






 本文介绍了一种利用卷积神经网络(CNN)自动识别图形验证码的方法。通过自动生成验证码及本地标记的验证码图像进行训练,最终模型能在真实环境中达到99%的识别准确率。
本文介绍了一种利用卷积神经网络(CNN)自动识别图形验证码的方法。通过自动生成验证码及本地标记的验证码图像进行训练,最终模型能在真实环境中达到99%的识别准确率。
人工智能:
伴随计算机的发展,人工智能被推向了风口浪尖,成为计算机领域炙手可热的技术,任何一家互联网
公司都会或多或少的接触的这方面的技术。之前 阿尔法狗VS 柯洁,阿尔法狗3:0大胜,让大家更直观了解到机器学习,
了解到了人工智能,大量资金涌入人工智能,机器学习领域,成就了现在大家日常的生活中。
我们日常生活中也存在很多人工智能的产物,最简单的是现在日渐普及的 AI 美颜相机,智慧城市,智慧家,这都是机器学习 +优化算法 的产物。
验证码背景:
大家想必在生活中,会遇到各种验证码,为什么会产生验证码?为什么我们在注册各种app时候会受到各种验证短信? 其实不必要纠结,其实是为了反爬虫,反撞库的技术策略,有人会纠结,反爬虫跟验码有个毛关系,我可以负责人的告诉大家,其实验证码是一种安全策略,为了保证大家在正常使用中的信息安全,以及企业为了防止别人恶意攻击手段,别看小小验证码,在机器学习之前还是很安全的。他能判断出是正常用户、还是机器恶意攻击,正常用户可以正常输入所看到的验证码信息,而机器则识别不出来。 网站为了网站信息安全也会设置验证码,保护自身网站的安全性,在抵挡别人恶意撞库测试。验证码的形式多种多样,我们列举我们常见的几种验证码,供大家了解:
| 列表 | 类型 | 详细 |
|---|---|---|
| 1 | 滑动解锁 | 一键式解锁从左滑到右 |
| 2 | 滑动拼图 | 滑动拼接图片 |
| 3 | 验证码手动输入 | 输入正确验证码 |
| 4 | 汉字选取 | 选取提示所示汉字 |


为了方便我们模型测试,我这是生成的验证码,当然我们也可以用本地截取的验证码,我会在代码中注明如何使用本地验证码:
gen_captcha.py 文件
#coding=utf-8
from captcha.image import ImageCaptcha # pip install captcha
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import random
import os,glob
# 验证码中的字符, 就不用汉字了
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z']
ALPHABET = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U',
'V', 'W', 'X', 'Y', 'Z']
'''
number=['0','1','2','3','4','5','6','7','8','9']
alphabet =[]
ALPHABET =[]
'''
# DATA_DIR = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'data')
# DEFAULT_FONTS = [os.path.join(DATA_DIR, 'DroidSansMono.ttf')]
#
# class ImageCaptcha(ImageCaptcha):
#
# def __init__(self):
# # (self, width=180, height=67, fonts=None, font_sizes=None):
# self._width = 180
# self._height = 67
# self._fonts = None or DEFAULT_FONTS
# self._font_sizes = None or (42, 50, 56)
# self._truefonts = []
# 验证码一般都无视大小写;验证码长度4个字符
def random_captcha_text(char_set=number + alphabet + ALPHABET, captcha_size=4):
captcha_text = []
for i in range(captcha_size):
c = random.choice(char_set)
captcha_text.append(c)
return captcha_text
# 生成字符对应的验证码
def gen_captcha_text_and_image():
while(1):
image = ImageCaptcha(180,67)
# image = ImageCaptcha()
captcha_text = random_captcha_text()
captcha_text = ''.join(captcha_text)
path = 'F://CNN_1/test/'
print("-----------------"+captcha_text)
captcha = image.generate(captcha_text)
# image.write(captcha_text, path+captcha_text + '.jpg') # 写到文件
captcha_image = Image.open(captcha)
#captcha_image.show()
captcha_image = np.array(captcha_image)
if captcha_image.shape==(67,180,4):
break
return captcha_text, captcha_image
#读取本地打好标记的验证码
def get_name_and_image():
list = glob.glob(r"C:\Users\Administrator\Desktop\1\*.png")
num =random.randint(0,len(list)-1)
path = list[num]
# print(path)
p, image_text = path.split('_')
captcha_text, type = image_text.split('.')
