







Accelerating Neural Architecture Search via Proxy Data
利用代理数据加速神经网络结构搜索

摘要
尽管人们对神经结构搜索(NAS)越来越感兴趣,但NAS的巨大计算成本仍然是研究人员的一大障碍。因此,我们建议使用代理数据来降低NAS的成本,即。E在不牺牲搜索性能的情况下,目标数据的代表子集。尽管数据选择已在各个领域使用,但我们对NAS-BECH1SHOT1提供的NAS算法的现有选择方法的评估表明,这些方法并不总是适用于NAS,因此有必要采用新的选择方法。通过对各种选择方法构造的代理数据进行数据熵分析,提出了一种适合NAS的代理数据选择方法。为了从经验上证明其有效性,我们对不同的数据集、搜索空间和NAS算法进行了彻底的实验。因此,具有所提出选择的NAS算法发现的体系结构与使用整个数据集获得的体系结构具有竞争力。它显著降低了搜索成本:在CIFAR-10和CIFAR-7上使用建议的选择执行DART只需要40分钟。使用单个GPU在ImageNet上运行5小时。此外,当使用建议的选择在ImageNet上搜索的架构反向转移到CIFAR-10时,最先进的测试误差为2。产量为4%。我们的代码可在https://github.com/nabk89/NAS和代理数据。
一:介绍
神经体系结构搜索(NAS)是自动机器学习中研究最广泛的领域之一,旨在降低设计和测试数百种神经体系结构的人力成本。然而,在与NAS相关的早期研究中[Zoph和Le,2017;Zophet al.,2018;Realet al.,2019],出现了巨大的计算开销,因此需要大量计算资源来执行搜索算法。为了降低搜索成本,最新开发的NAS算法在超级计算机上采用权重共享优化超级网络中架构参数的网络和/或可微方法[Xieet al.,2020]。这些技术使得对候选神经结构性能的评估更接近,但速度更快,从而显著降低NAS的成本。
在本研究中,我们通过合并代理数据进一步降低了NAS的搜索成本,即。E目标数据的代表子集。数据选择广泛应用于深度学习的各个领域,如主动学习[Settles,2009;Coleman等人,2020]和课程学习[Graves等人,2017;Changet等人,2017]。例如,在给定训练模型的情况下,主动学习中使用的核心集选择方法旨在从大型未标记数据集中选择训练数据,以最小的标记成本标记所选数据,从而有效降低计算成本。但是,还没有关于NAS数据选择问题的全面研究。为NAS开发合适的选择非常重要,因为NAS算法可以从搜索成本的显著降低中获益。
我们首先在NAS-Bench-1shot1上评估使用五种现有数据选择方法构建的代理数据[Zelaet al.,2020b]。虽然实质性结果为我们的假设提供了有力的实证支持,但它们也揭示了一种新的、改进的选择方法的必要性,该方法专门为NAS设计。随后,我们基于代理数据中示例的熵[Shannon,1948]分析了不同选择方法的搜索性能和属性之间的关系。基于我们的分析,确定了一种选择方法的特征,该方法使代理数据能够有效地保持NAS算法的搜索性能。当选择方法主要选择低熵示例时,即使代理数据的大小很小,也会发现结果代理数据具有竞争性的体系结构。为了实现使用整个数据获得的搜索性能,在代理数据中包含额外的高熵示例非常重要。
