 堆排序与正则表达式
堆排序与正则表达式




堆排序Heap Sort
- 是利用堆性质的一种选择排序,在堆顶选出极值
- 时间复杂度为O(nlogn)
- 空间复杂度为O(1)
- 不稳定的排序算法
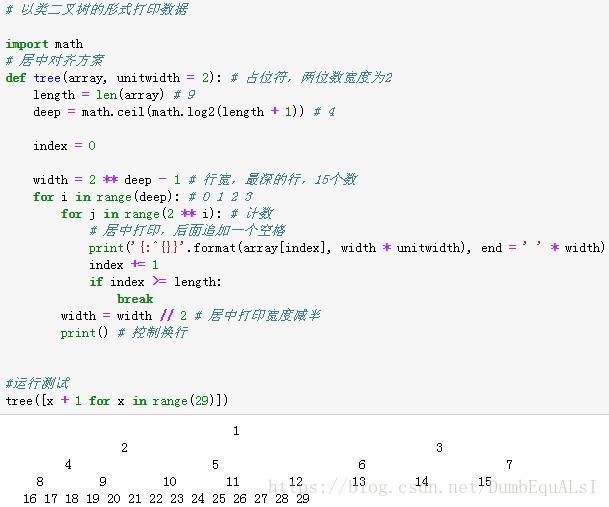
以类二叉树的形式打印数据
- origin=[30,20,80,40,50,10,60,70,90] # 数据存在列表中,打印一棵类二叉树
正则表达式
- Regular Expression,(regex、regexp、RE),文本处理技术,对字符串按照某种规则检索、替换
- 分类
- BRE:基本正则表达式
- ERE:扩展正则表达式
- PCRE:方言变种衍生出多数高级语言;Python模块:re
基本语法
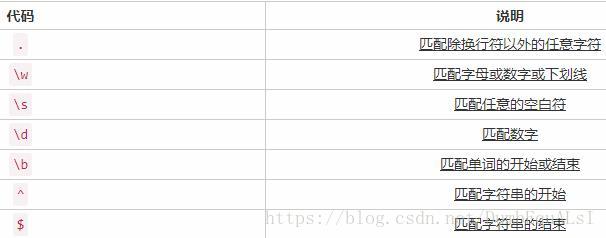
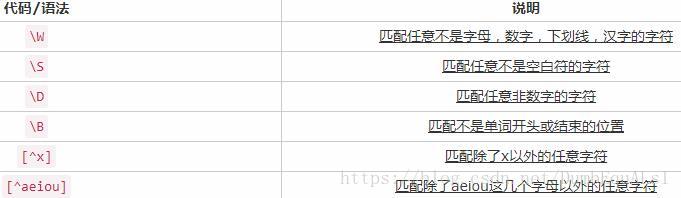
- 元字符metacharacter

默认为贪婪模式,尽多匹配字符串
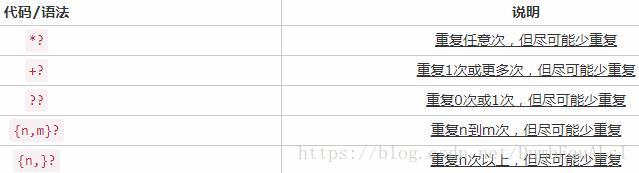
?为非贪婪模式,尽少匹配字符串
引擎选项
- IgnoreCase:匹配时忽略大小写
语法:
re.ISingleline:单行模式。匹配所有字符包括
\n语法:
re.SMultiline:多行模式。
^行首,$行尾语法:
re.MIgnorePatternWhitespace:忽略表达式中的空白字符,使用空白字符需要转义。
#以作注释- 语法:
re.X
多种选项
|位或运算开启
方法
编译
re.compile(pattern,flags=0)单次匹配
- 从字符串开头匹配,regex可设定起止位置。返回match对象
re.match(pattern,string,flags=0)regex.match(string,[pos[,endpos]])- 从开始位置搜索,直到第一个匹配,regex可设定起止位置。返回match对象
re.search(pattern,string,flags=0)regex.search(string,[pos[,endpos]])- 整个字符串和正则表达式完全匹配
re.fullmatch(pattern,string,flags=0)regex.fullmatch(string,[pos[,endpos]])- 全文搜索
- 对整个字符串从左至右匹配,返回所有匹配项的列表
re.findall(pattern,string,flags=0)regex.findall(string,[pos[,endpos]])- 对整个字符串从左至右匹配,返回所有匹配项,返回迭代器
re.finditer(pattern,string,flags=0)regex.finditer(string,[pos[,endpos]])- 匹配替换
- 使用pattern对string进行匹配,对匹配项使用repl替换;replacement可以是string、bytes、function;count指定替换次数,count=0即全部替换
re.sub(pattern,replacement,string,count=0,flags=0)regex.sub(replacement,string,count=0)- 同sub,返回一个元组(new_string,number_of_subs_made)
re.subn(pattern,replacement,string,count=0,flags=0)regex.subn(replacement,string,count=0)- 分割字符串
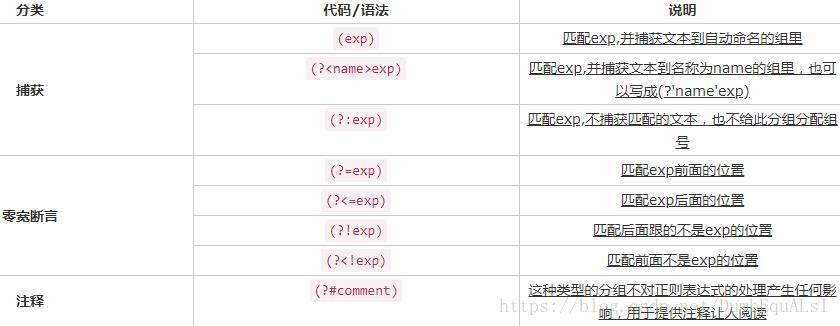
re.split(pattern,string,maxsplit=0,flags=0)- 分组
- 使用小括号的pattern捕获的数据放置于组group中
- 使用group(N)返回对应分组,0返回整个匹配的字符串
- 命名分组后可用group(‘name’)取分组
- 使用groupdict()返回所有命名的分组
匹配合法的IP地址

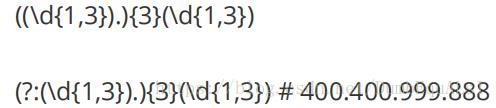

















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