captcha_image = Image.open(path)
captcha_image = np.array(captcha_image)
return captcha_text, captcha_image
if __name__ == '__main__':
while 1:
# 测试
text, image = gen_captcha_text_and_image()
# print image
gray = np.mean(image, -1)
# print gray
# print image.shape
# print gray.shape
f = plt.figure()
ax = f.add_subplot(111)
ax.text(0.1, 0.9, text, ha='center', va='center', transform=ax.transAxes)
plt.imshow(image)
plt.show()
上述代码中,有两种方式,1 生成验证码作为训练字库 2 另一种是自己打标记
这是我打好标记的验证码,如下

train.py 代码:
#coding=utf-8
from gen_captcha import gen_captcha_text_and_image,read_localhost_images,get_name_and_image
from gen_captcha import number
from gen_captcha import alphabet
from gen_captcha import ALPHABET
from PIL import Image
import numpy as np
import tensorflow as tf
"""
text, image = gen_captcha_text_and_image()
print "验证码图像channel:", image.shape # (60, 160, 3)
# 图像大小
IMAGE_HEIGHT = 67
IMAGE_WIDTH = 180
MAX_CAPTCHA = len(text)
print "验证码文本最长字符数", MAX_CAPTCHA # 验证码最长4字符; 我全部固定为4,可以不固定. 如果验证码长度小于4,用'_'补齐
"""
IMAGE_HEIGHT = 67 #图片高度
IMAGE_WIDTH = 180 #宽度
MAX_CAPTCHA = 4 #最大字符,验证码训练样本
# 把彩色图像转为灰度图像(色彩对识别验证码没有什么用)
def convert2gray(img):
if len(img.shape) > 2:
gray = np.mean(img, -1)
# 上面的转法较快,正规转法如下
# r, g, b = img[:,:,0], img[:,:,1], img[:,:,2]
# gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray
else:
return img
"""
cnn在图像大小是2的倍数时性能最高, 如果你用的图像大小不是2的倍数,可以在图像边缘补无用像素。
np.pad(image,((2,3),(2,2)), 'constant', constant_values=(255,)) # 在图像上补2行,下补3行,左补2行,右补2行
"""
# 文本转向量
char_set = number + alphabet + ALPHABET + ['_'] # 如果验证码长度小于4, '_'用来补齐
CHAR_SET_LEN = len(char_set)
def text2vec(text):
text_len = len(text)
if text_len > MAX_CAPTCHA:
raise ValueError('验证码最长4个字符')
vector = np.zeros(MAX_CAPTCHA * CHAR_SET_LEN)
def char2pos(c):
if c == '_':
k = 62
return k
k = ord(c) - 48
if k > 9:
k = ord(c) - 55
if k > 35:
k = ord(c) - 61
if k > 61:
raise ValueError('No Map')
return k
for i, c in enumerate(text):
#print text
idx = i * CHAR_SET_LEN + char2pos(c)
#print i,CHAR_SET_LEN,char2pos(c),idx
vector[idx] = 1
return vector
#print text2vec('1aZ_')
# 向量转回文本
def vec2text(vec):
char_pos = vec.nonzero()[0]
text = []
for i, c in enumerate(char_pos):
char_at_pos = i # c/63
char_idx = c % CHAR_SET_LEN
if char_idx < 10:
char_code = char_idx + ord('0')
elif char_idx < 36:
char_code = char_idx - 10 + ord('A')
elif char_idx < 62:
char_code = char_idx - 36 + ord('a')
elif char_idx == 62:
char_code = ord('_')
else:
raise ValueError('error')
text.append(chr(char_code))
return "".join(text)
"""
#向量(大小MAX_CAPTCHA*CHAR_SET_LEN)用0,1编码 每63个编码一个字符,这样顺利有,字符也有
vec = text2vec("F5Sd")
text = vec2text(vec)
print(text) # F5Sd
vec = text2vec("SFd5")
text = vec2text(vec)
print(text) # SFd5
"""
# 生成一个训练batch
def get_next_batch(batch_size=128):
batch_x = np.zeros([batch_size, IMAGE_HEIGHT * IMAGE_WIDTH])
batch_y = np.zeros([batch_size, MAX_CAPTCHA * CHAR_SET_LEN])
# 有时生成图像大小不是(60, 160, 4)
def wrap_gen_captcha_text_and_image():
while True:
# text, image = gen_captcha_text_and_image() #端对端自动生成验证码,可以不用打标记,直接使用
# text, image = read_localhost_images()
text, image = get_name_and_image() #读取本地打好标记验证码
# print(image.shape)
if image.shape == (67, 180, 4):