基于这些观察结果,我们提出了一种新的选择方法,该方法优先选择数据熵分布尾部的示例。选择方法可以以确定性或概率的方式实现。对于前者,我们采用低熵和高熵两种情况下的例子,以便选择熵分布两端的例子。对于概率方式,我们建议三种满足已识别特征的抽样概率-代理数据的特性对NAS有效。我们使用NAS-Bench-1shot1演示了所建议的选择相对于现有选择的优越性,并表明即使仅使用NAS-Bench-1shot1,搜索性能也得以保持。从CIFAR-10中选择5K个培训示例。
我们进一步证明,所提出的选择方法可以普遍应用于各种可微NAS算法和四个图像分类基准数据集。具有所提议选择的NAS算法在显著缩短搜索时间的情况下发现竞争性神经结构。例如,使用我们的选择方法执行DART[Liu等人,2019]只需要在单个GeForce RTX 2080ti GPU上使用40 GPU分钟。由于搜索成本的降低,ImageNet上的搜索可以在7分钟内完成。当将建议的选择纳入DART时,单个特斯拉V100 GPU的5个GPU小时。搜索到的架构实现了24的top-1测试错误。6%,超过了体系结构的性能,该体系结构由CIFAR-10上的DART发现,然后传输到ImageNet。此外,在CIFAR-10上对该体系结构进行评估时,其测试误差达到2。4%,在最新的NAS算法中,展示了CIFAR-10最先进的性能。这表明NAS算法使用从大规模数据集中选择的代理数据发现的体系结构可以高度转移到较小的数据集。
总而言之,我们的主要贡献如下:•我们提供了在NAS-Bench-1shot1上进行的大量实验结果,以证明现有选择不适合NAS。•通过识别有效的代理数据选择方法的特点,我们提出了一种新的选择方法和两种实现方法我们展示了所提出的NAS选择的有效性及其对各种NAS算法和数据集的普遍适用性。我们预计NAS领域将从使用建议的代理数据选择所带来的搜索成本的降低中获益匪浅。
二:相关工作
2.1 Neural Architecture Search
最近,NAS方法已显著多样化,因为已开发出更复杂的算法以实现更高的性能或更低的搜索成本[Xieet al.,2020]。在此,我们讨论的研究重点是降低搜索成本。为了降低搜索成本,大多数差异化和一次性NAS方法在基于单元的搜索空间上采用了权重共享[Phamet al.,2018]或具有混合权重的连续架构Liupet al.,2019。在搜索过程中,将训练一个超级网络,该超级网络堆叠多个单元,但比目标网络小。
为了进一步降低成本,PC-DARTS[Xuet al.,2020]通过在快捷方式中部分绕过通道,减少了搜索过程中使用的单元格中可训练重量参数的数量。EcoNAS[Zhouas等人,2020]提出了四个缩减因子,使得网络比传统的基于小区的NAS算法的超级网络小得多,并提出了一种基于分层进化算法的搜索策略,以提高使用较小超级网络的架构性能估计的准确性。关于数据选择,EcoNAS使用从CIFAR-10随机抽样的子集简要报告了搜索结果。在这项研究中,我们评估了各种选择方法,包括随机选择,并对适合NAS的选择方法提供了有意义的见解。
