




 本文详细解析了Hadoop MapReduce中的Shuffle机制,包括Combiner的合并过程、分组策略(GroupingComparator)及其在实际案例中的应用,旨在减少网络传输量并提高效率。
本文详细解析了Hadoop MapReduce中的Shuffle机制,包括Combiner的合并过程、分组策略(GroupingComparator)及其在实际案例中的应用,旨在减少网络传输量并提高效率。
内容较多分开来写,这样吸收起来也好些,附有练习可学习,下面Shuffle补充
1、Shuffle机制
1)Combiner合并 <b,1> <b,1>==<b,2>
(1)combiner是MR程序中Mapper和Reducer之外的一种组件。
(2)combiner组件的父类就是Reducer。
(3)combiner和reducer的区别在于运行的位置:
Combiner是在每一个maptask所在的节点运行;
Reducer是接收全局所有Mapper的输出结果;
(4)combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量。
(5)combiner能够应用的前提是不能影响最终的业务逻辑,而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来。
Mapper
Maptask1:
3 5 7 ->(3+5+7)/3=5
Maptask2:
2 6 ->(2+6)/2=4
Reducer
(3+5+7+2+6)/5=23/5 不等于 (5+4)/2=9/2
(6)自定义Combiner实现步骤:
a)自定义一个combiner继承Reducer,重写reduce方法。
public class WordcountCombiner extends Reducer<Text, IntWritable, Text,
IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
// 1 汇总操作
int count = 0;
for(IntWritable v :values){
count += v.get();
}
// 2 写出
context.write(key, new IntWritable(count));
}
}
b)在job驱动类中设置:
job.setCombinerClass(WordcountCombiner.class);
2)Combiner合并案例实操
(1)需求
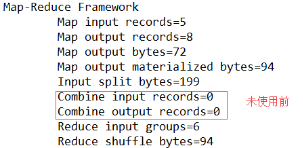
统计过程中对每一个maptask的输出进行局部汇总,以减小网络传输量即采用Combiner功能,如图所示:

(2)数据准备
hello.txt
hello world
bigdata bigdata
hadoop
spark
hello world
bigdata bigdata
hadoop
spark
hello world
bigdata bigdata
hadoop
spark
方案一
a)增加一个WordcountCombiner类继承Reducer。
package com.bigdata.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override//重写父类的reduce方法,在这里实现自己的业务逻辑,在这里统计每个单词出现的总次数
//分组调用,按照key进行分组,如果key一样,则key相同的所有kv,就会在一次reduce方法里面得到调用
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
//<hello,1>,<hello,1>,<hello,1>
//将所有的value遍历,进行累加,value全是1,累加后的结果,就是单词出现的总次数
int sum = 0;
for (IntWritable num : values) {
int i = num.get();
sum = sum + i;
}
//将单词总次数封装为keyvalue对写出,即<单词,总次数> <hello,3>
context.write(key, new IntWritable(sum));
}
}
b)在WordcountDriver驱动类中指定combiner。
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordcountCombiner.class);
方案二
将WordcountReducer作为combiner在WordcountDriver驱动类中指定。
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordcountReducer.class);
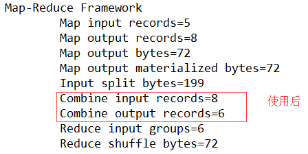
运行程序,如图所示:
未使用前
使用后
3)GroupingComparator分组(辅助排序)
对reduce阶段的数据根据某一个或几个字段进行分组。
partioner是在MapTask阶段将数据写入环形缓冲区中进行的分区操作,其目的是为了划分出几个结果文件(ReduceTask,但是partioner必须小于ReduceTask个数),而是什么决定将一组数据发送给一次Reduce类中的reduce方法中呢?换句话说,Reduce类中的reduce方法中key一样,values有多个,是什么情况下的key是一样的,能不能自定义。其实这就是 GroupingComparator分组(辅助排序)的作用。
4)GroupingComparator分组案例实操
(1)需求
有如下订单数据:

