



在分布式系统中,“ZK” 通常指 ZooKeeper(Apache ZooKeeper),它是一个用于提供分布式协调服务的开源组件,核心功能包括配置管理、命名服务、分布式锁和领导者选举(Leader Election) 等。ZooKeeper 的选举算法是其保证高可用的关键,经历了从 “原始选举算法” 到 “快速选举算法”(Zab 协议的核心部分)的演进,目前生产环境中均使用快速选举算法。
一、前置核心概念
在分析选举算法前,需先掌握 3 个关键概念:
-
集群角色
- Leader(领导者):集群唯一的写操作处理者,负责将写请求同步到所有 Follower,保证数据一致性;同时协调选举过程。
- Follower(追随者):接收客户端读请求,转发写请求给 Leader;参与 Leader 选举投票,同步 Leader 的数据。
- Observer(观察者):仅接收读请求和同步数据,不参与选举投票(用于扩展读性能,不影响选举效率)。
-
Zxid(事务 ID)
- 全局唯一的 64 位整数,用于标识 ZooKeeper 中的每一次写事务(如创建节点、修改数据),格式为
(epoch << 32) | counter:epoch: Leader 的 “任期号”,每次新 Leader 当选,epoch 会递增(保证任期唯一性);counter:当前任期内的事务计数器,每次写事务递增。
- Zxid 越大,代表节点的数据越新、越完整—— 这是选举中判断 “谁更适合当 Leader” 的核心依据。
- 全局唯一的 64 位整数,用于标识 ZooKeeper 中的每一次写事务(如创建节点、修改数据),格式为
-
Quorum(法定人数)
- 选举成功或事务提交所需的 “最小投票数”,计算公式为
Quorum = (集群节点数 / 2) + 1(向下取整)。例如:- 3 节点集群:Quorum = 2(需 2 票支持);
- 5 节点集群:Quorum = 3(需 3 票支持)。
- 目的是避免 “脑裂”(集群分裂为多个小集群,各自选 Leader),保证最终只有一个合法 Leader。
- 选举成功或事务提交所需的 “最小投票数”,计算公式为
二、选举的触发场景
ZooKeeper 会在以下两种情况下触发 Leader 选举:
- 集群初始化:集群首次启动时,所有节点均为 “Looking”(寻找 Leader)状态,需通过选举产生第一个 Leader。
- Leader 故障:运行中 Leader 因网络中断、节点宕机等原因失联,Follower 检测到后会切换为 “Looking” 状态,重新发起选举。
三、核心:快速选举算法(Zab 协议)
ZooKeeper 从 3.4.0 版本开始采用 Zab(ZooKeeper Atomic Broadcast)协议,其选举阶段(也叫 “发现阶段”)就是 “快速选举算法”,核心目标是在最短时间内选出数据最新的节点作为 Leader,避免不必要的投票轮次。
算法核心逻辑
每个 “Looking” 状态的节点会遵循以下规则参与选举:
- 投票初始化:节点首次投票时,会给自己投一票,投票内容为
(myid, myZxid)(myid 是节点唯一标识,在配置文件中指定;myZxid 是节点当前的最大事务 ID)。 - 投票比较与更新:节点收到其他节点的投票后,会按以下优先级比较两票(自己的票 vs 收到的票),选择 “更优” 的票重新发起投票:
- 优先级 1:Zxid 更大的更优:Zxid 大意味着该节点的数据更完整(包含更多事务),更适合当 Leader;
