




 本文详细介绍Hadoop集群的搭建过程,包括虚拟机环境准备、JDK与Hadoop安装、集群配置、SSH无密登录设置及集群启动测试。涵盖HDFS、YARN组件配置与时间同步策略。
本文详细介绍Hadoop集群的搭建过程,包括虚拟机环境准备、JDK与Hadoop安装、集群配置、SSH无密登录设置及集群启动测试。涵盖HDFS、YARN组件配置与时间同步策略。
大家好我是AC
如果有看了上篇文章的小哥应该对Hadoop有些了解和认知,下面动手操作
文章目录
Hadoop实现集群搭建
不了解hadoop可以去了解下传送门
虚拟机环境准备
(1)克隆三台虚拟机(参考linux机器克隆)传送门
(2)修改主机名 /etc/sysconfig/network sync然后重启
(3)主机名分别为:hadoop101;hadoop102;hadoop103;
(4)修改克隆虚拟机的静态ip,分别为:
IP分别为:192.168.1.101;192.168.1.102;192.168.1.103
(5)配置主机名和IP的映射关系(便于使用主机名访问虚拟机)
a)修改Linux的主机映射文件(hosts文件)
[root@ hadoop101桌面]# vim /etc/hosts
添加如下内容
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
b)修改window7的主机映射文件(hosts文件)
i.进入C:\Windows\System32\drivers\etc路径
ii.打开hosts文件并添加如下内容
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
(6)关闭防火墙 service iptables stop;chkconfig iptables off
(7)在各个机器上使用root用户在/opt目录下创建module、software文件夹
安装jdk
集群软件安装策略

(1)卸载现有jdk
a)查询是否安装java软件:
[root@hadoop101 opt]# rpm -qa | grep java
b)如果安装的版本低于1.7,卸载该jdk:
[root@hadoop101 opt]# rpm -e --nodeps软件包
(2)用文件传输工具将jdk导入到opt目录下面的software文件夹下面
(3)在linux系统下的opt目录中查看软件包是否导入成功
[root@hadoop101 opt]# cd software/
[root@hadoop101 software]# ls
hadoop-2.7.2.tar.gz jdk-8u144-linux-x64.tar.gz
(4)解压jdk到/opt/module目录下
[root@hadoop101 software]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
(5)配置jdk环境变量
a)先获取jdk路径:
[root@hadoop101 jdk1.8.0_144]# pwd
/opt/module/jdk1.8.0_144
b)打开/etc/profile文件:
[root@hadoop101 software]# vi /etc/profile
在profile文件末尾添加jdk路径:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
c)保存后退出:
:wq
d)让修改后的文件生效:
[root@hadoop101 jdk1.8.0_144]# source /etc/profile
(6)测试jdk是否安装成功
[root@hadoop101 jdk1.8.0_144]# java -version
java version "1.8.0_144"
注意:重启(如果java -version可以用就不用重启)
[root@hadoop101 jdk1.8.0_144]# reboot
安装Hadoop
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
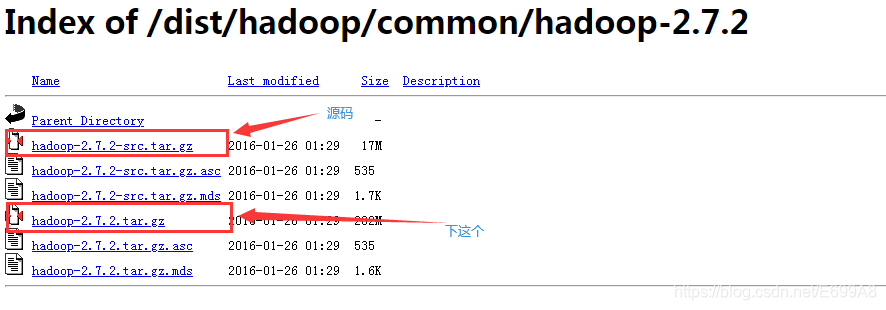
上边是官方下载地址,32位的,如有需要64留言说下,我整理到云盘
(1)用文件传输工具工具将hadoop-2.7.2.tar.gz导入到opt目录下面的software文件夹下面
传输工具有很多,虚拟机自带的还有SecureCRTPortable,xshell等等,这个就不多说了
(2)进入到Hadoop安装包路径下
software和module文件需要自己在opt下创建哈
[root@hadoop101 ~]# cd /opt/software/
(3)解压安装文件到/opt/module下面
[root@hadoop101 software]# tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
(4)查看是否解压成功
[root@hadoop101 software]# ls /opt/module/
hadoop-2.7.2
(5)将hadoop添加到环境变量
a)获取hadoop安装路径:
[root@ hadoop101 hadoop-2.7.2]# pwd
/opt/module/hadoop-2.7.2
b)打开/etc/profile文件:
[root@ hadoop101 hadoop-2.7.2]# vi /etc/profile
在profie文件末尾添加jdk路径:(shitf+g快速到底)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
c)保存后退出:
:wq
d)让修改后的文件生效:
[root@ hadoop101 hadoop-2.7.2]# source /etc/profile
(6)测试是否安装成功
[root @hadoop101 ~]# hadoop version
Hadoop 2.7.2
(7)重启(如果hadoop命令不能用再重启)
[root@ hadoop101 hadoop-2.7.2]# reboot
集群配置
(1)集群部署规划
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNode 和DataNode | DataNode | SecondaryNameNode 和 DataNode |
| YARN | NodeManager | ResourceManager 和NodeManager | NodeManager |
这里为了方便使用到工具Notepad++ ,找不着工具的话用原始也可以,也有写
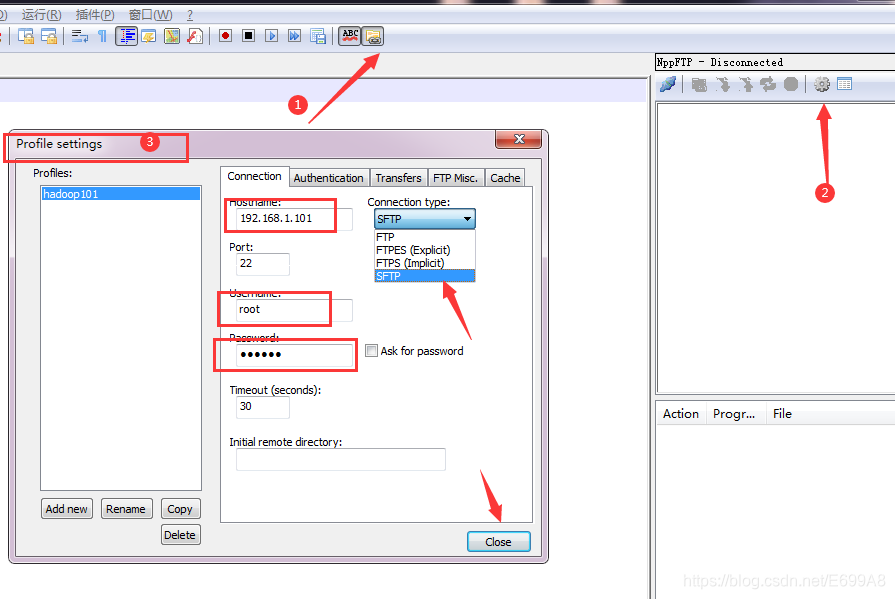
点击小海螺连接,然后选择根目录刷新/
(2)配置集群
a)配置Hadoop所使用Java的环境变量:opt/module/hadoop-2.7.2/etc/hadoop/hadoop-env.sh
[root@hadoop101 hadoop]# vim hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
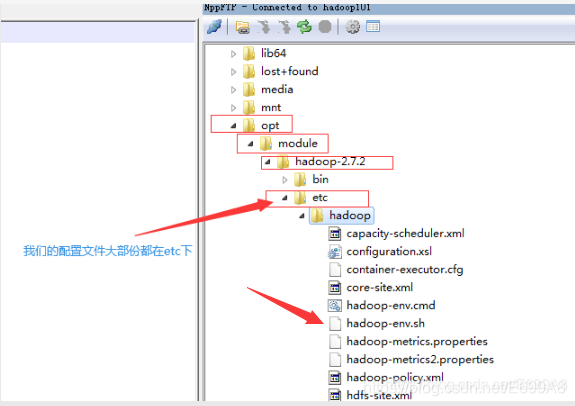
双击下载,把文件中这段代码替换
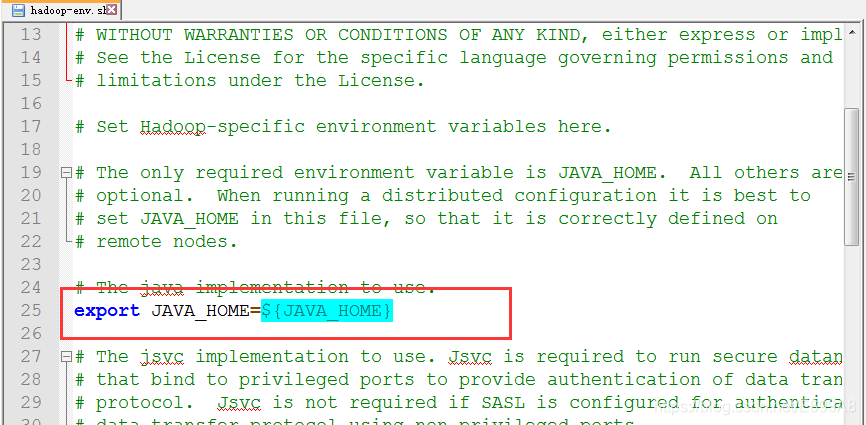
修改后,Ctrl+s保存,注意改完一定要保存