现在需要求出每一个订单中最贵的商品。
(2)输入数据
GroupingComparator.txt
0000001 Pdt_01 222.8
0000002 Pdt_06 722.4
0000001 Pdt_05 25.8
0000003 Pdt_01 222.8
0000003 Pdt_01 33.8
0000002 Pdt_03 522.8
0000002 Pdt_04 122.4
输出数据预期:

(3)分析
a)利用“订单id和成交金额”作为key,可以将map阶段读取到的所有订单数据按照id分区,按照金额排序,发送到reduce。
b)在reduce端利用groupingcomparator将订单id相同的kv聚合成组,然后取第一个即是最大值,如图所示:
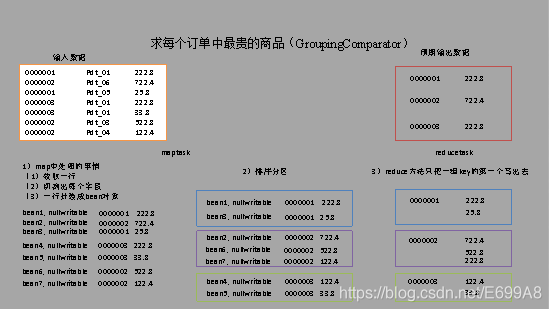
(4)代码实现
第一种方法:
package com.bigdata.maxmoney;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//订单号当keyout
//订单中的商品价格当valueout
//0000001 Pdt_01 222.8
//0000002 Pdt_06 722.4
//0000001 Pdt_05 25.8
//0000003 Pdt_01 222.8
//0000003 Pdt_01 33.8
//0000002 Pdt_03 522.8
//0000002 Pdt_04 122.4
public class MaxMoneyMapper extends Mapper<LongWritable, Text, Text, DoubleWritable>{
Text k = new Text();
DoubleWritable v = new DoubleWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//1 将每行读取过来,转成string
//0000001 Pdt_01 222.8
String line = value.toString();
//2 按照tab截取,挑出订单id、商品金额
//[0000001,Pdt_01,222.8]
String[] split = line.split("\t");
String oid = split[0];
String priceStr = split[2];
//3 组装kv并写出
k.set(oid);
v.set(Double.parseDouble(priceStr));
context.write(k, v);//<0000001,222.8>
}
}
package com.bigdata.maxmoney;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxMoneyReduce extends Reducer<Text, DoubleWritable, Text, DoubleWritable>{
@Override//这是分组调用,根据key进行分组,如果key相同,则分为一组,并且调用一次reduce方法
//<0000001,222.8>
//<0000001,25.8>
protected void reduce(Text key, Iterable<DoubleWritable> values,Context context) throws IOException, InterruptedException {
//1 遍历迭代器,将所有的金额取出,放到集合
ArrayList<Double> list = new ArrayList<Double>();
for (DoubleWritable ss : values) {
double d = ss.get();
list.add(d);
}
Object[] array = list.toArray();
//2 对集合里面的金额排序,挑出最大的金额
Arrays.sort(array);
//3 将订单 最大金额组装为kv并写出
Double object = (Double) array[array.length-1];
context.write(key, new DoubleWritable(object));
}
}
package com.bigdata.maxmoney;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MaxMoneyDriver {
public static void main(String[] args) throws Exception {
//1 创建配置对象
Configuration conf = new Configuration();
//2 通过配置对象,创建job
Job job = Job.getInstance(conf);
//3 设置job的jar包位置
job.setJarByClass(MaxMoneyDriver.class);
//4 设置mapper,reduce类
job.setMapperClass(MaxMoneyMapper.class);
job.setReducerClass(MaxMoneyReduce.class);
//5 设置mapper的keyout,valueout
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
//6 设置最终输出的keyout,valueout
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
//7 设置输入数据的路径,输出数据的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//8 提交任务到yarn集群或者是本地模拟器
boolean waitForCompletion = job.waitForCompletion(true);
System.out.println(waitForCompletion);
}
}
a)定义订单信息OrderBean
package com.bigdata.grouporderby;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class OrderMoney implements WritableComparable<OrderMoney> {
private int oid;
private double price;
public OrderMoney() {
super();
// TODO Auto-generated constructor stub
}
public OrderMoney(int oid, double price) {
super();
this.oid = oid;
this.price = price;
}
public int getOid() {
return oid;
}
public void setOid(int oid) {
this.oid = oid;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public void write(DataOutput out) throws IOException {
out.writeInt(oid);
out.writeDouble(price);
}
public void readFields(DataInput in) throws IOException {
oid = in.readInt();
price = in.readDouble();
}
//先按照订单id升序排序,在按照金额降序排序
public int compareTo(OrderMoney o) {