NAS算法缺乏再现性,因此,公平比较NAS算法具有挑战性。NAS基准[Yinget al.,2019;Zelaet al.,2020b;Dong and Y ang,2020;Dong et al.,2020]旨在缓解NAS研究中的这一问题。因为这些基准提供了架构数据库和易于实现的NAS算法平台,所以可以省略重新训练搜索的架构以进行评估。因此,在本研究中,我们使用了两个基准,即。ENAS-Bench-1shot1[Zelaet al.,2020b]和NA TS Bench[Dong等人,2020],研究构建有效代理数据的选择方法,并评估我们的代理数据选择方法。
2.2 Data Selection in Deep Learning
数据选择或二次抽样是深度学习中一种成熟的方法,广泛应用于深度学习的各个领域。主动学习[Settles,2009;Sener和Savarese,2018;Beluchet等人,2018;Colemanet等人,2020]采用核心集选择,通过从大型未标记数据集中选择尽可能少的示例来降低标记成本。作为一种应用,核心集选择方法可用于减少训练生成性对抗网络的批量[Sinhaet al.,2020]。在课程学习[Graves等人,2017;Changet等人,2017]中,示例被有效地输入到神经网络中,以避免灾难性遗忘并加速训练;因此,课程学习最终将利用整个数据集,而不是一个子集。然而,我们的结果表明,现有的选择方法并不总是适用于NAS;因此,需要专门针对NAS的新选择方法。
三:Exploration Study
在本研究中,我们使用使用现有选择方法构建的不同代理数据,广泛评估NAS-Bench-1shot1提供的NAS算法的搜索性能。根据获得的结果,我们确定了产生NAS特别有效的代理数据的选择方法的特征
3.1 Exploration Setting
NAS-Bench-1shot1用作主要测试平台,以观察代理数据对CIFAR-10上三种NAS算法搜索性能的影响:DARTS[Liu等人,2019]、ENAS[Phamet等人,2018]和GDAS[Dong和Y ang,2019]。为了构建sizek的代理数据,使用选择方法从CIFAR-10的50K个训练示例中选择示例。所选示例分为两部分:一部分用于更新权重参数,另一部分用于更新架构参数。对于公平地比较,所有经过测试的NAS算法都使用了NAS-Bench-1shot1中提供的相同超参数设置。为了避免樱桃采摘结果,我们对不同的种子执行五次搜索过程,并报告平均性能
本研究中使用的五种选择方法是:随机、熵top-k、熵bottom-k、遗忘事件和k-中心。在此,我们对每种选择方法进行简要说明;更多细节见附录。顾名思义,随机选择会对示例进行统一采样。对于基于熵的选择[Settles,2009],我们使用熵值Fentropyof Example计算如下:
