




 在CentOS7环境下,使用Hadoop3.3.14.0.0-alpha-2构建的高可用集群中,遇到Hive分区表修改不更新HDFS对应目录的问题。具体表现为ALTER TABLE命令重命名分区后,HDFS上的文件系统并未反映出变更,而删除和移动分区则能正确反映在HDFS上。这可能涉及到Hive元数据与HDFS数据同步的机制。
在CentOS7环境下,使用Hadoop3.3.14.0.0-alpha-2构建的高可用集群中,遇到Hive分区表修改不更新HDFS对应目录的问题。具体表现为ALTER TABLE命令重命名分区后,HDFS上的文件系统并未反映出变更,而删除和移动分区则能正确反映在HDFS上。这可能涉及到Hive元数据与HDFS数据同步的机制。
在Hive学习过程中碰到以下疑惑,求解答
配置:centos7 高可用集群Hadoop 3.3.1 4.0.0-alpha-2
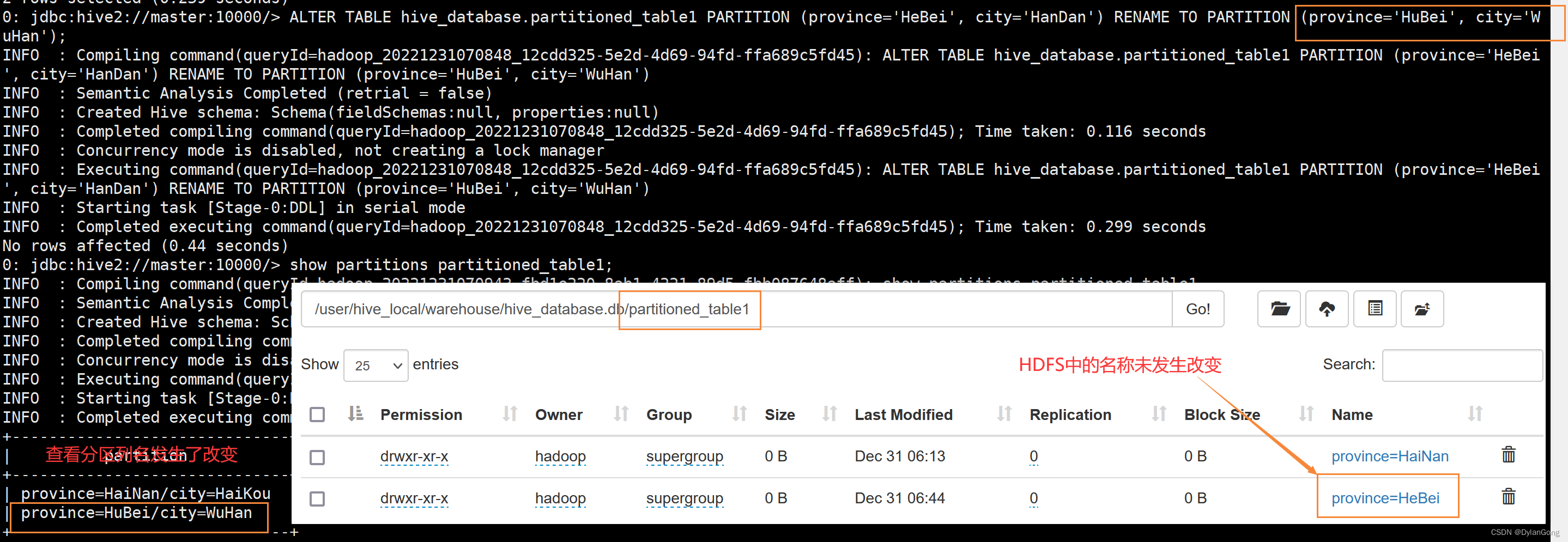
问题:在修改分区表的分区列时,HDFS文件系统中相应的目录没有发生变化 。但分区的删除和移动是能在HDFS文件系统中看到变化 。
ALTER TABLE hive_database.partitioned_table1 PARTITION (province='HeBei', city='HanDan') RENAME TO PARTITION (province='HuBei', city='WuHan');

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









