




 本文介绍了机器学习的基本概念,包括监督学习和无监督学习,重点讲解了KNN、线性回归、逻辑回归、SVM、决策树、贝叶斯、随机森林和支持向量机等常见算法的工作原理及应用场景。并探讨了过拟合、欠拟合、正则化以及L1和L2正则化的区别。此外,还提到了特征工程、数据清洗、数据集扩增和机器学习评价指标AUC在实际应用中的重要性。
本文介绍了机器学习的基本概念,包括监督学习和无监督学习,重点讲解了KNN、线性回归、逻辑回归、SVM、决策树、贝叶斯、随机森林和支持向量机等常见算法的工作原理及应用场景。并探讨了过拟合、欠拟合、正则化以及L1和L2正则化的区别。此外,还提到了特征工程、数据清洗、数据集扩增和机器学习评价指标AUC在实际应用中的重要性。
机器学习
从广义上说,机器学习就是一种赋予机器自我学习的能力,从实践意义来说机器学习就是利用数据,使用机器计算出模型,然后通过模型来预测数据。
在机器学习的过程中最重要的就是数据,在alphago和李世石 的围棋比赛中,其中AlphaGo就是通过自己和自己下棋,总结数据,在经过千万局的数据经验后才和李世石达到了同等水平。机器学习又分为监督学习和无监督学习,监督学习就是将样本数据,和正确的结果告诉计算机,计算机通过学习这些数据后,总结规律;当给样本数据给计算机后,计算机就是通过自己模型将预测结果输出。无监督学习恰恰相反,只给计算机样本数据,没有给出正确的输出,让计算机自己总结其中的规律。
机器学习的算法主要有KNeighborClassifer、LinearRegression、Logistic、SVM、DecisionTree、贝叶斯、这些算法的原理不尽相同,但都是监督学习的范畴。
Kmeans无监督学习
K-近邻算法的理解
Knn 英语全拼是K nearest neighbor,k个最近的邻居,knn主要采用测量不同特征值之间的距离方法进行分类,主要使用数据的范围为数值型和标称型。
knn主要采用了欧几里得的距离计算公式,衡量多维空间中各个点的绝对距离xi-yi的平方和然后开根号。在knn算法中k也是起了关键的作用,假设k等于3,就将一个数据归类到了另一类,k等于5那么就将这个数据归类到另一类,其实knn的本质是基于数据统计的方法。再使用的时候需要导入knn的模块,创建knn对象,将数据交给knn进行训练,之后输入测试数据,knn返回预测结果。
线型回归LinearRegression
分类处理的数据大多数是离散预测,而对于连续的值类型的可以利用回归进行预测。
最小二乘法,通过最小化误差的平方寻找数据的最佳匹配。利用最小二乘法可以简单的求得未知的数据,并使得这些求得的数据和实际的数据之间误差的平方和最小。再线型回归中,正是对数据进行最小二乘法 的计算,对数据进行预测
w =(X.TX)^-1 X.Ty
过拟合,欠拟合、L2正则化、L1正则化、泛化能力????
过拟合 :模型把训练数据学的“太好了”,导致把数据中的潜在的噪声数据也学到了,测试时不能很好的识别数据,模型的泛化能力下降
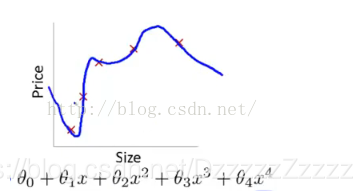
欠拟合:模型没有很好的捕捉到数据特征,不能够很好的拟合数据
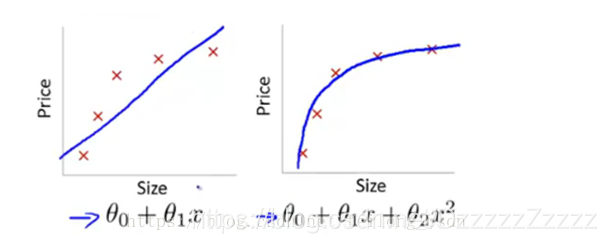
上左图:没有很好的拟合数据,出现欠拟合;上右图:很好的拟合了数据
正则化:正则化可防止模型过拟合,在训练中数据往往会存在噪声,当我们用模型去拟合带有噪声的数据时,通过假如正则化平衡模型复杂度和损失函数之间的关系,防止模型过拟合,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