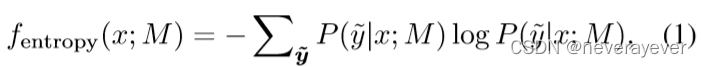

其中,y=M(x)是x相对于预先训练的基线模型M,i的预测分布。Esoftmax在分类器中的输入。熵top kselection选择具有top kentropy的示例,熵底部kselection执行相反的操作。对于遗忘事件选择[Toneva等人,2019],我们从头开始训练模型,并监控每个示例中被称为遗忘事件的错误分类数量。训练模型后,选择遗忘事件数在前几位的例子。在K中心选择[Sener和Savarese,2018]中,给定从所有示例的预训练模型中提取的特征向量,通过greedyk中心算法选择示例。我们出发了∈ {1.5,2.5,5,10,15}K,以及列车前ResNet-20[Sheet al.,2016]的选择方法;预训练模型的测试精度为91。7%. 使用这五个选项构造的代理数据相应地由drandom、Dtop、Dbottom、Dforget和dcenter表示。
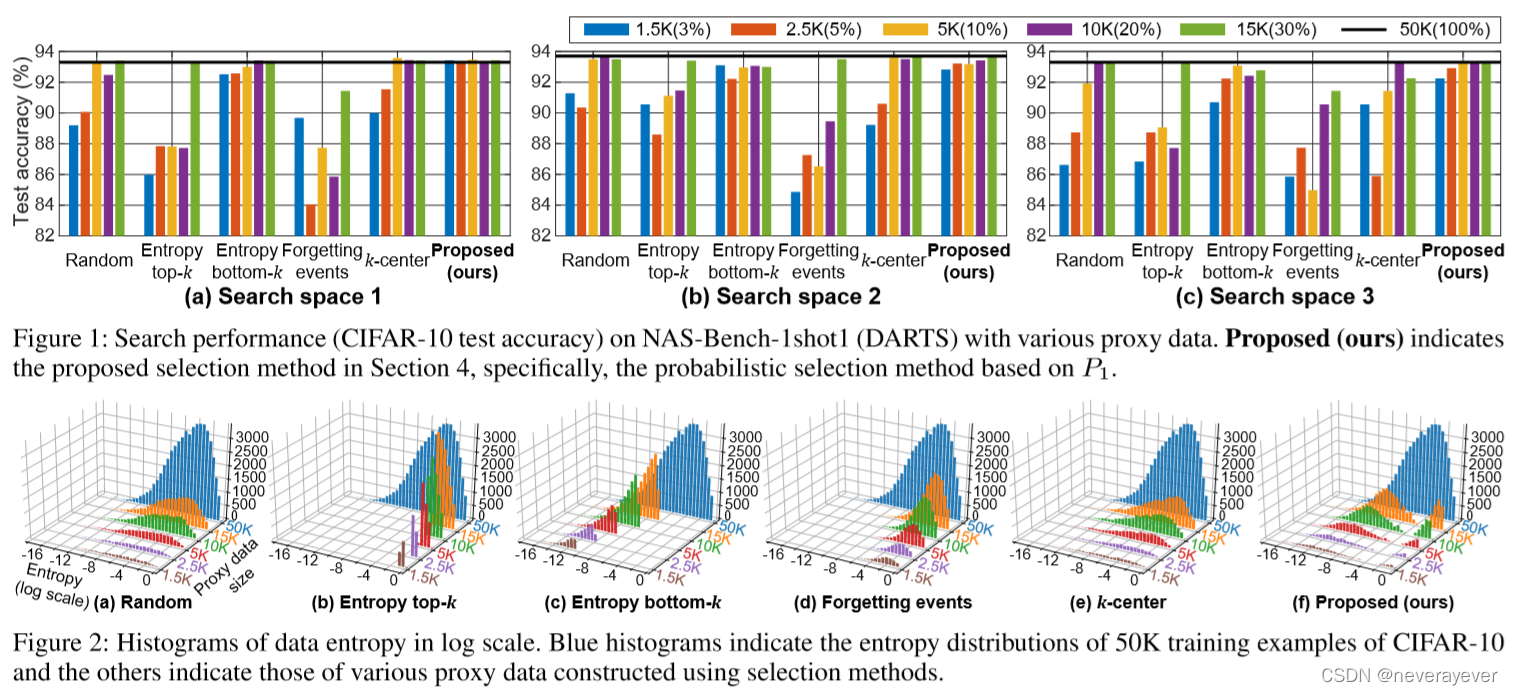
图1:NAS-Bench-1shot1(DART)上具有各种代理数据的搜索性能(CIFAR-10测试精度)。建议(我们的)表示第4节中建议的选择方法,特别是基于P1的概率选择方法。
图2:对数尺度下的数据熵直方图。蓝色直方图表示CIFAR-10的50K训练示例的熵分布,其他直方图表示使用选择方法构造的各种代理数据的熵分布。
3.2 Observations and Analysis
DART的搜索结果如图1所示,ENAS和GDAS的搜索结果如附录所示。如果问变化,观察到两个有趣的现象。首先,对于k≤2.5K示例中,使用DBottom搜索时,搜索性能始终接近使用整个数据的DART,即原始性能。第二,Askin增加到5K以上,使用大多数代理数据进行搜索会导致搜索性能的快速提高;然而,在DBottom的情况下,改进不太明显,并且很难实现最初的性能。

我们分析不同的代理数据,利用数据熵,,找出对搜索性能有影响的最重要的因素。数据熵是用于量化示例难度的典型度量;此外,在本研究中,它被用作代理数据的定义属性。图2显示了对数尺度下所有代理数据的数据熵直方图。

如图2(a)-(e)所示,数据的组成与其他代理数据的组成有显著差异。当k≤2.5K,Dbottom,它实现了比其他代理数据更具竞争力的搜索性能,包含了大量简单的示例。它建议使用一些简单的示例构造代理数据,这对于最小化代理数据的大小和获得原始搜索性能是有效的。同时,Drandom(orDcenter)逐渐包括简单、中等和困难的示例,大多数附加示例(orDtop)都是困难的。结果表明,Nas与Proxydata(适当地包括中等和困难的示例)一起,可以在足够大的范围内实现原始搜索性能;每个选择的KDiffers的适当值。综合而言,根据观察到的搜索性能相关性和代理数据的组成,我们推断NAS的选择方法满足以下特征:
