




文章目录
前言
路漫漫其修远兮,吾将上下而求索。
一、栈的概念
栈是一种特殊的线性表,只允许在固定的一端(栈顶)进行插入和删除元素的操作。
进行数据的插入与删除的一端称为栈顶,另外一端称为栈底;栈中的元素遵循先进先出(LIFO:Last In First Out)的原则;
- 压栈:将数据放入栈中的操作称为压栈/入栈,在栈顶进行入栈的操作
- 出栈:将栈中的数据删除也称为出栈,出数据在栈顶
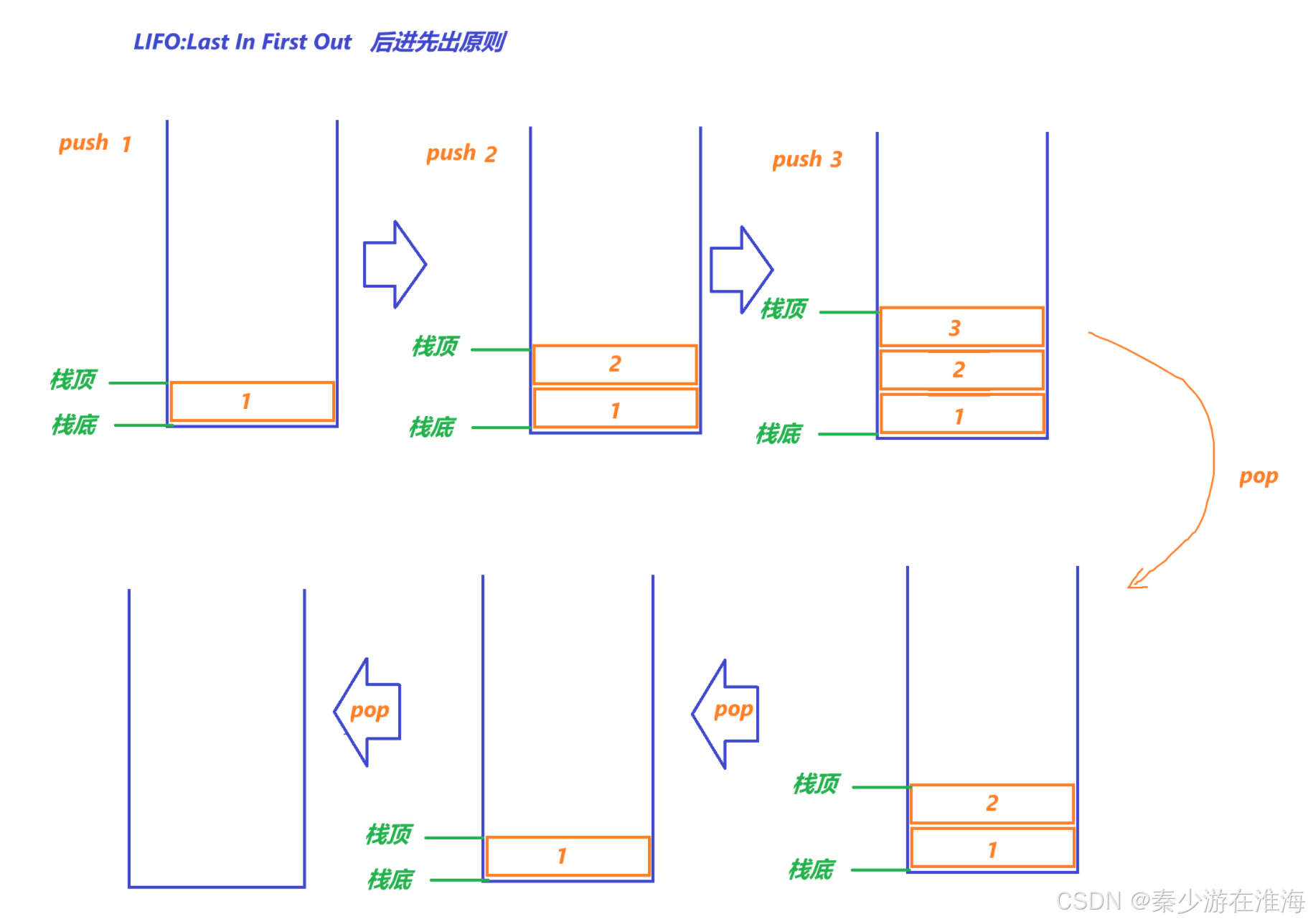
注:如上图所示,最后入栈的数据出栈时最先出;入栈、出栈的顺序并未规定,可以自由组合;
二、栈的实现
(一)、底层结构选择
栈的实现可以利用两种结构: 1、链表 2、数组
其中“栈” 的栈顶需要我们自己规定;
我们来思考一下链表是否可以实现栈:
- 对于单链表,如果将尾结点当作栈顶,显然是非常不友好的,因为尾删的时候需要解决尾结点前一个结点的链接关系,即需要通过遍历找到尾结点的前一个结点,时间复杂度为O(N),这种方法排除;
- 那么如果将单链表的头节点当作栈顶进行出栈入栈,相当于单链表的头删、头插,这种方法是可以的;
- 当然,利用双向链表也可以解决,并且在双向链表中头节点、尾结点谁作为栈顶均可以;
注:上述讨论的链表带头与不带头均可;
接下来我们再来思考一下栈是否能利用数组来实现;
- 将下标大的那一端当作栈顶,插入、删除数据不存在数据的挪动而导致效率低下的问题;
- 而如若将下标为0处的空间当作栈顶,那么插入、删除数据均需要一个一个地挪动数据,效率极低,排除;
综上,实现栈的结构以及栈顶的选择:
- 1、单链表 头节点作为栈顶
- 2、双向链表 头节点与尾结点均可作为栈的栈顶
- 3、数组 下标增涨的那个方向作为栈顶
本文用数组来实现,选择下标增长的那个方向作为栈顶;
能用单链表实现的就尽量不使用双链表,因为在双链表的每个结点中均会多存一个指针(能少用内存就尽量少用内存);但是由于单链表的CPU高速缓存命中率低,而数组的CPU高速缓存命中率高,用数组来实现栈就存在一个问题,那就是扩容;
用的单链表实现栈与用数组来实现栈其实都差不多,并没有太大的优劣,但倘若非要选一个,推荐用数组,因为数组的CPU高速缓存命中率高;
(二)、Stack.h 的实现
代码如下:
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
//栈的类型声明
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
//初始化
void STInit(ST* pst);
//释放
void STDestroy(ST* pst);
//入栈
void STPush(ST* pst, STDataType x);
//出栈
void STPop(ST* pst);
//获取栈顶元素
STDataType STTop(ST* pst);
//判空
bool STEmpty(ST* pst);
//获取数据个数
int STSize(ST* pst);
//打印
void STPrint(ST* pst);(三)、Stack.c 的实现
1、初始化
//初始化
void STInit(ST* pst)
{
assert(pst);
pst->a = NULL;
pst->top = pst->capacity = 0;
}此处的也可以将top 初始化为-1 ,在push 的时候便要先让top++ ,然后再将数据放入;此时的top 便指向尾数据;
