级3表示产品的能源效率为我国市场的平均水平;等级4表示产品能源效率低于市场平均水平;等级5是市场准入指标,低于该等级要求的产品不允许生产和销售。为了在各类消费者群体中普及节能增效意识,能效等级展示栏用3种表现形式来直观表达能源效率等级信息:一是文字部分“耗能低、中等、耗能高”;二是数字部分“1、2、3、4、5”;三是根据色彩所代表的情感安排的等级指示色标,其中红色代表禁止,橙色代表警告,绿色代表环保与节能。
因此能效标识可以使消费者能够对不同产品的节能效果进行比较,从而使消费者能够购买到更节能、更省钱的产品。
中国能效强制实施的产品有:显示器、液晶电视机、等离子电视机、电饭锅、电磁炉、家用洗衣机、电冰箱、储水式电热水器、节能灯、高压钠灯、打印机、复印机、电风扇、空调等。
2016 年 6 月 1 日起施行《新版能源效率标识管理办法》。

OCR全称Optical Character Recognition,即光学字符识别,最早在1929年被德国科学家Tausheck提出,定义为将印刷体的字符从纸质文档中识别出来。现在的OCR,狭义上指对输入扫描文档图像进行分析处理,识别出图像中文字信息。而随着OCR技术的日益发展,人们已不再仅仅满足于文档或书本上的文字,开始将目标转移到现实世界场景中的文字,这被称为场景文字识别(Scene Text Recognition,STR)。
因此目前的OCR通常泛指所有图像文字检测和识别技术,包括传统文档图像识别与场景文字识别技术。场景文字识别技术可以被看成是传统OCR技术的演进与升级,面临着许多新的困难和挑战。目前,学术界在OCR领域的研究也多集中在自然场景下的文本识别。
场景文字识别主要面临的问题有:
- 背景多样化.尤其是自然场景下,文本行的背景可以为任意,同时还会受一些结构相近的背景影响(如栅栏)。
- 文本行形状和方向的多样化。如水平、垂直、倾斜、曲线等。
- 文本行颜色、字体、尺度的多样化。
- 不同程度的透视变换。
- 恶劣的光照条件和不同程度的遮挡。
针对本次项目来说,我认为最主要的问题是倾斜程度导致的角度问题以及光照问题。
OCR可以分为3个基本步骤:图像预处理、文本检测和文本识别。按照处理的方式可以分为传统方法和目前使用的较多的深度学习的方法。
传统方法
传统方法一般是通过OPENCV算法库来进行实现,通过图像处理的方法来寻找和提取图像中的文字信息,使用到的技术包括二值化、噪声滤除、连通域分析和Adaboost、SVM等。
传统方式的OCR可以分为图像预处理、文字识别和后处理三个阶段:预处理阶段需要通过文字区域定位、文字矫正、字符分割等流程得到单个的文字区域;识别阶段通过SVM、Adaboost等分类器识别具体的文本内容;后处理阶段利用规则和语言模型对识别的结果进行优化。
基本传统方法的OCR技术步骤繁多,且模型的鲁棒性不佳,其中一些图像预处理的方式可以适当借鉴,所以这里就不过多赘述。
深度学习方法
深度学习的方法可以分为两类:一类是将OCR分为文字检测和文字识别两个阶段去做;一类是通过端到端的模型一次性完成文字的检测和识别。
文本检测结合文字识别
文本检测
起初的文字检测是将诸如yolo、ssd等物体检测方法直接运用在文本检测上,但是由于文本的检测相对于传统的物体检测存在以下特点,导致效果不是很理想。
- 相比于常规物体,文本行长度、长宽比例变化范围很大。
- 文本行是有方向性的。常规物体边框BBox的四元组描述方式信息量不充足。
- 自然场景中某些物体局部图像与字母形状相似,如果不参考图像全局信息将有误报。
- 有些艺术字体使用了弯曲的文本行,而手写字体变化模式也很多。
- 由于丰富的背景图像干扰,手工设计特征在自然场景文本识别任务中不够鲁棒。