•当选择少量示例时,简单的示例比困难的示例更有可能发现相对有竞争力的体系结构
当已经选择了简单示例时,添加中间示例和困难示例可以实现原始搜索性能
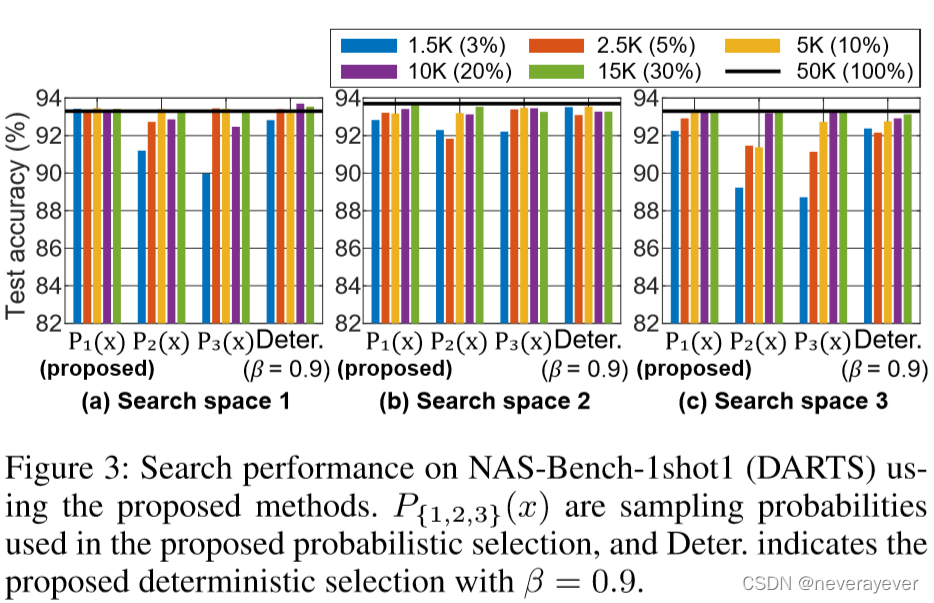
图3:使用建议的方法在NAS-Bench-1shot1(DART)上的搜索性能。P{1,2,3}(x)是在建议的概率选择中使用的抽样概率,并确定。表示建议的确定性选择,β=0。9
四:拟议的选择方法
图1显示了使用现有选择方法获得的最小有效代理数据的大小为5K。虽然随机选择可能被认为是一种强基线选择方法,但当≤2.5公里。此外,值得注意的是,D底部带有K≤2.5K比其他代理数据具有更好的搜索性能。因此,为了进一步最小化代理数据的大小,我们提出了一种新的选择方法,该方法对数据熵中属于双侧尾分布的示例进行加权。直观地说,与其他中间示例相比,较难的示例的增加为NAS提供了更多的信息。如图1所示,K=15K的底部结果支持这一点,其中包括大量简单示例和少量中间示例。

在此,我们建议两种方法来实现所提出的选择方法:确定性方法和概率性方法。对于确定性选择,我们采用低熵示例的合成比参数β。关于数据熵,底部-β样本和顶部-(1−β) 选择样本,其中0<β<1。对于概率选择,示例的概率分布应设计为满足上述两个特征。利用直方图信息(可通过预先训练的基线模型获得),我们设计并评估三种概率,分别用P1、P2和P3表示,用于概率选择。设一个箱子,其中examplexbelongs在数据熵histogramH中,而| hx |表示高度hx,i。Einhx中的示例数。三种概率的定义如下:
P{1,2,3}(x;H)=范数(W{1,2,3}(hx;H)/| hx |),其中范数()规范化内部项,使得P x∈DP{1,2,3}(x;H)=1用于目标数据D。在内部项中,由w{1,2,3}(hx;H)表示的选择权重定义如下:
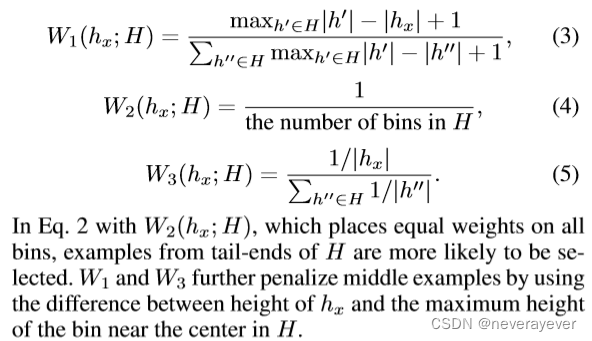
在等式2中,W2(hx;H)在所有料仓上放置相等的重量,更可能选择来自料仓尾部的示例。W1和W3使用X的高度和靠近中心inH的料仓的最大高度之间的差值进一步惩罚中间示例。

为了对NAS-Bench-1shot1进行评估,我们使用10种不同的种子执行建议的选择。在β={0.9,0.8,0.7,0.6,0.5}的确定性选择中,β=0的搜索性能。9是最好的;其他结果见附录。对于概率选择,我们基于CIFAR10的数据熵直方图(图2中的蓝色直方图)对| hx |进行量化。图2(f)显示了所选示例的熵分布。
如图3所示,在这些选择中,β=0的确定性选择。9和基于P1(x;H)的概率选择实现了最佳搜索性能。特别是,在搜索空间1中,基于P1(x;H)的概率选择仅在k=1时达到原始性能。5千个例子。尽管β=0的确定性选择。9也能实现竞争性的性能,找到最佳β是非常重要的,因为最佳β可以依赖于目标数据或预先训练的基线模型。相比之下,概率选择不需要额外的超参数;因此,选择代理数据时不需要进行详尽的超参数搜索。因此,我们将基于P1(x;H)的概率选择作为本研究剩余部分的主要方法。