红色就是没保存,蓝色就是保存了

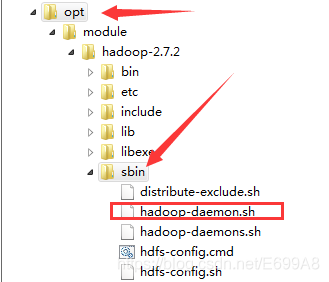
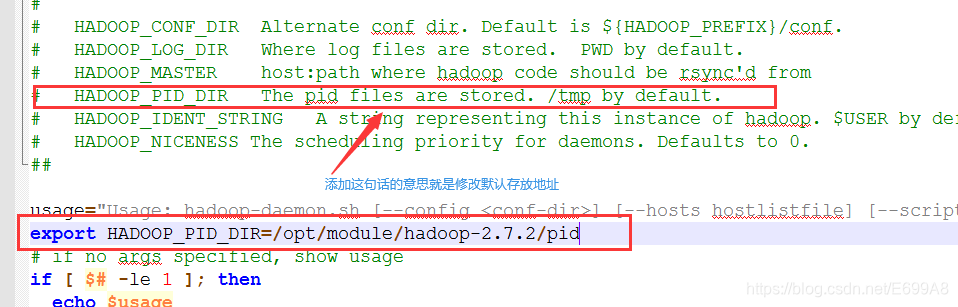
修改pid文件存放位置:(因为默认存放在/tmp下不安全会定期删除)
/opt/module/hadoop-2.7.2/sbin/hadoop-daemon.sh
添加
export HADOOP_PID_DIR=/opt/module/hadoop-2.7.2/pid
注意不是带s的
b)核心配置文件:etc/hadoop/core-site.xml(hdfs的核心配置文件)
[root@hadoop101 hadoop]# vim core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
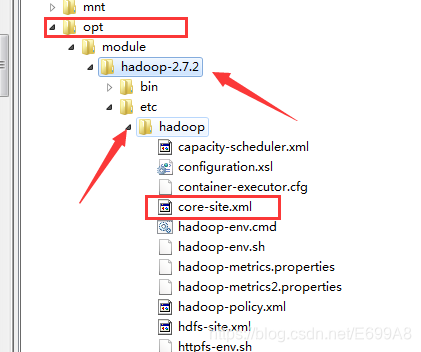
放在configuration里,就是指定NameNode的地址,还有运行产生的文件存储目录
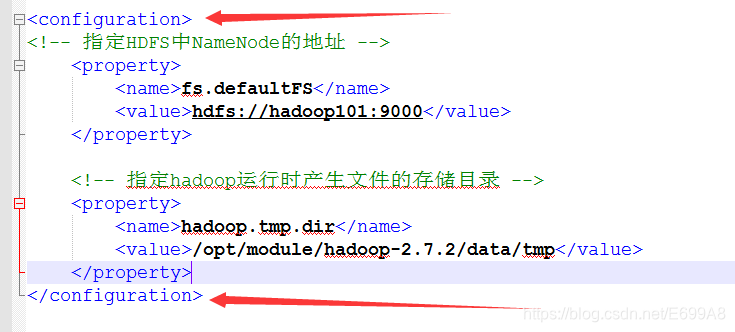
c)hdfs配置文件 hdfs-site.xml
[root@hadoop101 hadoop]# vim hdfs-site.xml
<!--副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondarynamenode的地址,辅助namenode工作 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
hadoop里
同样存入configuration里,就是存副本数量,3,代表3个,有多少集群就可以设几个的副本,还有指定辅助的地址让103担任,已经配置两个了,DataNode不着急暂时先不配。

d)yarn配置文件
yarn-env.sh
配置yarn和namenode同理就是告诉JAVA_HOME放在那里去了,还有指定不让放在默认的tmp目录
我们的配置文件只会在这两个文件中,不是etc就是sbin(记好哦)
[root@hadoop101 hadoop]# vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144

