




 本文探讨了Redis的两种持久化方法:快照和AOF,以及如何通过复制功能实现数据副本,提升读取性能。文章还介绍了Redis事务的特性与限制,以及非事务型流水线的使用。
本文探讨了Redis的两种持久化方法:快照和AOF,以及如何通过复制功能实现数据副本,提升读取性能。文章还介绍了Redis事务的特性与限制,以及非事务型流水线的使用。
一、Redis持久化选项
Redis提供了两种不同的持久化方法来讲数据存储到硬盘里面。一种是快照,可以将存在于某一时刻的所有数据都写入硬盘里面。另一中方法叫只追加文件,他会在执行写命令时,将被执行的写命令复制到硬盘里面。
1.1 快照持久化
通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。在创建快照以后,用户可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本,还可以将快照留在原地以便重启服务器时使用。
创建快照的办法:
- 客户端向redis发送BGSAVE命令来创建一个快照
- 客户端向redis发送SAVE命令来创建一个快照
- 用户设置了save配置选项,如save 60 10000,表示从redis最近一次创建快照之后开始算起,当“60秒之内有10000次写入”条件满足时,redis就会自动触发BGSAVE命令。
- redis通过SHUTDOWN命令接收到关闭服务器的请求时
- 当一个redis服务器连接另一个redis服务器,并向对方发送SYNC命令来开始一次复制操作的时候
快照持久化的应用场景
- 个人开发
在个人开发的服务器上,主要考虑的是尽可能地降低快照持久化带来的资源消耗。 - 对日志进行聚合计算
- 大数据
如果可以妥善地处理快照持久化可能带来的大量数据丢失,那么快照持久化对用户来说将是一个不错的选择。
1.2 AOF持久化
AOF持久化会降被执行的写命令写到AOF文件的末尾,以此来纪录数据发生的变化。因此redis只要从头到尾重新执行一次AOF文件包含的所有写命令,就可以恢复AOF文件所记录的数据集。
AOF持久化配置选项对AOF文件同步频率的影响
| 选项 | 同步频率 |
|---|---|
| always | 每个Redis写命令都要同步写入硬盘。这样做会严重降低Redis的速度 |
| everysec | 每秒执行一次同步,显式地将多个写命令同步到硬盘 |
| no | 让操作系统来决定应该何时进行同步 |
为了兼顾数据安全和写入性能,可以考虑使用appendfsync everysec选项,让Redis以每秒一次的频率对AOF文件进行同步。这样性能和不适用任何持久化特性时的性能相差无几。即是出现系统崩溃,用户也最多只丢失一秒以内产生的数据。
1.3 重写/压缩AOF文件
AOF持久化的问题:
- redis不停将被执行的写命令纪录到AOF文件中,随着redis的不断运行,AOF文件的体积也会不断增长,在极端情况下,体积不断增大的AOF文件甚至可能会用完硬盘的所有可用空间。
- redis重启后需要通过重新执行AOF文件纪录的所有写命令来还原数据集,所以如果AOF文件的体积非常大,那么还原操作执行的时间就可能非常长。
解决办法
用户可以向redis发送BGREWRITEAOF命令,移除AOF文件中的冗余命令来重写AOF文件,缩小AOF文件的体积。
二、复制
复制可以让其他服务器拥有一个不断地更新的数据副本,从而使得拥有数据副本的服务器可以用于处理客户端发送的读请求。关系数据库通常会使用一个主服务器(master)向多个从服务器(slave)发送更新,并使用从服务器来处理所有读请求。redis也采用了同样的方法来实现自己的复制特征,并将其作为扩展性能的一种手段。
在需要扩展读请求的时候,或者在需要写入临时数据的时候,用户可以设置额外的redis从服务器来保存数据集的副本。在接收到主服务器发送的数据初始副本时以后,客户端每次向主服务器进行写入时,从服务器都会实时地得到更新。在部署好主从服务器以后,客户端就可以像任意一个从服务器发送读请求了,而不必再像之前一样,总是把每个读请求都发送给主服务器(客户端通常会随机地选择使用哪个从服务器,从而将负载平均分配到各个从服务器上)
2.1 对Redis的复制相关选项进行配置
从服务器连接主服务器时,主服务器会执行BGSAVE操作。为了保证正确地使用复制特征,用户需要保证主服务器已经正确地设置了dir选项和dbfilename选项
从服务器所必须的选项只有slaveof,指定一个包含slaveof host port选项的配置文件,redis服务器将根据该选项给定的IP地址和端口号来连接主服务器。
2.2 redis复制的启动过程
| 步骤 | 主服务器操作 | 从服务器操作 |
|---|---|---|