如图1所示,与其他现有选择相比,建议的代理数据选择显示了更好的搜索性能。我们在附录中包括了对NA TS台架的评估结果[Dong等人,2020],其中的结果还表明我们的方法在NA TS台架提供的NAS算法上是有效的。在第5节中,我们进一步证明了其在扩大的基于单元的搜索空间[Liuet等人,2019]和各种NAS算法上的有效性。
4.1关于拟议选择的效力的讨论
在本节中,将讨论影响推荐选择方法(尤其是NAS)有效性的因素。许多不同的NAS算法专注于训练超级网络[Xieet al.,2020]。当一个超级网络被训练成只适合较简单的例子时,它自然会比尝试适合较难的例子时收敛得更快。这种现象的副作用是,只有经过几次培训后,损失梯度才会变小[Changet al.,2017],因此不会再反向传播超级网络的有用信号。因此,当从这样的超级网络导出体系结构时,生成的体系结构很可能对困难的示例具有有限的泛化能力。使用困难的例子可以让超级网络学习到更多有意义的信息,而这些信息很难从简单的例子中获得。利用t-SNE[Maaten和Hinton,2008]对不同代理数据的可视化,我们可以推测,来自简单示例的缺失信息与从预先训练的网络和数据集获得的决策边界有关。如第4节所述,我们使用ResNet-20从CIFAR-10的不同代理数据中提取特征;附录中显示了相应的t-SNE可视化结果。与困难的例子不同,简单的例子往往远离决策边界。因此,对于一个超级网络来说,要学习这样的决策边界,就需要具有困难示例的代理数据。同时,如果代理数据主要由困难的示例组成,则超级网络的稳定训练可能会受到阻碍,这与图1中的结果一致。这个问题可以通过使用足够数量的简单示例来解决。因此,满足第3节中确定的特征的建议选择方法产生了一个超级网络,该超级网络类似于使用整个数据集训练的超级网络,同时代理数据的大小最小化
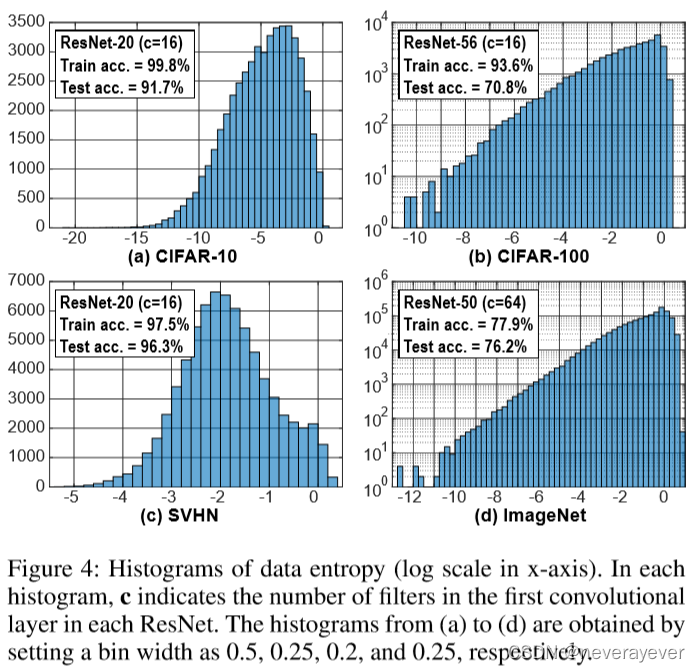
图4:数据熵直方图(x轴上的对数标度)。在每个直方图中,Cindicate每个ResNet中第一个卷积层中的过滤器数量。从(a)到(d)的直方图是通过将料仓宽度设置为0获得的。5, 0. 25, 0. 2和0。分别为25个。
五:实验和结果
我们使用Pytorch model zoo中预先训练好的ResNet-50进行ImageNet,并对三个模型进行了CIFAR10、CIFAR-100和SVHN的训练;培训花费了0。015, 0. 033和0。022 gpuday,其中附加成本可以忽略不计。我们使用图4中的对数比例数据熵直方图准备代理数据。尽管CIFAR-100和ImageNet的数据熵分布显示出与CIFAR-10和SVHN不同的模式,但我们的实验结果一致表明,与其他两个数据集一样,建议的代理数据选择对CIFAR-100和ImageNet是有效的。对于评估,我们使用了两种类型的GPU:特斯拉V100用于在ImageNet上搜索和训练神经架构,GeForce RTX 2080ti用于其余数据集。我们使用三种不同的种子执行搜索过程,并报告平均值。关于实验设置的更多细节见附录。
