







一些网站 会将部分内容进行加密,防止爬虫简单的获取到信息
最近 在爬取58同城的品牌公寓时 遇到租房信息里的价格 爬下来是看不懂的字体
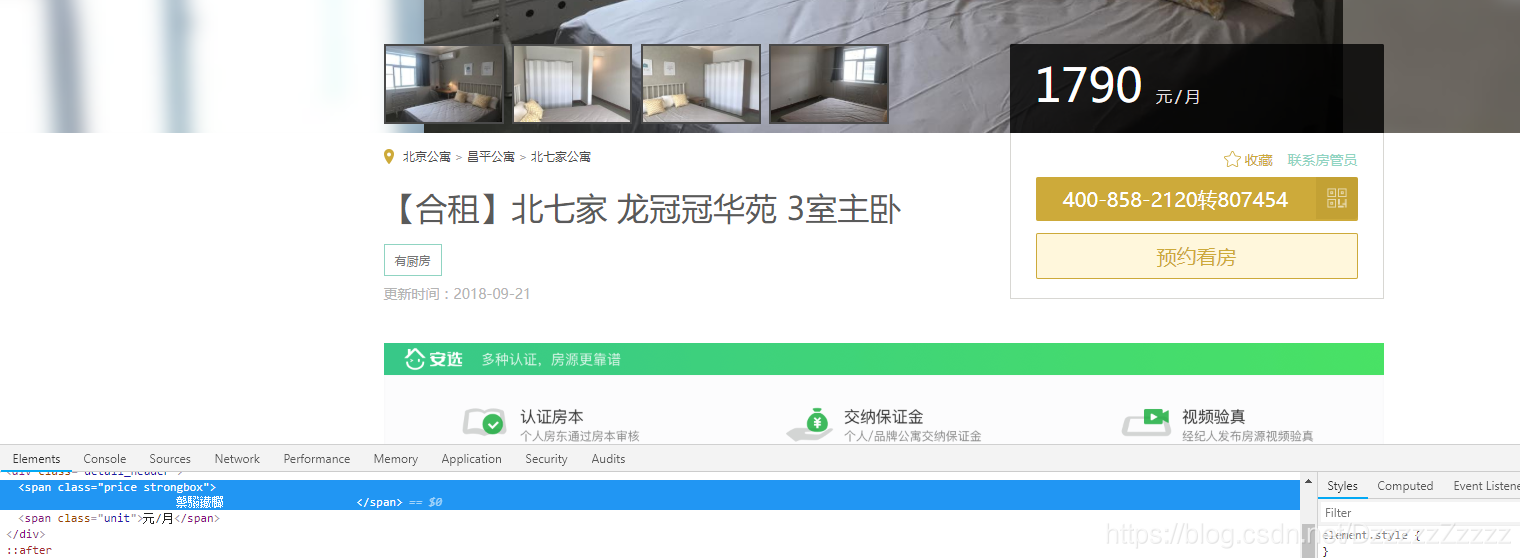
一些数据在浏览器里面显示是正常的, 但是渲染前和渲染后的html源码都看不到字体, 渲染前看到的是16进制的4位字符, 渲染后看到的是一些方块.
然后分析了一下网站的源码,发现他是由base64 加密之后生成的字体

那我们就可以通过正则匹配出来进行处理
首先在html源码里面找到woff字体的base4编码, 保存成”font.woff”字体文件, 用fontTools库将这个字体文件存储为”font.xml”文件.


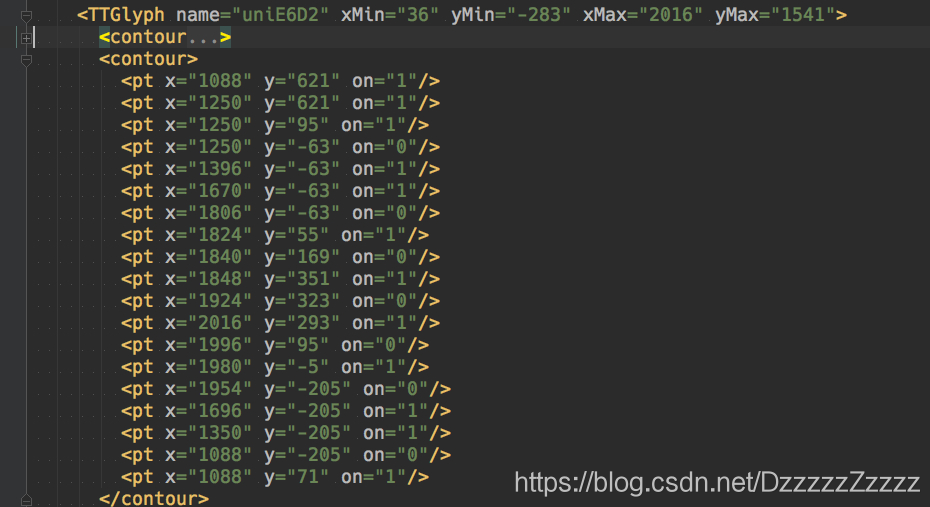
然后在xml里面找到TTGlyph字段, 这个字段下面的 子字段都是用来画字符(包括中英文数字)的坐标. 同一个字符的坐标是一样的. 解析xml, 然后把这些坐标的属性字典按顺序都存到一个list里面, 然后序列化成json(加sort_keys=True参数)字符串. 用这个字符串当key
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2436
2436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