return text, image
for i in range(batch_size):
text, image = wrap_gen_captcha_text_and_image()
image = convert2gray(image)
batch_x[i, :] = image.flatten() / 255 # (image.flatten()-128)/128 mean为0
batch_y[i, :] = text2vec(text)
return batch_x, batch_y
####################################################################
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT * IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA * CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32) # dropout
# 定义CNN
def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1):
x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
# w_c1_alpha = np.sqrt(2.0/(IMAGE_HEIGHT*IMAGE_WIDTH)) #
# w_c2_alpha = np.sqrt(2.0/(3*3*32))
# w_c3_alpha = np.sqrt(2.0/(3*3*64))
# w_d1_alpha = np.sqrt(2.0/(8*32*64))
# out_alpha = np.sqrt(2.0/1024)
# 3 conv layer
w_c1 = tf.Variable(w_alpha * tf.random_normal([3, 3, 1, 32]))
b_c1 = tf.Variable(b_alpha * tf.random_normal([32]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, keep_prob)
w_c2 = tf.Variable(w_alpha * tf.random_normal([3, 3, 32, 64]))
b_c2 = tf.Variable(b_alpha * tf.random_normal([64]))
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2))
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv2 = tf.nn.dropout(conv2, keep_prob)
w_c3 = tf.Variable(w_alpha * tf.random_normal([3, 3, 64, 64]))
b_c3 = tf.Variable(b_alpha * tf.random_normal([64]))
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3))
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv3 = tf.nn.dropout(conv3, keep_prob)
# Fully connected layer
w_d = tf.Variable(w_alpha * tf.random_normal([9 * 23 * 64, 1024]))
b_d = tf.Variable(b_alpha * tf.random_normal([1024]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
dense = tf.nn.dropout(dense, keep_prob)
w_out = tf.Variable(w_alpha * tf.random_normal([1024, MAX_CAPTCHA * CHAR_SET_LEN]))
b_out = tf.Variable(b_alpha * tf.random_normal([MAX_CAPTCHA * CHAR_SET_LEN]))
out = tf.add(tf.matmul(dense, w_out), b_out)
# out = tf.nn.softmax(out)
return out
# 训练
def train_crack_captcha_cnn():
import time
start_time=time.time()
output = crack_captcha_cnn()
# loss
#loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output, Y))
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=Y))
# 最后一层用来分类的softmax和sigmoid有什么不同?
# optimizer 为了加快训练 learning_rate应该开始大,然后慢慢衰
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN])
max_idx_p = tf.argmax(predict, 2)
max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
correct_pred = tf.equal(max_idx_p, max_idx_l)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
step = 0
while True:
batch_x, batch_y = get_next_batch(64)
_, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.75})
print (time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),step, loss_)
# 每100 step计算一次准确率
if step % 100 == 0:
batch_x_test, batch_y_test = get_next_batch(100)
acc = sess.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.})
print (u'***************************************************************第%s次的准确率为%s'%(step, acc))
# 如果准确率大于50%,保存模型,完成训练
if acc > 0.99: ##我这里设了0.9,设得越大训练要花的时间越长,如果设得过于接近1,很难达到。如果使用cpu,花的时间很长,cpu占用很高电脑发烫。
print("保存模型......")