修改pid文件存放位置:
/opt/module/hadoop-2.7.2/sbin/yarn-daemon.sh
添加
export YARN_PID_DIR=/opt/module/hadoop-2.7.2/pid
放在这个空隙就好了。
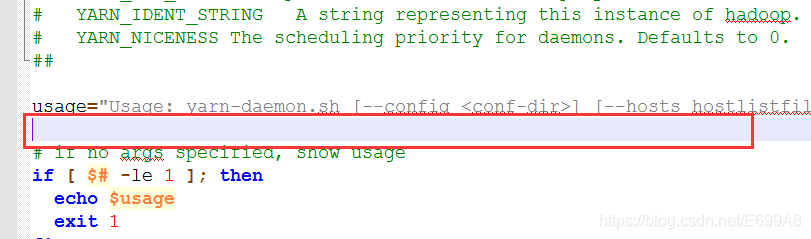
yarn-site.xml
[root@hadoop101 hadoop]# vim yarn-site.xml
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
不要破坏原有的结构粘贴进去,指定MapReduce 发送过来的方式为shuffle(随机),还有指定yarn的老大的地址

e)mapreduce配置文件
到这是不是看出来些规律了,都是要配置这些的,步骤和上边都大致相同的
mapred-env.sh
[root@hadoop101 hadoop]# vim mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144

mapred-site.xml
[root@hadoop101 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@hadoop101 hadoop]# vim mapred-site.xml
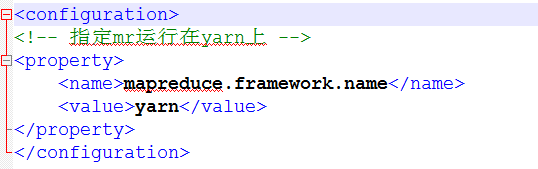
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
将后缀去掉,然后双击下载
然后粘贴到configuration,指定mapreduce运行在yarn上
回顾一下前面所配置的,现在还有,三个datenode,和三个nodemanger还没配吧,在这里配

f)配置集群中从节点信息
看一看它的小弟都有哪几台机器,slaves原意就是奴隶的意思
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
[root@hadoop101 hadoop]# vim slaves
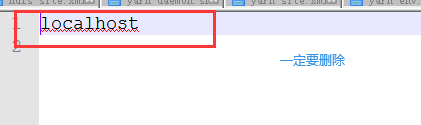
hadoop101
hadoop102
hadoop103
注意,localhost要删掉,
添加小弟名单,完成
(3)分发文件
到这一步hadoop101就已经配置好了但是102,103,还没有,需要我们拷贝过去。
scp:secure copy 安全拷贝
a)scp定义:
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
安装scp命令,这个安装需要每个节点都要安装。(一般不需要装)
yum install -y openssh-server openssh-clients
b)案例实操
将hadoop101中/opt/module目录下的软件拷贝到hadoop102、hadoop103上。
如果第一次,会提示,输yes,输对应密码即可
[root@hadoop101 module]# scp -r hadoop-2.7.2/ hadoop102:/opt/module/
[root@hadoop101 module]# scp -r hadoop-2.7.2/ hadoop103:/opt/module/
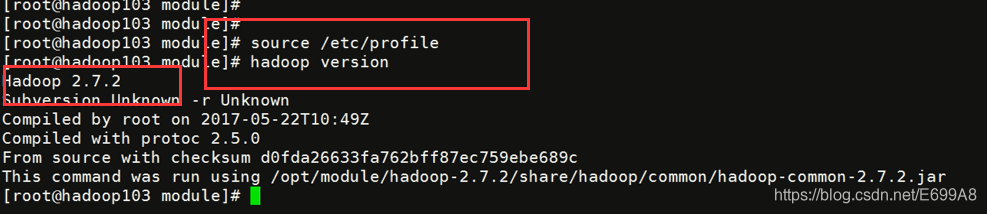
此时环境变量还没加上把101的环境变量复制过去
[root@hadoop101 module]# vi /etc/profile
进入文件shift+g直接到文件底部,复制
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
102,103,复制过去确保都有环境变量
[root@hadoop102 module]# vi /etc/profile
[root@hadoop103 module]# vi /etc/profile
重新加载,查看版本,成功
(4)查看文件分发情况(此步可省略)
[root@hadoop102]#cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
集群单点启动
(1)如果集群是第一次启动,需要格式化NameNode(格式化只进行一次!!!)
[root@hadoop101 hadoop-2.7.2]# hadoop namenode -format
成功在本目录会多个data文件夹

(2)在hadoop101上启动NameNode
[root@hadoop101 hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode
[root@hadoop101 hadoop-2.7.2]# jps
3461 NameNode
启动成功