| 1 | 等待命令进入 | 连接主服务器,发送SYNC命令 |
| 2 | 开始执行BGSAVE,并使用缓冲区纪录BGSAVE之后的所有写命令 | 根据配置选项来决定是继续使用现在的数据来处理客户端的命令请求,还是向发送请求的客户端返回错误 |
| 3 | BGSAVE执行完毕,向从服务器发送快照文件,并在发送期间继续使用缓冲区纪录被执行的写命令 | 丢弃所有旧数据(如果有的话),开始载入主服务器发来的快照文件 |
| 4 | 快照文件发送完毕,开始向从服务器发送存储在缓冲区里面的写命令 | 完成对快照文件的解释操作,像往常一样开始接受命令请求 |
| 5 | 缓冲区存储的写命令发送完毕;从现在开始,每执行一个命令,就像从服务器发送相同的写命令 | 执行主服务器发来的所有存储在缓冲区里面的写命令;并从现在开始,接收并执行主服务器传来的每个写命令 |
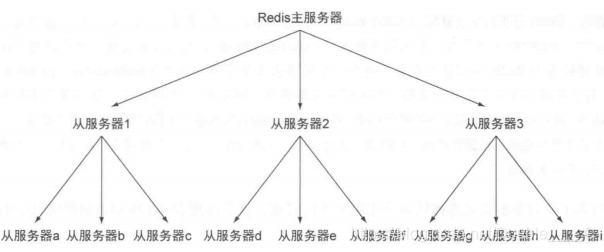
2.3 主从链
从服务器也可以拥有自己的从服务器,并由其行程主从链。
当从服务器X拥有从服务器Y,那么当从服务器X在执行上面的步骤4时,他将断开与从服务器Y的连接,导致从服务器Y需要重新连接并重新同步(resync)
当读请求的重要性明显高于写请求的重要性,并且读请求的数量远远超过一台redis服务器可以处理的范围时,用户就需要添加新的从服务器来处理读请求。随着负载不断上升,主服务器可能会无法快速地更新所有从服务器,或者因为重新连接和重新同步从服务器导致系统超载。为了缓解这个问题,用户可以创建一个由redis主从节点组成的中间层来分担主服务器的复制工作
2.4 检查硬盘写入
验证主服务器是否已经将写数据发送到从服务器,用户需要在向主服务器写入真正的数据之后,再向主服务器写入一个唯一的虚构值,通过检查虚构值是否存在于从服务器来判断写数据是否已经到达从服务器。
判断数据是否已经被保存到硬盘里则需要检查INFO命令的输出结果中aof_pending_bio_fsync的属性值是否为0,是则表示服务器已经将已知的所有数据保存到硬盘里面了。
通过同时使用复制和AOF持久化,用户可以增强redis对于系统崩溃的抵抗能力
三、处理系统故障
略
四、Redis事务
redis的事务和传统事务并不相同。单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
redis事务命令
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | DISCARD | 取消事务,放弃执行事务块内的所有命令 |
| 2 | EXEC | 执行所有事务块内的命令 |
| 3 | MULTI | 标记一个事务块的开始 |
| 4 | UNWATCH | 取消WATCH命令对所有key的监视 |
| 5 | WATCH | 监视一个或多个key,如果在事务执行之前这个key被其他命令所改动,那么事务将被打断 |
事务演示
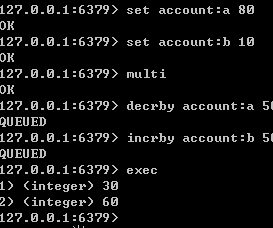
输入Multi命令后,输入的命令都会一次进入命令队列中,但不会执行
知道输入exec命令后开始将命令队列中的命令依次执行
可以使用discard取消命令
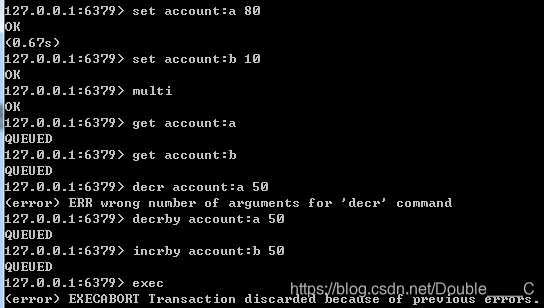
事务的错误处理
命令报错,此条命令不执行,其他执行
(若语法错误出现报告错误,则整个事务不执行)
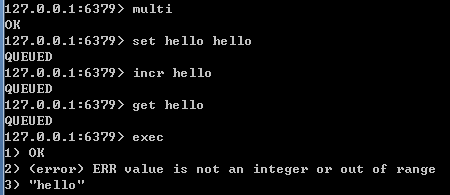
报错错误
为什么redis没有加锁
关系型数据库在写时,会加锁,直到事务被提交或者回滚位置。如果有其他客户端视图对被加载的数据行进行写入,那么客户端将被阻塞。这种锁的缺点是,持有锁的客户端运行越慢,等待解锁的客户端被阻塞的时间就越长
因为加锁有可能造成长时间的等待,redis为了尽可能的减少客户端的等待时间,并不会在执行WATCH命令时对数据加锁。而是在数据被抢先修改的情况下通知执行了WATCH命令的客户端,这种做法是乐观锁。关系型数据库实际执行的加锁操作则是悲观锁。
五、非事务型流水线
在执行大量命令的情况下,即是命令实际上并不需要放在事务里面执行,但是为了通过一次发送所有命令来减少通信次数并降低延迟值,用户可能将命令包裹在MULTI和EXEC里面执行。但是MULTI和EXEC也会消耗资源,并导致其他重要的命令被延迟执行。
实际上,可以不使用MULTI和EXEC的情况下,获得流水线执行,即redis的管道流技术
管道技术最显著的优势是提高了 redis 服务的性能

















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









