 Java堆内缓存优化:重复数据集复用
Java堆内缓存优化:重复数据集复用





还记得主播ai标签的优化?书接上文 科普篇之Java堆内缓存优化-IntegerCache的使用-优快云博客
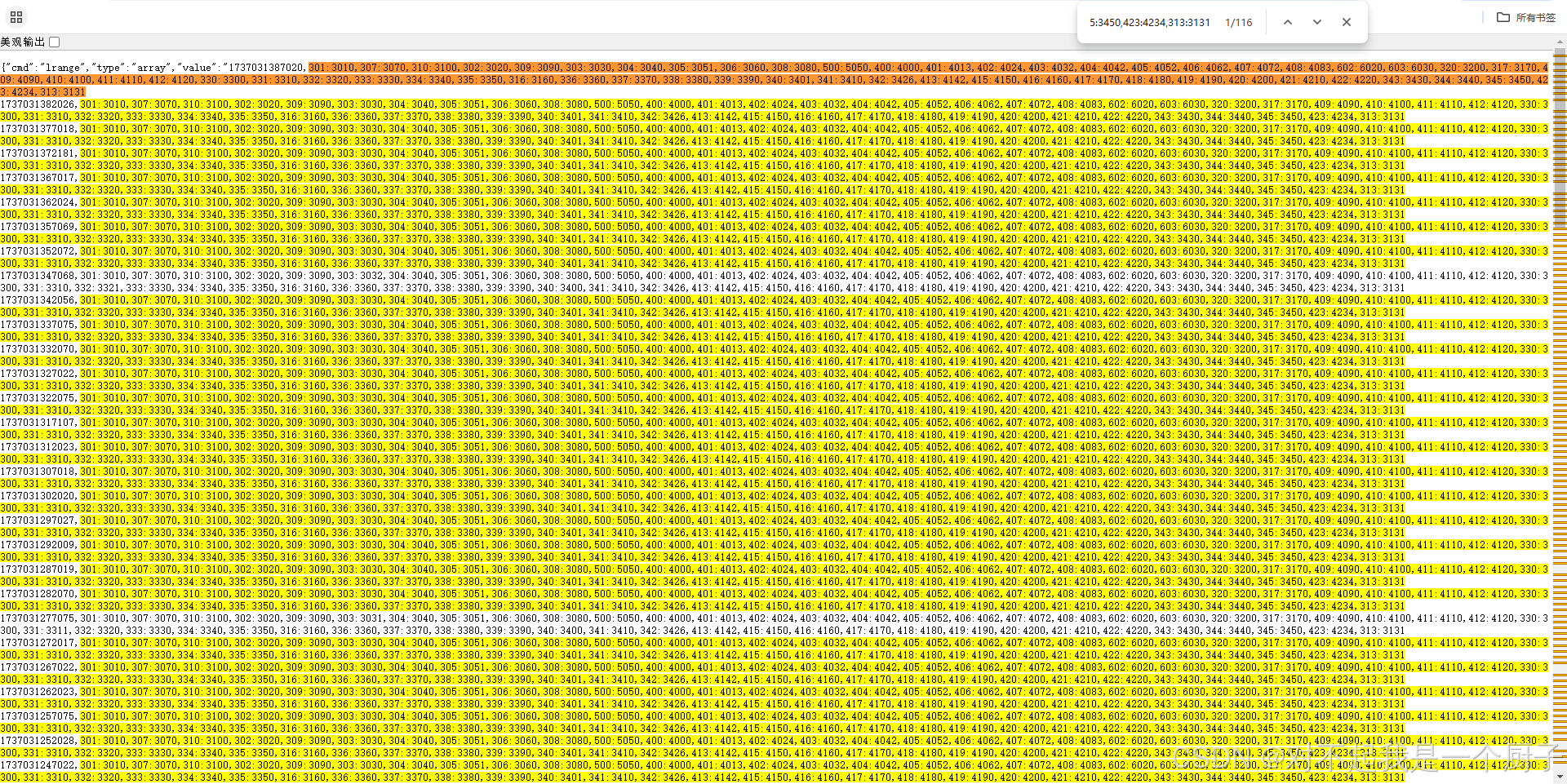
每个在线主播的ai标签每5s生成一个,包含50多个标签识别集
通过观察发现主播在短时间内识别出的ai标签变化并不大,目前线上是保留主播最近120个识别标签集,对于同一个主播有可能120个识别标签集完全一样,而主播与主播间也可能存在相同的识别结果
那么是不是可以从之前的120个识别标识集中找到一个与最新识别相同的标签集的引用,而不是new一个新的标签结果集?如此看来对一些识别结果变化不大的主播则可以大大的减少的内存使用
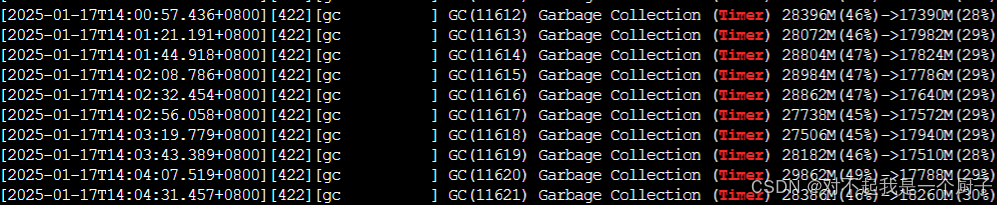
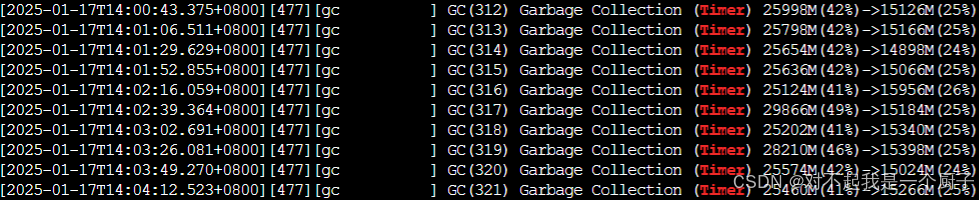
通过对比垃圾回收后的内存占用,粗略估计减少了近3G的内存使用
优化前
优化后

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