还可以追踪一下日志看成功与否

里面也没什么东西,一般jps能显示不会有什么错
(3)在hadoop101、hadoop102、hadoop103上分别启动DataNode(和上同理)
[root@hadoop101 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
[root@hadoop101 hadoop-2.7.2]# jps
3461 NameNode
3608 Jps
3561 DataNode
[root@hadoop102 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
[root@hadoop102 hadoop-2.7.2]# jps
3190 DataNode
3279 Jps
[root@hadoop103 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
[root@hadoop103 hadoop-2.7.2]# jps
3237 Jps
3163 DataNode
(4)在hadoop103启动secondarynamenode
[root@hadoop103 hadoop-2.7.2]# sbin/hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-hadoop103.out
[root@hadoop103 hadoop-2.7.2]# jps
4544 Jps
4503 SecondaryNameNode
4395 DataNode
(5)测试分布式文件系统是否能运行
浏览器访问:hadoop101:50070 (这是namenode的监控端口)
如果访问不了,可能防火墙没关,查看
[root@hadoop103 hadoop-2.7.2]# service iptables status
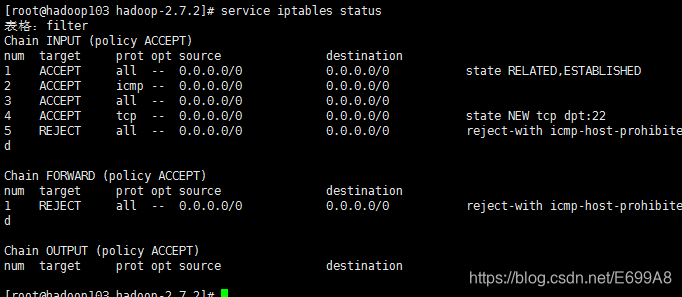
如果出现上图把防火墙关了,这个是关闭,和重启一下
[root@hadoop103 hadoop-2.7.2]# chkconfig iptables off
[root@hadoop103 hadoop-2.7.2]# reboot
成功,重启后要重新启动一下前面的服务(麻烦喔)
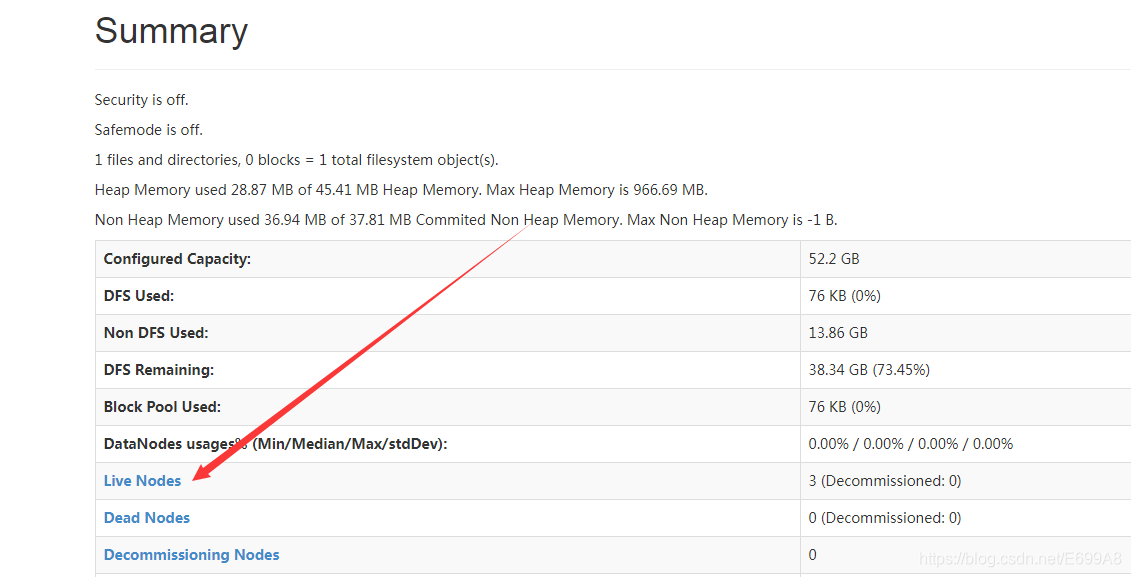
这是我们数据节点的信息
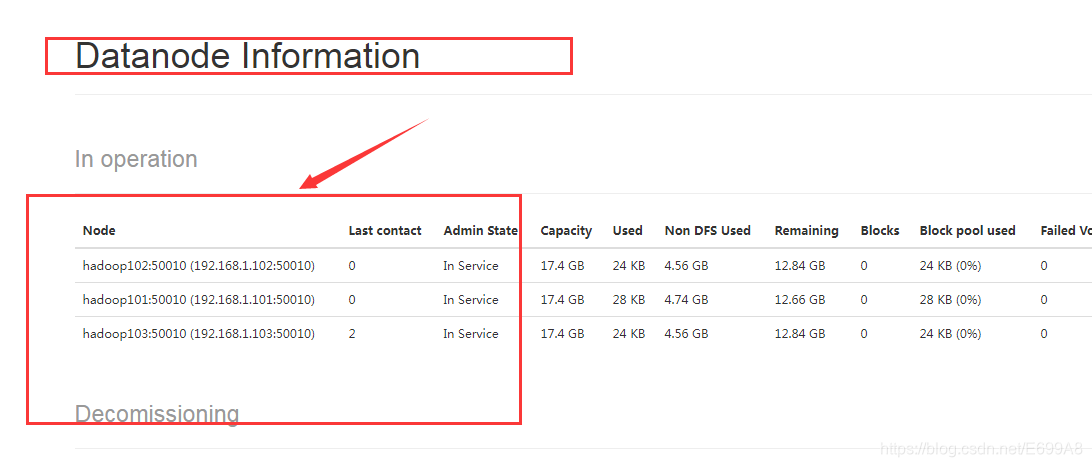
第二名称节点也可以查看,IP是hadoop103:50090端口,不过没啥东西
经历了上边的配置是不是觉得快疯了,启动贼麻烦,特别你要有什么问题重启了,要一个个启动整个人都要崩溃了,所以有没有一个能一下全部启动的呢?答案是有的
首先咱们先把服务给停了,怎么停呢?
先一个个停,不要疯,停其实还好啦,方向键往上翻,翻到历史敲的,把start改为stop就好了,jps检测,示例:
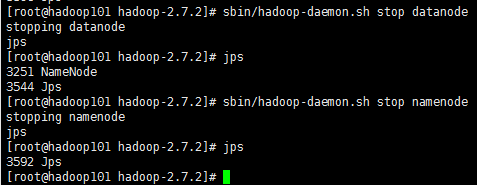
好了,关也关完了,怎么一键启动呢?
sbin/start-dfs.sh
代码很简单,但是先别急,先了解一下原理,其原理是远程登录,就是先远程登录本机把NameNode和DataNode启动好,然后再远程登录到102把DataNode启动好,然后到103,把DataNode和secondarynamenode启动好
什么是远程登录呢,就好比现在使用的软件工具远程登录到101.102.103,当然可以直接在101登录到102.103任意,只要账号密码没问题,可以来回切换,代码实现:
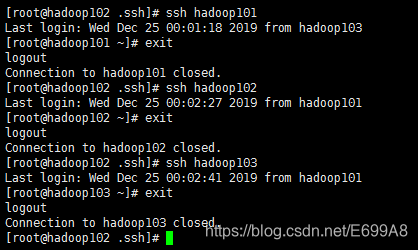
[root@hadoop101 hadoop-2.7.2]# ssh hadoop102
root@hadoop102's password:
Last login: Tue Dec 24 22:39:02 2019 from 192.168.1.1
[root@hadoop102 ~]#
是不是方便很多了,但是这个吧,会出现要频繁输密码,虽说没前面麻烦,但是也挺麻烦。
那有没有不用频繁输密码又可以一键开启,不这么麻烦的呢???
有!!!