- 优先级 2:若 Zxid 相同,myid 更大的更优:Zxid 一致时,通过唯一的 myid 打破平局。
- 统计投票,判断是否当选:节点每轮投票后,会统计所有收到的投票中 “支持同一节点” 的票数:
- 若某节点的得票数 ≥ Quorum(法定人数),则该节点当选为 Leader;
- 当选节点会切换为 “Leading” 状态,其他节点切换为 “Following” 状态,选举结束。
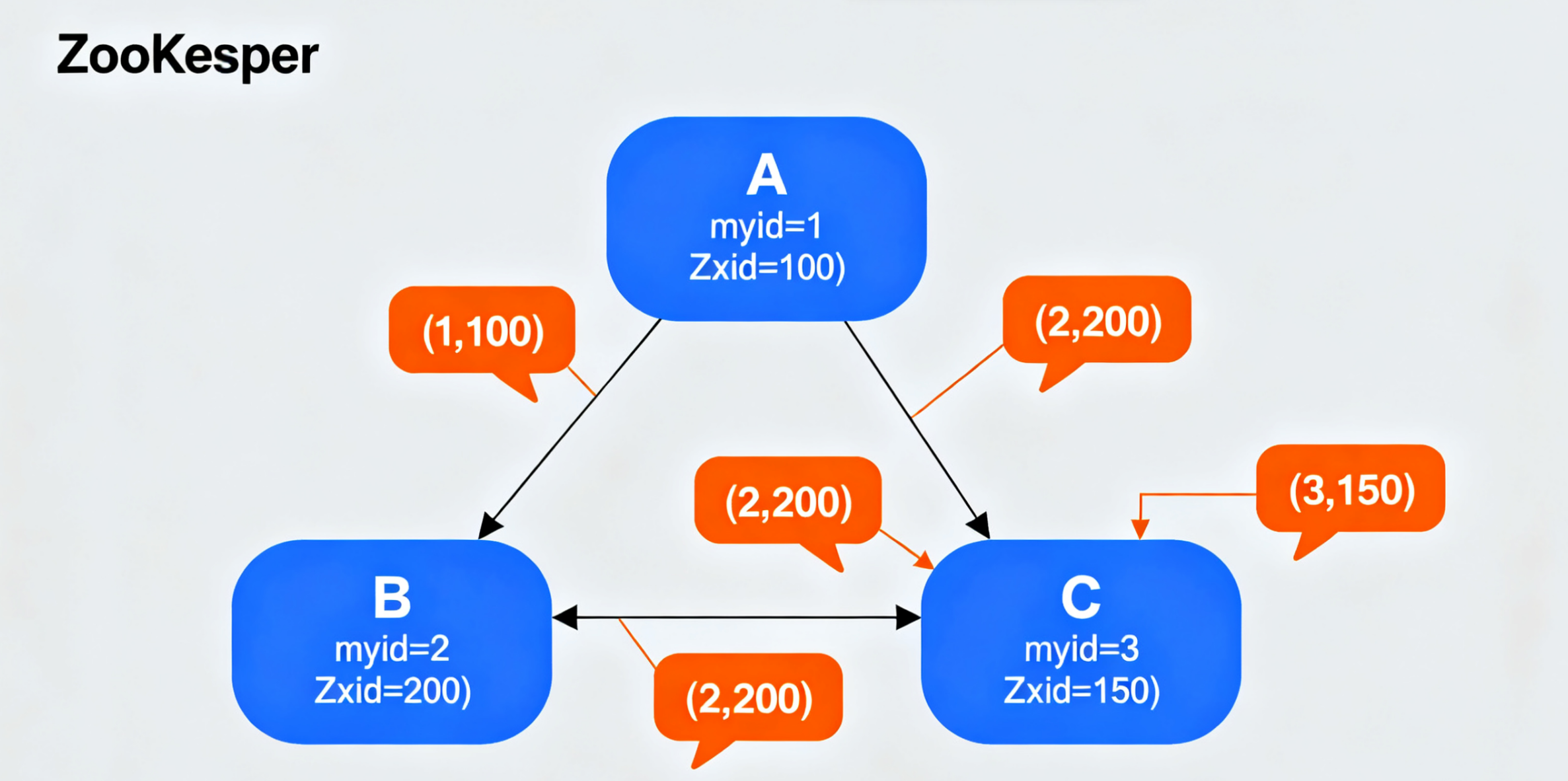
选举流程示例(以 3 节点集群为例)
假设集群节点为 A(myid=1,Zxid=100)、B(myid=2,Zxid=200)、C(myid=3,Zxid=150),Quorum=2,流程如下:
-
初始化投票:
- A 投给自己:(1, 100);
- B 投给自己:(2, 200);
- C 投给自己:(3, 150)。
-
投票交换与比较:
- A 收到 B 的投票 (2, 200):B 的 Zxid(200)> A 的 Zxid(100),A 放弃自己的票,改投 B,新投票为 (2, 200);
- A 收到 C 的投票 (3, 150):C 的 Zxid(150)> A 的 Zxid(100),但 B 的 Zxid(200)> C 的 Zxid(150),A 仍保持投 B;
- B 收到 A 和 C 的投票:A 投 B(2,200),C 收到 B 的投票后,因 B 的 Zxid 更大,改投 B,此时 B 收到 2 票(A 和 C);
- C 收到 A 的投票(已改投 B)和 B 的投票,确认 B 得票 2 票。
-
确认当选:
- B 的得票数(2)≥ Quorum(2),B 当选为 Leader,切换为 Leading 状态;
- A 和 C 切换为 Following 状态,选举结束。
四、原始选举算法(了解即可)
ZooKeeper 早期版本使用 “原始选举算法”,流程更繁琐,效率较低,已被快速选举算法取代。其核心问题是需要多轮投票,且依赖 “编号顺序” 而非数据完整性:
- 所有节点初始状态为 “Looking”,先投票给自己;
- 若某节点的 myid 是当前投票中最大的,且得票数 ≥ Quorum,则当选;否则进入下一轮投票,重复此过程;
- 缺点:未考虑 Zxid,可能导致 “数据较旧但 myid 大” 的节点当选 Leader,需额外同步大量数据,影响集群恢复速度。
五、选举算法的关键特性
ZooKeeper 选举算法的设计保证了分布式系统的核心需求:
- 唯一性:通过 Quorum 机制,确保最终只有一个 Leader(避免脑裂);
- 完整性:优先选择 Zxid 最大的节点,保证 Leader 数据最新,减少数据同步开销;
- 高效性:快速选举算法通过 “一轮投票 + 优先级比较”,避免多轮协商,缩短选举时间(通常毫秒级完成);
- 容错性:只要存活节点数 ≥ Quorum,就能重新选举 Leader(例如 5 节点集群允许 2 个节点故障)。
总结:ZooKeeper 的选举核心是基于 Zab 协议的快速选举算法,通过 “Zxid 优先、myid 补位” 的投票规则和 Quorum 机制,高效、可靠地选出 Leader,支撑分布式系统的协调服务。

















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