之后研究人员在传统目标检测的基础上, 结合文本检测的特点进行改进,产生了很多优秀的文本检测模型,例如CTPN、TextBoxes、EAST、SegLink等。
- CTPN方案中,用BiLSTM模块提取字符所在图像上下文特征,以提高文本块识别精度。
- SegLink将单词切割为更易检测的小文字块,再预测邻近连接将小文字块连成词。
- TextBoxes等方案中,调整了文字区域参考框的长宽比例,并将特征层卷积核调整为长方形,从而更适合检测出细长型的文本行。
另外文本的检测还有基于分割的思路,采用语义分割的方法,通过分割的结果构建文本行,比如PixelLink和FTSN,但是分割的方法相对来说模型的计算量较大,在实际的场景中表现的效果不佳。
文字识别
文字的识别也分为两种方式,单文字的识别和文本行的识别,主要还是依据上一步文字检测的结果来进行扩展。单字符的识别而言可以认为是一个物体分类的问题,可以采用resnet、vgg、densenet等网络来进行文字的识别,但是这个时候需要考虑模型的大小问题。另外是对文本行的识别,由于RNN循环神经网络对序列有着较好的检测效果,所以一般是CNN+RNN+CTC( Connectionist Temporal Classification,连接时序分类)或者是CNN+RNN+Attention来进行文字的识别。
比如下图是基于视觉注意力的文字识别算法。主要分为以下三步:
- 模型首先在输入图片上运行滑动CNN以提取特征;
- 将所得特征序列输入到推叠在CNN顶部的LSTM进行特征序列的编码;
- 使用注意力模型进行解码,并输出标签序列。
本方法采用的attention模型允许解码器在每一步的解码过程中,将编码器的隐藏状态通过加权平均,计算可变的上下文向量,因此可以时刻读取最相关的信息,而不必完全依赖于上一时刻的隐藏状态。
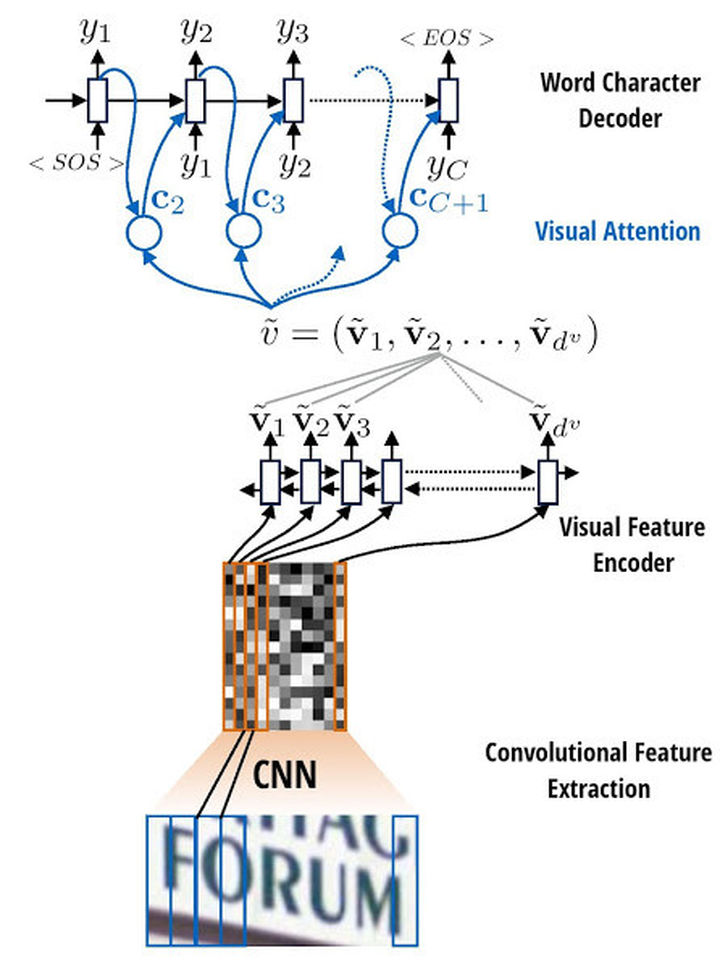
端到端的文字识别
使用文字检测加文字识别两步法虽然可以实现场景文字的识别,但融合两个步骤的结果时仍需使用大量的手工知识,且会增加时间的消耗,而端对端文字识别能够同时完成检测和识别任务,极大的提高了文字识别的实时性。端到端模型的训练效率更高,在预测阶段资源开销更少。比较典型的有STN-ORC和FOTS,以FOTS为例。
FOTS是一个快速的端对端的文字检测与识别框架,通过共享训练特征、互补监督的方法减少了特征提取所需的时间,从而加快了整体的速度。其整体结构如图所示:
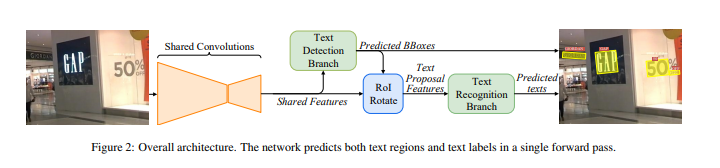
- 卷积共享:从输入图象中提取特征,并将底层和高层的特征进行融合;
- 文本检测:通过转化共享特征,输出每像素的文本预测;
- ROIRotate:将有角度的文本块,通过仿射变换转化为正常的轴对齐的本文块;
- 文本识别:使用ROIRotate转换的区域特征来得到文本标签。
FOTS是一个将检测和识别集成化的框架,具有速度快、精度高、支持多角度等优点,减少了其他模型带来的文本遗漏、误识别等问题。该方法是2018年提出的,受到商汤科技的限制,并没有公开相应的源码。
参考
https://github.com/hwalsuklee/awesome-deep-text-detection-recognition
https://zhuanlan.zhihu.com/p/107404548
https://zhuanlan.zhihu.com/p/159652421


















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