下面隆重介绍:
SSH无密登录(又称免密登录)
(1)配置ssh
a)基本语法
ssh 另一台电脑的ip地址
如果提示 command not found,需要安装ssh服务,命令:
yum install -y openssh-server openssh-clients
b)ssh连接时出现Host key verification failed的解决方法:
[root@hadoop101 opt] # ssh hadoop102
The authenticity of host 'hadoop102(192.168.1.102)' can't be established.
RSA key fingerprint is cf:1e:de:d7:d0:4c:2d:98:60:b4:fd:ae:b1:2d:ad:06.
Are you sure you want to continue connecting (yes/no)?
Host key verification failed.
c)解决方案如下:直接输入yes。
(2)无密钥配置
a)免密登录原理
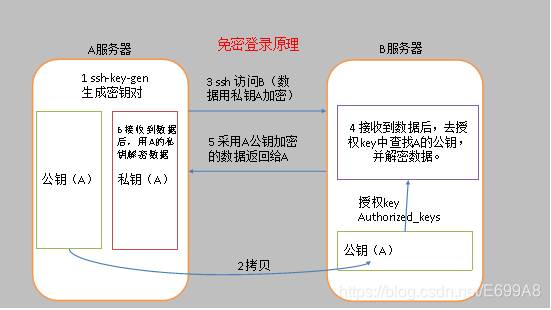
a服务器想要免密登录b,需要把公钥拷贝给它,然后就可以免密登录了,登录过程中怎么通信呢?
a服务器想要登录b服务器它的数据是加密的,3.说明,ssh访问b它要用自己的私钥加密,b接收到用公钥解密,因为它俩是一对。
然后b服务器发送给a服务器的时候再用公钥来加密,然后a服务器再用私钥解密,它们之间通信是加密的。
(3).ssh文件夹下(~/.ssh)的文件功能解释
a)known_hosts :记录ssh访问过计算机的公钥(public key)
b)id_rsa :生成的私钥
c)3、id_rsa.pub :生成的公钥
d)authorized_keys :存放授权过的无密登录服务器公钥
b)生成公钥和私钥:
[root@hadoop101 ~]#cd .ssh/
[root@hadoop101 .ssh]# ssh-keygen -t rsa
== -t rsa是指定的算法==
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
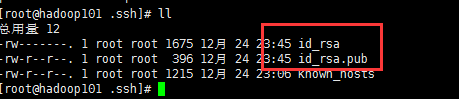
c)将公钥拷贝到要免密登录的目标机器上
要把自己公钥也要拷贝上,按顺序如下,还要注意一点,这个只是把101都可以,如果想102.103,各个都能访问,要都把自己的公钥配置一下
[root@hadoop101 .ssh]# ssh-copy-id hadoop101
[root@hadoop101 .ssh]# ssh-copy-id hadoop102
[root@hadoop101 .ssh]# ssh-copy-id hadoop103
例:公钥拷贝完成后切换102,103,成功免密登录
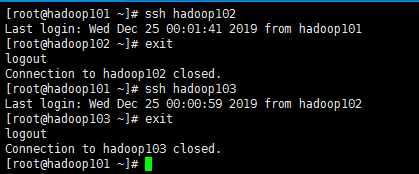
**此时:咱们试一下效果!!,因为我是开着的我先一键全关了,看它会自动去登录去一个个关闭 **
[root@hadoop101 ~]# cd /opt/module/
[root@hadoop101 module]# cd hadoop-2.7.2/
[root@hadoop101 hadoop-2.7.2]# sbin/stop-dfs.sh
Stopping namenodes on [hadoop101]
hadoop101: stopping namenode
hadoop101: stopping datanode
hadoop103: stopping datanode
hadoop102: stopping datanode
Stopping secondary namenodes [hadoop103]
hadoop103: stopping secondarynamenode
[root@hadoop101 hadoop-2.7.2]#
咱们再试一下一键开启:
[root@hadoop101 hadoop-2.7.2]# sbin/start-dfs.sh
Starting namenodes on [hadoop101]
hadoop101: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-hadoop101.out
hadoop102: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop102.out
hadoop103: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop103.out
hadoop101: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop101.out