int res = 0;
if(this.getOid() > o.getOid()){
res = 1;
}else if(this.getOid() < o.getOid()){
res = -1;
}else{
res = this.getPrice() > o.getPrice()?1:-1;
}
return res;
}
@Override
public String toString() {
return oid+"\t"+price;
}
}
b)编写OrderMapper
package com.bigdata.grouporderby;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class GroupMapper extends Mapper<LongWritable, Text, OrderMoney, NullWritable>{
OrderMoney k = new OrderMoney();
NullWritable v = NullWritable.get();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//0000001 Pdt_01 222.8
// 1 将每行数据读取,转换为String
String line = value.toString();
//2 按照tab切分挑出订单id,金额
String[] split = line.split("\t");
//3 组装kv,写出 <OrderMoney,NullWritable>
String oidStr = split[0];
String priceStr = split[2];
k.setOid(Integer.parseInt(oidStr));
k.setPrice(Double.parseDouble(priceStr));
context.write(k, v);
}
}
c)编写OrderPartitioner
package com.bigdata.grouporderby;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class GroupPartitioner extends Partitioner<OrderMoney, NullWritable>{
@Override
public int getPartition(OrderMoney key, NullWritable value, int numPartitions) {
return (key.getOid() & Integer.MAX_VALUE) % numPartitions;
}
}
d)编写OrderGroupingComparator
package com.bigdata.grouporderby;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class MyGroupComparator extends WritableComparator{
public MyGroupComparator() {
super(OrderMoney.class, true);
}
@Override//在这里指定一个规则,该规则定义了什么相同才认为是key相同
public int compare(WritableComparable a, WritableComparable b) {
OrderMoney aa = (OrderMoney) a;
OrderMoney bb = (OrderMoney) b;
int res = 0;
if(aa.getOid() > bb.getOid()){
res = 1;
}else if(aa.getOid() < bb.getOid()){
res = -1;
}
return res;
}
}
e)编写OrderReducer
package com.bigdata.grouporderby;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class GroupReduce extends Reducer<OrderMoney, NullWritable, OrderMoney, NullWritable>{
@Override//
protected void reduce(OrderMoney key, Iterable<NullWritable> values,
Reducer<OrderMoney, NullWritable, OrderMoney, NullWritable>.Context context)
throws IOException, InterruptedException {
for (NullWritable nullWritable : values) {
System.err.println(key.getOid()+"hhhhhhhhhhhhhhhhh");
}
System.err.println("---------------------------");
context.write(key, NullWritable.get());
}
}
f)编写OrderDriver
package com.bigdata.grouporderby;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class GroupDriver {
public static void main(String[] args) throws Exception {
//1 创建配置对象
Configuration conf = new Configuration();
//2 通过配置对象,创建job
Job job = Job.getInstance(conf);
//3 设置job的jar包位置
job.setJarByClass(GroupDriver.class);
//4 设置mapper,reduce类
job.setMapperClass(GroupMapper.class);
job.setReducerClass(GroupReduce.class);
//5 设置mapper的keyout,valueout
job.setMapOutputKeyClass(OrderMoney.class);
job.setMapOutputValueClass(NullWritable.class);
//6 设置最终输出的keyout,valueout
job.setOutputKeyClass(OrderMoney.class);
job.setOutputValueClass(NullWritable.class);
//7 设置输入数据的路径,输出数据的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setGroupingComparatorClass(MyGroupComparator.class);
job.setPartitionerClass(GroupPartitioner.class);
job.setNumReduceTasks(3);
//8 提交任务到yarn集群或者是本地模拟器
boolean waitForCompletion = job.waitForCompletion(true);
System.out.println(waitForCompletion);
}
}
Shuffle机制到这完结,如有问题,多多指教,谢谢观看

















 2337
2337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