而若将top 初始化为0,则代表 top 指向尾数据的下一空间;
2、释放
//释放
void STDestroy(ST* pst)
{
assert(pst);
//释放所有动态开辟的空间
free(pst->a);
pst->a = NULL;
pst->top = pst->capacity = 0;
//将top 初始化为0代表着top 指向栈顶元素的下一空间
}3、入栈
//入栈
void STPush(ST* pst, STDataType x)
{
assert(pst);
//空间是否足够
if (pst->top == pst->capacity)
{
int newcapacity = pst->capacity == 0 ? 4 : 2 * pst->capacity;
STDataType* newnode = (STDataType*)realloc(pst->a, sizeof(STDataType) * newcapacity);
if (newnode == NULL)
{
perror("STPust realloc");
exit(-1);
}
pst->a = newnode;
pst->capacity = newcapacity;
}
pst->a[pst->top] = x;
pst->top++;
}4、出栈
//出栈
void STPop(ST* pst)
{
assert(pst);
//删除的数据的前提是有数据可以删除
assert(pst->top);
pst->top--;
}
5、获取栈顶元素
//获取栈顶元素
STDataType STTop(ST* pst)
{
assert(pst);
assert(pst->top );
return pst->a[pst->top - 1];
}6、判空
//判空
bool STEmpty(ST* pst)
{
assert(pst);
return pst->top == 0;//空为真
}
注:此处认为当栈为空时返回true ,故而可以将 pst->top == 0; 当作一个判断;
7、获取栈中的数据个数
//获取数据个数
int STSize(ST* pst)
{
assert(pst);
return pst->top;
}
8、打印 - 同时会将栈中 的数据全部出栈
//打印
void STPrint(ST* pst)
{
assert(pst);
//获取栈顶元素,然后pop
while (!STEmpty(pst))
{
printf("%d ", STTop(pst));
STPop(pst);
}
}注:在数据结构之中,不要因为接口函数功能实现简单,便不写其对应地接口函数而选择直接访问数据手动实现;倘若使用的时候对底层的实现不清楚的话自己手动实现功能(不调用接口函数)就很容易出错;
总结
栈是一种特殊的线性表,只允许在固定的一端(栈顶)进行插入和删除元素的操作。
进行数据的插入与删除的一端称为栈顶,另外一端称为栈底;栈中的元素遵循先进先出(LIFO:Last In First Out)的原则;
- 压栈:将数据放入栈中的操作称为压栈/入栈,在栈顶进行入栈的操作
- 出栈:将栈中的数据删除也称为出栈,出数据在栈顶
荐用数组,因为数组的CPU高速缓存命中率高;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