Starting secondary namenodes [hadoop103]
hadoop103: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-hadoop103.out
访问一下HDFS外部监控看如何:http://hadoop101:50070,成功!!
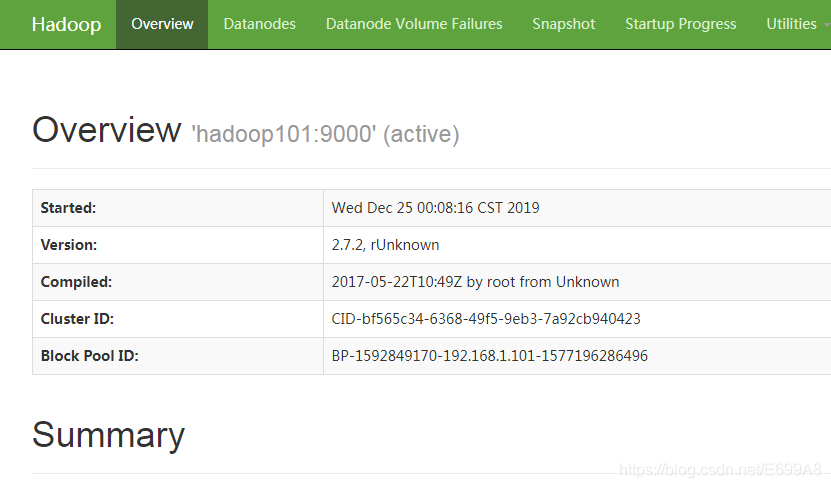
喔!!!好厉害的样子

此时。。是不是还忘了点什么,yarn呢??
还没配呢,哈哈哈。

配配配现在配,在101直接输刚刚的指令不就好了吗,多简单,错!!!
yarn可不是在101配置,还记得当时配置指定在哪里了吗?记不住往上翻翻,我是不会提示在102配置的。
这是102昂。
先免密
[root@hadoop102 ~]# cd /opt/module/hadoop-2.7.2/
[root@hadoop102 hadoop-2.7.2]# sbin/start-yarn.sh
直接指行上面命令还是会让你输密码的,因为刚刚只配了,101的,现在需要给102配置。
[root@hadoop102 ~]# cd .ssh/
[root@hadoop102 .ssh]# ssh-keygen -t rsa
按三个回车,生成文件id_rsa(私钥)、id_rsa.pub(公钥)
[root@hadoop102 .ssh]# ssh-copy-id hadoop101
[root@hadoop102 .ssh]# ssh-copy-id hadoop102
[root@hadoop102 .ssh]# ssh-copy-id hadoop103
验证,一定要验证一下,不然后面出问题不好找。
配置yarn
由于,在102,可以直接把剩下四个启动好了,所以没有必要在103也全部配置一下公钥
[root@hadoop102 .ssh]# cd /opt/module/hadoop-2.7.2/
[root@hadoop102 hadoop-2.7.2]# sbin/start-yarn.sh
[root@hadoop102 hadoop-2.7.2]# jps
4458 DataNode
5323 Jps
5228 NodeManager
4734 ResourceManager
测试:
102也有个端口:hadoop:8088
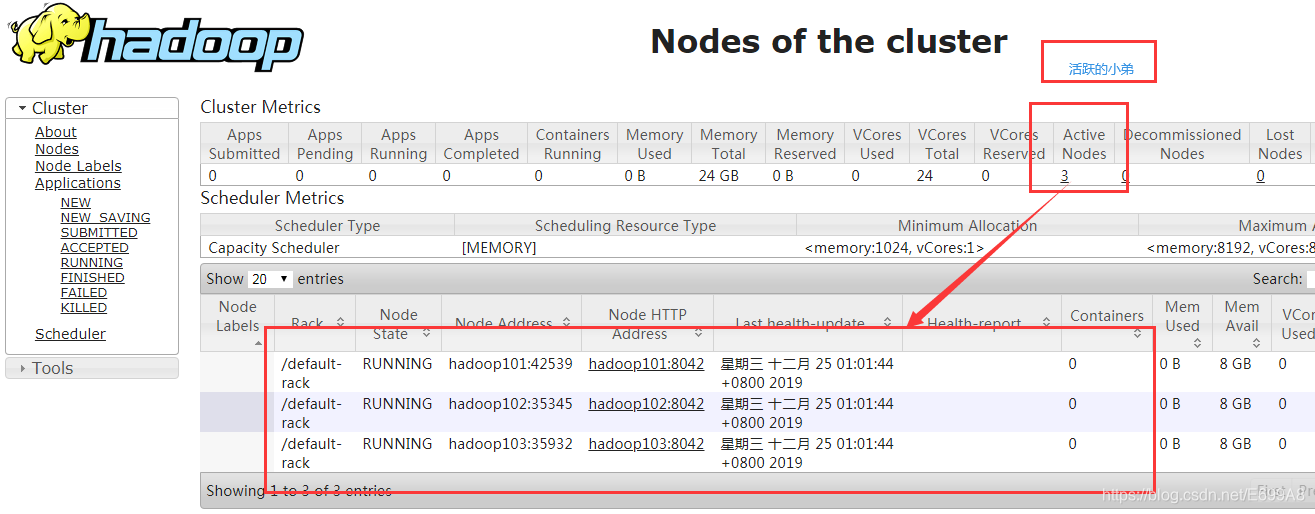
访问成功
关闭:[root@hadoop102 hadoop-2.7.2]# sbin/stop-yarn.sh
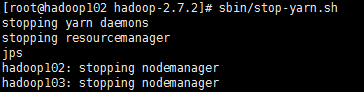
集群启动/停止方式
说了这么多总结一下启动方式:
(1)各个服务组件逐一启动/停止(集群某个进程挂掉使用这种方式重启 ,还是有一点点好处)
a)分别启动/停止hdfs组件
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
b)启动/停止yarn
yarn-daemon.sh start|stop resourcemanager|nodemanager
(2)各个模块分开启动/停止(配置ssh是前提)常用的方式
a)整体启动/停止hdfs(在namenode节点启动)
start-dfs.sh
stop-dfs.sh
b)整体启动/停止yarn (在resourcemanager节点启动)
start-yarn.sh
stop-yarn.sh
集群测试
刚好重头到尾顺一下,看看有哪些不了解的,再回去看一下
(1)启动集群
a)如果集群是第一次启动,需要格式化NameNode,如果单点启动的时候已经格式化,就不需要再次进行格式化了!!!
[root@hadoop101 hadoop-2.7.2]# bin/hdfs namenode -format
b)启动HDFS:
[root@hadoop101 hadoop-2.7.2]# sbin/start-dfs.sh
[root@hadoop101 hadoop-2.7.2]# jps
4166 NameNode
4482 Jps
4263 DataNode
[root@hadoop101 hadoop-2.7.2]# jps
3218 DataNode
3288 Jps
[root@hadoop101 hadoop-2.7.2]# jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
启动成功之后查看hdfs的页面:http://192.168.1.101:50070/
c)启动yarn
[root@hadoop102 hadoop-2.7.2]# sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。如果不在一台机器上,则ResourceManger所在机器也需要配置到其他机器的ssh免密登录。
通过jps命令查看进程:

