




 本文介绍了XML的基本概念,强调了XML与HTML的区别。XML是一种用于传输和存储数据的可扩展标记语言,具有树状结构。接着,文章探讨了XML的解析方式,包括DOM(Document Object Model)和SAX(Simple API for XML),并提到了DOM4J的优缺点。此外,还讲解了XPath的用途,一种用于在XML文档中查找信息的语言。最后,文章讨论了XML的约束,如DTD(Document Type Definition)和XML Schema,用于定义XML文档的结构和合法构建模块。
本文介绍了XML的基本概念,强调了XML与HTML的区别。XML是一种用于传输和存储数据的可扩展标记语言,具有树状结构。接着,文章探讨了XML的解析方式,包括DOM(Document Object Model)和SAX(Simple API for XML),并提到了DOM4J的优缺点。此外,还讲解了XPath的用途,一种用于在XML文档中查找信息的语言。最后,文章讨论了XML的约束,如DTD(Document Type Definition)和XML Schema,用于定义XML文档的结构和合法构建模块。
一.XML简介
XML(eXtendsible markup language) : 可扩展的标记语言
与HTML的区别:
- HTML被设计用来显示数据
- XML被设计用来传输和存储数据
XML结构: 树状结构
<root>
<child>
<subchild>.....</subchild>
</child>
</root>
其中作为根元素,其余元素均被包含在中
XML实例:
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<note caution="urgent">
<from>Now</from>
<to>Future</to>
<message>Stay hungry, stay foolish!</message>
</note>
文档声明:
- version:解析xml时,使用的版本解析器
- encoding:解析xml的文本时,使用什么编码
- standalone:
no–该文档会依赖关联其他文档 yes–独立文档
元素定义:
- 根元素:
- 元素:
- 文本::Now / Future / Stay
hungry, stay foolish! - 属性: caution
**实体引用:**在 XML 中,有 5 个预定义的实体引用,防止解析器把它当做新元素的开始
< < 小于
> > 大于
& & 和号
' ' 单引号
" " 引号
二.XML解析
XML的常用的两种解析方式:
1.DOM(Document Object Model):
XML文档对象模型,如果XML特别大,会造成内存溢出;
可以文档进行增删操作
2.SAX(Simple API of XML):
基于事件驱动;
只能进行查询,不能进行增删操作
使用较广泛的解析API : dom4j
DOM4J有更复杂的api,所以dom4j比jdom有更大的灵活性.DOM4J性能最好,连Sun的JAXM也在用DOM4J.目前许多开源项目中大量采用DOM4J,例如大名鼎鼎的Hibernate也用DOM4J来读取XML配置文件。如果不考虑可移植性,那就采用DOM4J.
优点:灵活性最高、易用性和功能强大、性能优异
缺点:复杂的api、移植性差
在Eclipse中建立新java project,在src下建立students.xml文件,内容如下:
<?xml version="1.0" encoding="UTF-8"?><students>
<student>
<name>张大胖</name>
<age>24</age>
<address>广州</address>
</student>
<student>
<name>陈小胖</name>
<age>27</age>
<address>佛山</address>
</student>
</students>
java文件如下:
package com.XMLdemo;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class XMLDemo {
public static void main(String[] args) {
//创建sax读取对象
SAXReader sr = new SAXReader();
try {
//解析指定的xml文件
Document document = sr.read("src/students.xml");
//获取根元素并输处根元素名字
Element rootElement = document.getRootElement();
System.out.println(rootElement.getName());
//获取所有元素
List<Element> elements = rootElement.elements();
System.out.println("----------");
//遍历所有元素
for (Element element : elements) {
String name = element.element("name").getText();
String age = element.element("age").getText();
String address = element.element("address").getText();
System.out.println("name=" +name + ", age=" + age
+ ", address=" + address);
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
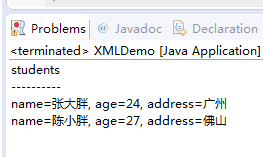
控制台输出如下图:
三.使用Xpath解析
xpath是一种路径语言
nodename 选取此节点上的所有子节点
/ 从根节点选取
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
详细语法不介绍了,具体可以查看w3school的xpath语法教程。
使用方法:
1.添加jar包
2.
package com.XMLdemo;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
public class XpathDemo {
public static void main(String[] args) {
//创建sax对象
SAXReader sr = new SAXReader();
try {
//解析文档
Document document = sr.read("src/students.xml");
//获取根元素接点
Element rootElement = document.getRootElement();
//使用xpath获取元素
Element nameElement = (Element) rootElement.selectSingleNode("//name");
System.out.println(nameElement.getText());
System.out.println("----------------");
//使用xpath获取所有name元素
List<Node> list = rootElement.selectNodes("//name");
for (Node node : list) {
System.out.println(node.getText());
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
四.XML约束
DTD约束
文档类型定义(DTD)可定义合法的XML文档构建模块。它使用一系列合法的元素来定义文档的结构。
DTD 可被成行地声明于 XML 文档中,也可作为一个外部引用。
<?xml version="1.0" encoding="UTF-8"?>
<!-- 本地DTD
<!DOCTYPE students SYSTEM "stus.dtd"> -->
内嵌式
<!DOCTYPE students [
<!ELEMENT students (student+)>
<!ELEMENT student (name, age, address)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT address (#PCDATA)>
]>
<students>
<student>
<name>张大胖</name>
<age>24</age>
<address>广州</address>
</student>
<student>
<name>陈小胖</name>
<age>27</age>
<address>佛山</address>
</student>
</students>
PCDATA:被解析的字符数据(parse character data),这些数据将被解析器检查实体并标记
CDATA:字符数据(character data),不会被解析器解析的文本
Schema:
XML Schema 的作用是定义 XML 文档的合法构建模块,类似 DTD。是DTD的替代者。
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/stus"
xmlns:tns="http://www.example.org/stus" elementFormDefault="qualified">
<xs:element name="students">
<xs:complexType>
<xs:sequence maxOccurs="2">
<xs:element name="name" type="xs:string"></xs:element>
<xs:element name="age" type="xs:int"></xs:element>
<xs:element name="address" type="xs:string"></xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