5.1与随机选择的比较
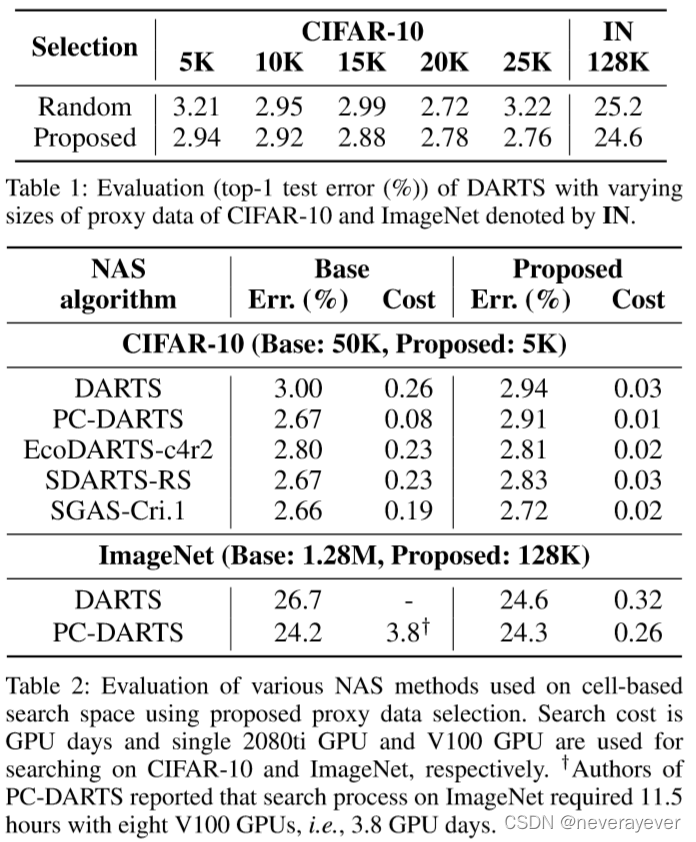
表2:使用建议的代理数据选择对基于单元的搜索空间上使用的各种NAS方法进行评估。搜索成本为GPU天,单个2080ti GPU和V100 GPU分别用于在CIFAR-10和ImageNet上搜索。†PC-DART的作者报告说,在ImageNet上的搜索过程需要11。5小时,8个V100 GPU,即。E3.8 GPU天。
根据第3节,显然随机选择是一种有效、合理的基线。因此,我们比较使用带有CIFAR10的DART在基于单元格的搜索空间中进行随机选择的建议选择[Liuat等人,2019];附录中包括第3节中评估的其他选择的搜索结果。我们将代理数据的大小从5K更改为25K;搜索成本随代理数据的大小成比例降低。如表1所示,在CIFAR-10上,使用所提出的方法进行搜索通常优于使用随机选择的方法。此外,随机选择的搜索性能随代理数据大小的变化而波动。用该方法从ImageNet中选取128K训练样本进行搜索,结果也优于随机选择
5.2 Applicability to NAS Algorithms
5.2对NAS算法的适用性
最近,提出了各种基于单元搜索空间的可微NAS算法[Xieet al.,2020]。我们将建议的代理数据选择应用于最近建议的NAS,即。EDARTS【Liuat等人,2019年】、PCDARTS【Xuet等人,2020年】、SDARTS【Chen和Xieh,2020年】、SGAS【Liet等人,2020年】和ECOARTS(ECOAS的基于DARTS的变体【Zhou等人,2020年】)。如表2所示,所有经过测试的NAS算法都达到了与其各自原始搜索性能相当的性能。在CIFAR-10上,具有建议选择的PC-DART的性能略有下降,而在ImageNet上,它成功地实现了原始搜索性能,大大降低了搜索成本。
除PC-DART外,现有NAS算法均未直接在ImageNet上搜索。为了在ImageNet上执行直接搜索,我们将建议的选择与PC-DART和DART结合起来。专业飞镖-Posite selection发现了比原始DART更好的体系结构,它将在CIFAR-10上搜索的体系结构传输到ImageNet。最初的PC-DART在ImageNet上搜索时使用了12。5%的示例是从数据集中随机抽样的。它需要3个。8 GPU天,i。E115小时,8个V100 GPU,批量大小为1024;我们推测,八个GPU上的并行执行导致了不可忽略的开销。相比之下,具有代理数据的PC-DART(由10%使用建议选择构建的示例组成)可以使用单个V100 GPU发现竞争性体系结构,批量大小为256,约为0。26 GPU天,i。E14成本比原PC-DART低6倍
DARTS with the pro-posed selection discovers a better architecture than the orig-inal DARTS