Yarn的web页面查看地址:http://hadoop102:8088/
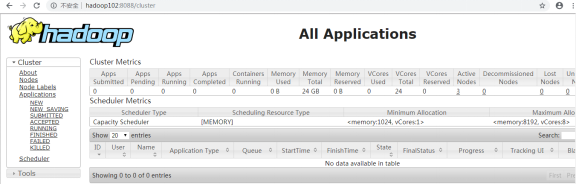
d)web端查看SecondaryNameNode
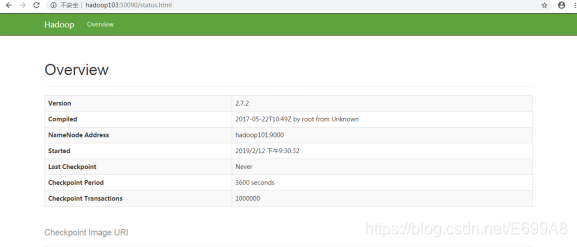
i.浏览器中输入:http://hadoop103:50090/status.html
ii.查看SecondaryNameNode信息,如图所示:
SecondaryNameNode的web端
2)集群基本测试
以上都应该挺熟悉了吧,下面试试上传文件
a)上传文件到集群
上传小文件 file system ,这个目录去哪里找呢?
[root@hadoop101 hadoop-2.7.2]# hadoop fs -mkdir /user
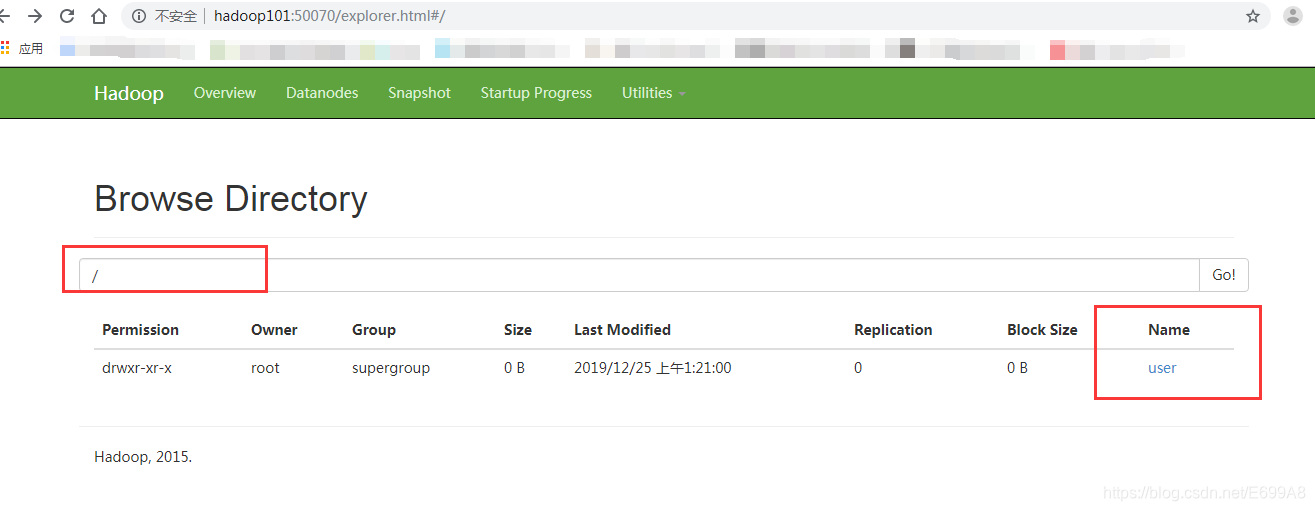
这里创建的可不是本地的user是在分布式文件系统创建的,它们不是一回事,
多级目录(加-p):
[root@hadoop101 hadoop-2.7.2]# hadoop fs -mkdir -p /aaa/bbb
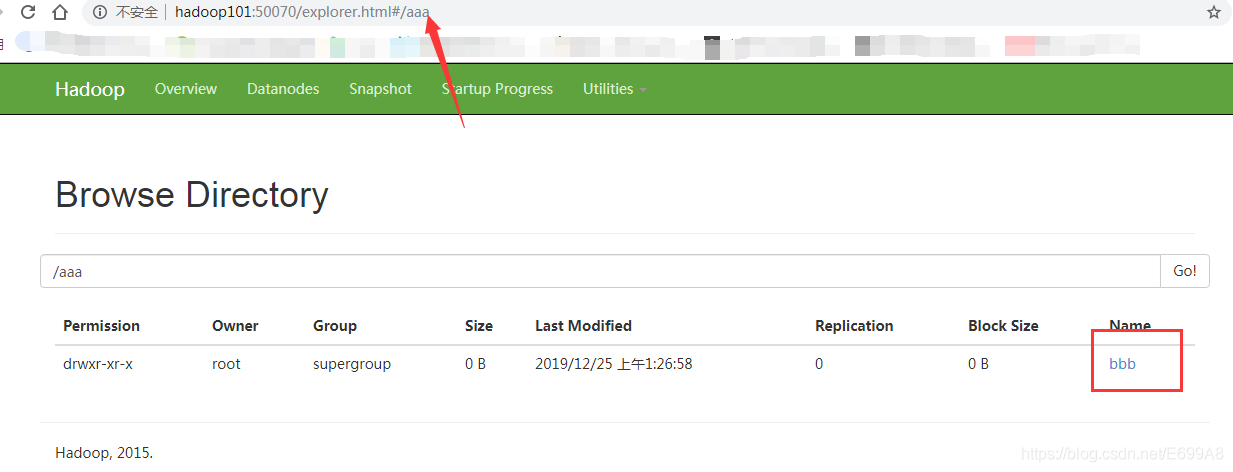
上传文件:
[root@hadoop101 hadoop-2.7.2]# hadoop fs -put README.txt /user
user不是系统的
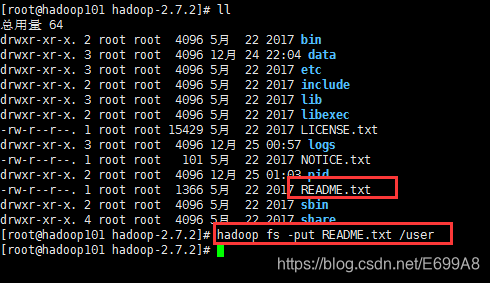
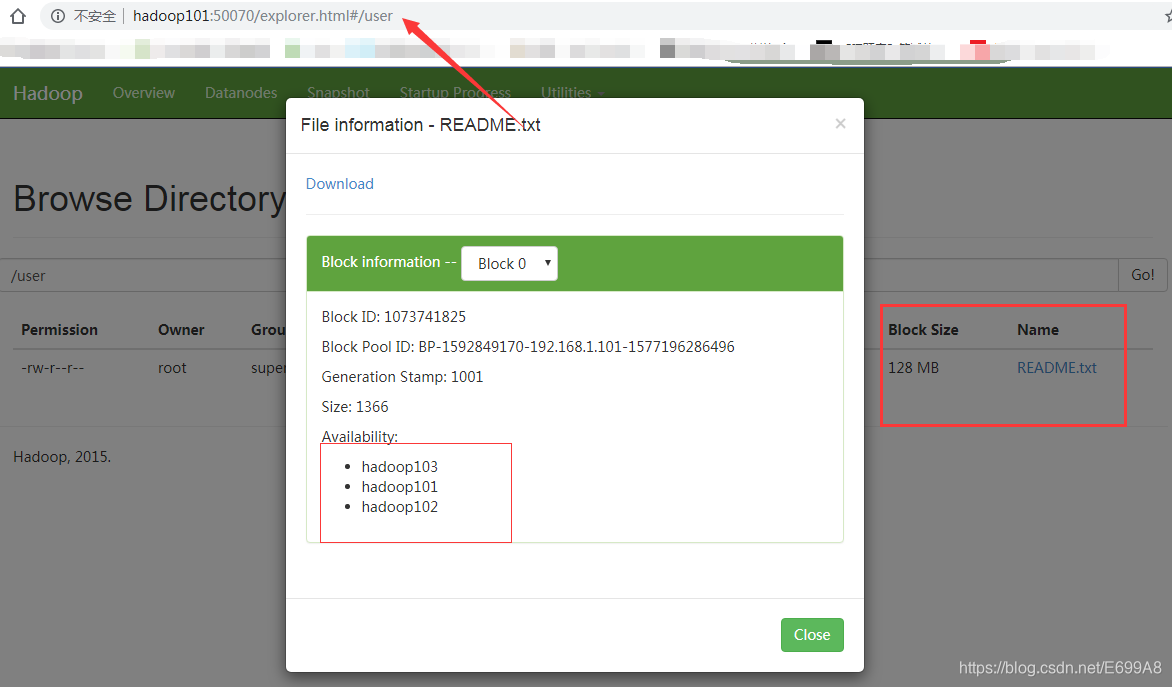
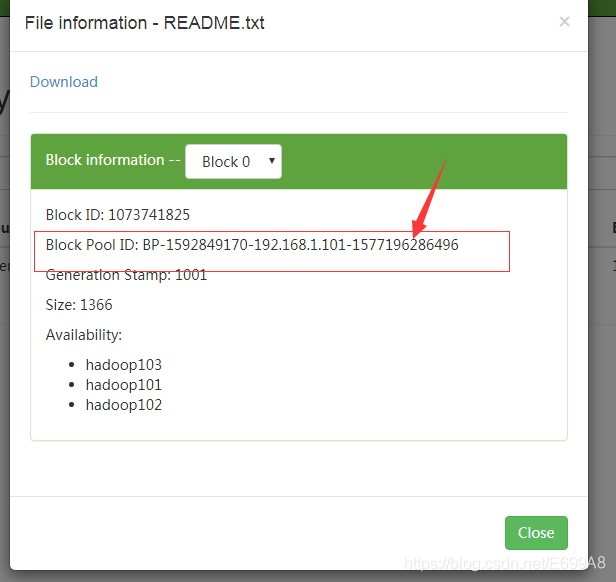
就和设置一样保存三个副本。