# joblib.dump(sess, "F:/model/rf_model.m")
saver.save(sess, "F:/CNN_2/model_3/crack_capcha.model", global_step=step)
print (time.time()-start_time)
break
step += 1
train_crack_captcha_cnn()
#
# def crack_captcha(captcha_image):
# output = crack_captcha_cnn()
#
# saver = tf.train.Saver()
# with tf.Session() as sess:
# # saver.restore(sess, tf.train.latest_checkpoint('.'))
# # saver.restore(sess, "F:/CNN_1/model/crack_capcha.model-10400")
# saver.restore(sess, "F:/CNN_2/model_2/crack_capcha.model-1700")
#
# predict = tf.argmax(tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
# text_list = sess.run(predict, feed_dict={X: [captcha_image], keep_prob: 1})
# # text_list = sess.run(predict, feed_dict={X: [captcha_image]})
#
# text = text_list[0].tolist()
# vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN)
# i = 0
# for n in text:
# vector[i*CHAR_SET_LEN + n] = 1
# i += 1
# return vec2text(vector)
# path = "C:/Users/Administrator/Desktop/text/text/2.png"
# image = Image.open('f://CNN_1/test/TUFK.jpg')
# image = Image.open('C:/Users/Administrator/Desktop/text/text/3.png')
# image = np.array(image)
# text = 'jvdf'
# image = convert2gray(image)
# image = image.flatten() / 255
# predict_text = crack_captcha(image)
# print("正确: {} 预测: {}".format(text, predict_text))
放两张训练图:
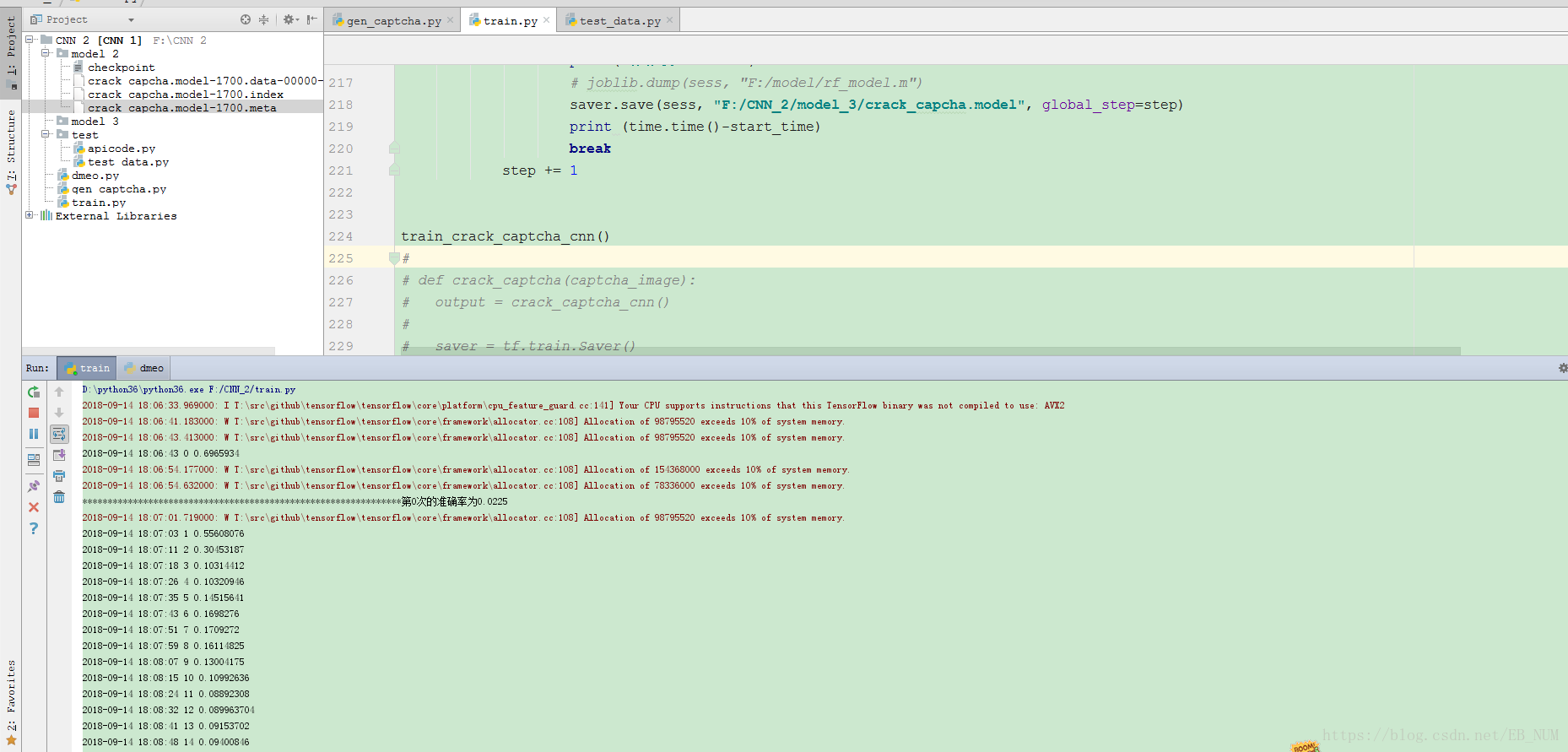
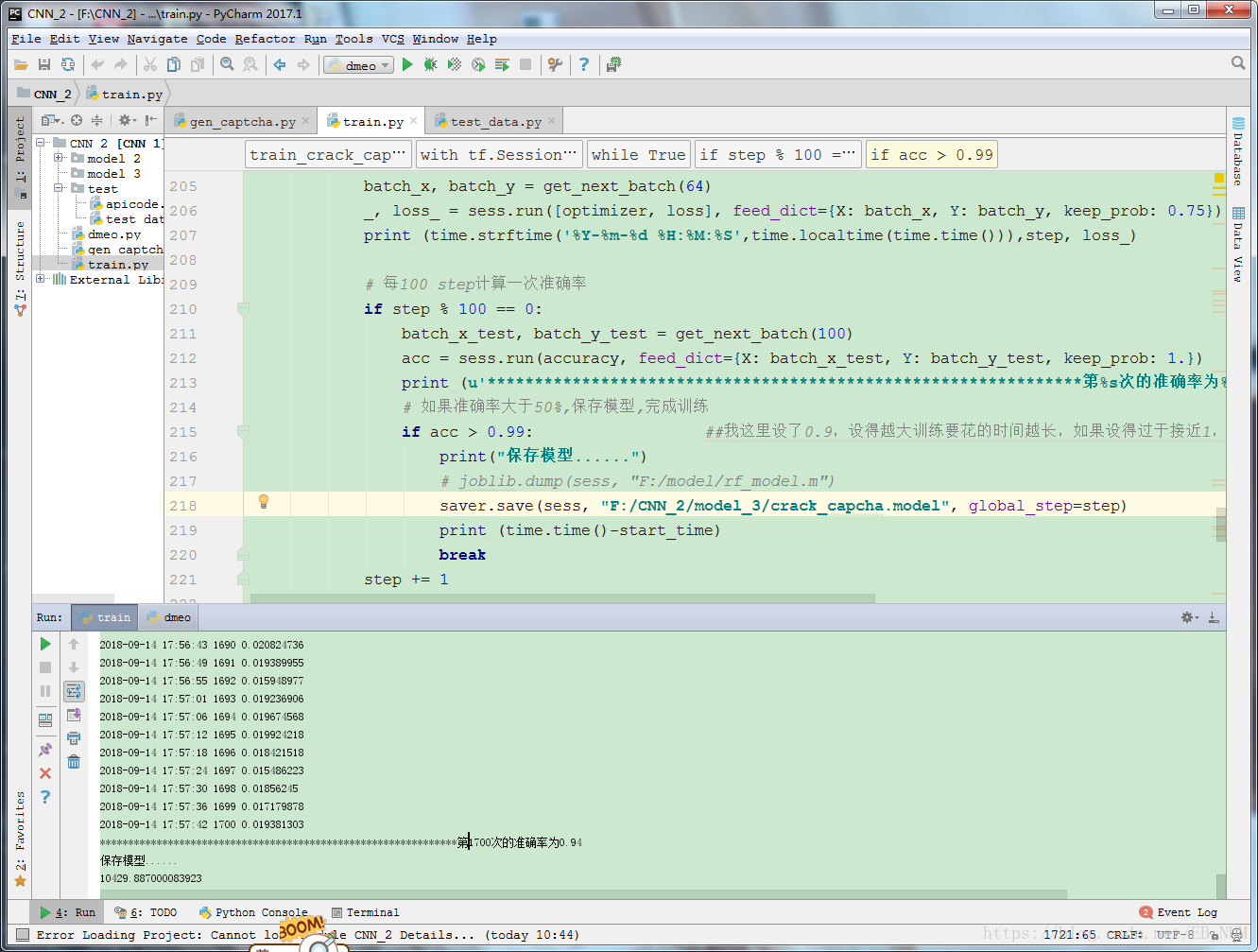
最后样本我训练结果是:99% 正确率
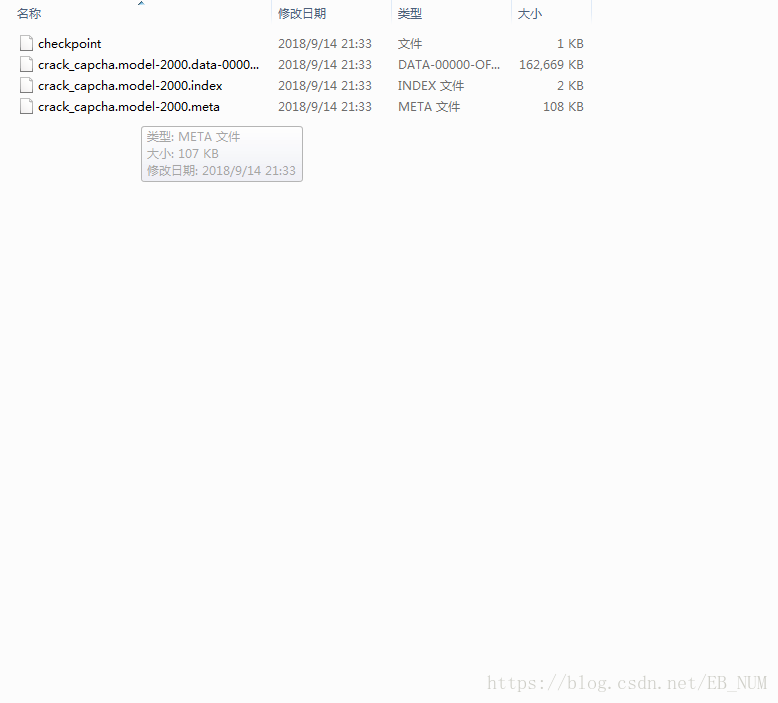
模型保存成功后是四个文件:
from train import crack_captcha_cnn
from train import MAX_CAPTCHA,CHAR_SET_LEN,keep_prob,X
from train import vec2text,convert2gray
from PIL import Image
import numpy as np
import tensorflow as tf
import glob,random
def predict_result(captcha_image):
output = crack_captcha_cnn()
saver = tf.train.Saver()
# tf.reset_default_graph()
with tf.Session() as sess:
saver.restore(sess, "F:/CNN_2/model_3/crack_capcha.model-2000")
predict = tf.argmax(tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
text_list = sess.run(predict, feed_dict={X: [captcha_image], keep_prob: 1})
# text_list = sess.run(predict, feed_dict={X: [captcha_image]})
text = text_list[0].tolist()
vector = np.zeros(MAX_CAPTCHA * CHAR_SET_LEN)
i = 0
for n in text:
vector[i * CHAR_SET_LEN + n] = 1
i += 1
return vec2text(vector)
def get_name_and_image():
list1 = glob.glob(r"C:\Users\Administrator\Desktop\text\text\*.png")
num =random.randint(0,len(list1)-1)
path = list1[num]
print(path)
p, image_text = path.split('_')
captcha_text, type = image_text.split('.')
captcha_image = Image.open(path)
captcha_image = np.array(captcha_image)
image = convert2gray(captcha_image)
image = image.flatten() / 255
return captcha_text, image
if __name__ =="__main__":
text , image =get_name_and_image()
predict_text = predict_result(image)
print("正确: {} 预测: {}".format(text, predict_text))
作者声明:
本文章仅用作技术交流,不用于任何非法商业活动,转载请注明出处。
如果您觉得本文确实帮助了您,可以微信扫一扫,进行小额的打赏和鼓励,谢谢 _


















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