5.3 Applicability to Datasets
5.3对数据集的适用性
为了证明所提议的选择对数据集的普遍适用性,我们在四个不同的搜索空间中使用DART和ROBUSTDART[Zelaet al.,2020a]在CIFAR-10、CIFAR-100和SVHN上进行了测试。通过减少候选操作类型(S1-S3)和插入有害噪声操作(S4),从基于单元的搜索空间修改这些搜索空间;详情见附录。按照RobustDARTS中的实验协议,在搜索过程中,省道和RobustDARTS(L2)的权重衰减因子设置为0。0003和0。分别为0243。如表3所示,使用建议选择的两种NAS算法的大多数结果都在原始搜索性能的合理范围内。然而,当在S4上使用CIFAR-100中10%的示例执行DART时,会出现严重的搜索失败。导致此故障的原因是S4中的噪声操作在搜索后占据了单元结构中的大部分边缘。请注意,噪声操作旨在导致DART失效[Zelaet al.,2020a],通常不在实践中使用。然而,当使用20%的示例时,可以获得CIFAR-100上的原始搜索性能。
5.4逆转移性
通常,在大多数NAS算法中,使用CIFAR-10发现的体系结构的可转移性通过其在ImageNet上的性能来证明。在所提出的选择中使用省道,使用ImageNet搜索的计算成本减少了110,即。E026 GPU天。ImageNet代理数据上的搜索时间与整个CIFAR-10上其他NAS算法的搜索时间相似。因此,考虑到公平比较的相似搜索成本,使用建议的选择在ImageNet上发现的架构可以在CIFAR-10上进行评估,这与传统研究相反。因此,使用建议的选择在ImageNet上搜索的体系结构产生2的top-1测试误差。CIFAR-10的4%,i。E在基于小区的NAS算法中性能最好;附录中提供了最新NAS算法的结果。值得注意的是,我们没有利用最近研究中引入的其他技术,并且上述体系结构仅通过对大规模数据集的代理数据执行DART来发现。我们推测,与CIFAR-10相比,ImageNet的使用为省道提供了更有用的视觉表现。我们将这种将架构从大规模数据集转移到较小数据集的方法称为反向转移。我们的研究表明,如果大规模数据集上的搜索成本相当低,那么体系结构的逆向转换可以为NAS研究提供新的方向。
六:结论
在NAS研究中,我们首次引入代理数据来加速NAS算法,同时又不牺牲搜索性能。在评估了NAS-Bench-1shot1上现有的选择方法之后,我们获得了见解,并提出了一种新的NAS选择方法,该方法更倾向于目标数据熵分布尾部的示例。我们充分展示了NAS的加速能力以及所提出的概率选择在各种数据集和NAS算法上的适用性。值得注意的是,ImageNet上的直接搜索已于2007年7月完成。5 GPU小时,表明反向传输方法有效。我们预计,通过使用代理数据,NAS的其他研究将受益于搜索成本的显著降低。

















 7064
7064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