当时指定了文件存储位置可以看一下,在不在。
[root@hadoop101 hadoop-2.7.2]# cd data
[root@hadoop101 data]# ll
总用量 4
drwxr-xr-x. 4 root root 4096 12月 25 00:57 tmp
[root@hadoop101 data]# cd tmp
[root@hadoop101 tmp]# ll
总用量 8
drwxr-xr-x. 4 root root 4096 12月 24 22:10 dfs
drwxr-xr-x. 5 root root 4096 12月 25 01:03 nm-local-dir
[root@hadoop101 tmp]# cd dfs
[root@hadoop101 dfs]# ll
总用量 8
drwx------. 3 root root 4096 12月 25 00:08 data
drwxr-xr-x. 3 root root 4096 12月 25 00:08 name
[root@hadoop101 dfs]# cd data
[root@hadoop101 data]# ll
总用量 8
drwxr-xr-x. 3 root root 4096 12月 24 22:10 current
-rw-r--r--. 1 root root 14 12月 25 00:08 in_use.lock
[root@hadoop101 data]# cd current/
[root@hadoop101 current]# ll
总用量 8
drwx------. 4 root root 4096 12月 25 00:08 BP-1592849170-192.168.1.101-1577196286496
-rw-r--r--. 1 root root 229 12月 25 00:08 VERSION
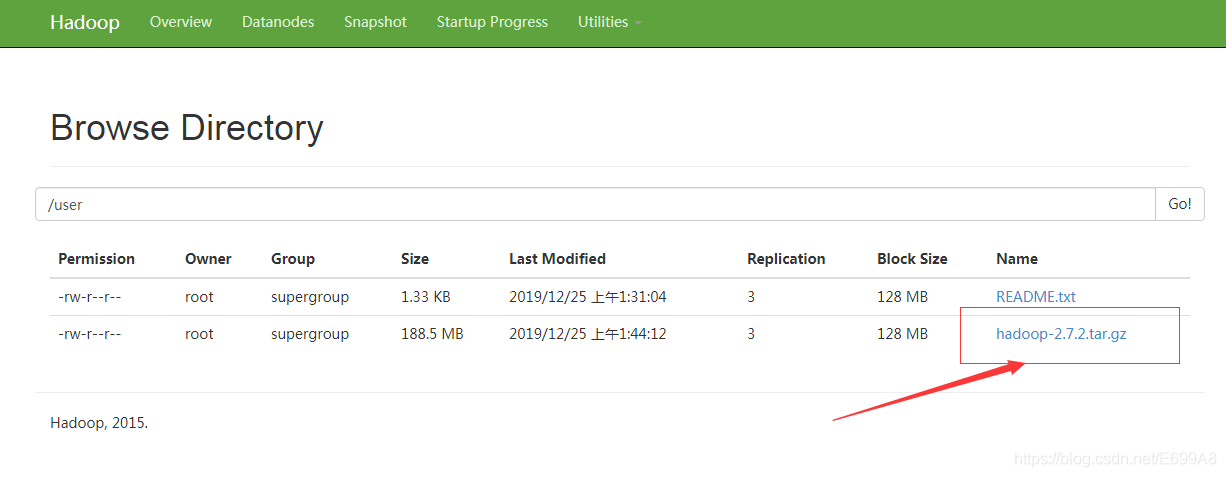
上传大文件
[root@hadoop101 ~]# cd /opt/software/
[root@hadoop101 software]# ll
总用量 374200
-rw-r--r--. 1 root root 197657687 12月 24 18:37 hadoop-2.7.2.tar.gz
-rw-r--r--. 1 root root 185515842 12月 23 20:01 jdk-8u144-linux-x64.tar.gz
[root@hadoop101 software]# hadoop fs -put hadoop-2.7.2.tar.gz /user
根据文件大小会分成块,为了防止传输大文件出问题,整个破坏,所以能分成块,即便出问题能传多少是多少,下的时候可以同时下,会快很多,默认一个块是128MB。
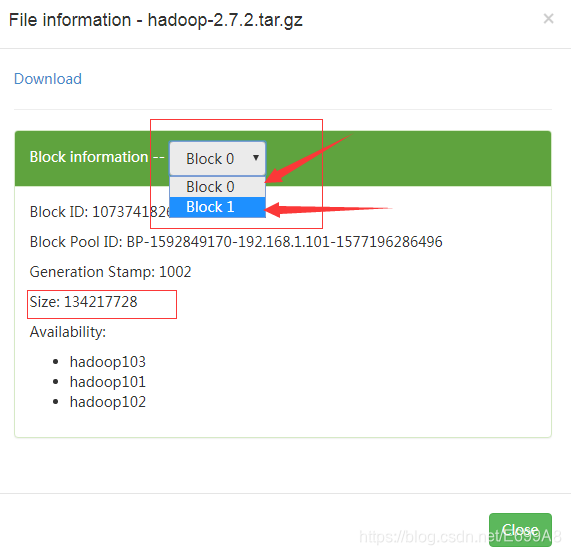
b)上传文件后查看文件存放在什么位置
查看HDFS文件存储路径
[root@hadoop101 subdir0]# pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-1592849170-192.168.1.101-1577196286496/current/finalized/subdir0/subdir0
[root@hadoop101 subdir0]# cd subdir0/
[root@hadoop101 subdir0]# ll
总用量 194552
-rw-r--r--. 1 root root 1366 12月 25 01:31 blk_1073741825
-rw-r--r--. 1 root root 19 12月 25 01:31 blk_1073741825_1001.meta
-rw-r--r--. 1 root root 134217728 12月 25 01:44 blk_1073741826
-rw-r--r--. 1 root root 1048583 12月 25 01:44 blk_1073741826_1002.meta
-rw-r--r--. 1 root root 63439959 12月 25 01:44 blk_1073741827
-rw-r--r--. 1 root root 495635 12月 25 01:44 blk_1073741827_1003.meta
c)拼接
[root@hadoop101 subdir0]# ll
总用量 325624
-rw-r--r--. 1 root root 1366 12月 25 01:31 blk_1073741825
-rw-r--r--. 1 root root 19 12月 25 01:31 blk_1073741825_1001.meta
-rw-r--r--. 1 root root 134217728 12月 25 01:44 blk_1073741826
-rw-r--r--. 1 root root 1048583 12月 25 01:44 blk_1073741826_1002.meta
-rw-r--r--. 1 root root 63439959 12月 25 01:44 blk_1073741827
-rw-r--r--. 1 root root 495635 12月 25 01:44 blk_1073741827_1003.meta
-rw-r--r--. 1 root root 134217728 12月 25 01:59 templ.tar.gz
[root@hadoop101 subdir0]# cat blk_1073741827 >> templ.tar.gz
[root@hadoop101 subdir0]# tar -zxvf templ.tar.gz
还原
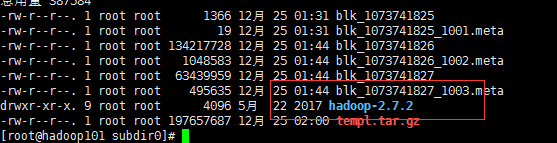
这里只是理解,实际并不需要我们关心这些,文件大的话可能会分成成百上千的块,分布各个机器上的,根本就不知道哪个是哪个了
集群时间同步
时间同步的方式:在集群中找一台机器,作为时间服务器,集群中其他机器与这台机器定时的同步时间,比如,每隔十分钟,同步一次时间。
配置时间同步实操:
(1)时间服务器配置(必须root用户)
a)检查ntp是否安装,若没有安装则使用yum install -y ntp进行安装
[root@hadoop101 桌面]# rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.6p5-10.el6.centos.x86_64
b)修改ntp配置文件
[root@hadoop101 桌面]# vim /etc/ntp.conf
修改内容如下
i.修改1(授权192.168.1.0网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
ii.修改2(集群在局域网中,不使用其他的网络时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
把#去掉就OK啦
iii.添加3(当该节点丢失网络连接,依然可以作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
加到文件最后
c)修改/etc/sysconfig/ntpd 文件
[root@hadoop101 桌面]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
d)重新启动ntpd
[root@hadoop101 桌面]# service ntpd status
ntpd 已停
[root@hadoop101 桌面]# service ntpd start
正在启动 ntpd: [确定]
e)执行:
[root@hadoop101 桌面]# chkconfig ntpd on
(2)其他机器配置(必须root用户,同时注意,将其它机器的ntp服务停掉 service ntpd stop chkconfig ntpd off)


一、在其他机器配置10分钟与时间服务器同步一次
[root@hadoop102 hadoop-2.7.2]# crontab -e
[root@hadoop103 hadoop-2.7.2]# crontab -e
编写脚本
*/10 * * * * /usr/sbin/ntpdate hadoop101
10代表十分钟
二、修改任意机器时间
[root@hadoop102 root]# date -s "2020-9-11 11:11:11"
三、十分钟后查看机器是否与时间服务器同步
[root@hadoop102 root]# date
可以设一分钟就好,只是测试。
结语
今天就先到这吧,看了看时间现在是,凌晨2.00了,回去睡觉了,今天圣诞节是吗还是平安夜什么的傻傻分不清,反正祝你们节日快乐吧!谢谢

















 3005
3005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









