






文章目录
Q:为什么需要使用临时数组std::vector<Functor> t?
Q: 为什么需要将对 _is_running 的操作放在锁内?
前言
路漫漫其修远兮,吾将上下而求索;
一、池化思想
池化技术的核心思想:
提前创建并复用资源,避免频繁创建 / 销毁带来的性能开销。
常见的池化对象包括:
| 池化对象 | 目的 |
|---|---|
| 线程池 | 降低线程创建 / 销毁开销 |
| 连接池 | 数据库 / RPC 连接复用 |
| 内存池 | 降低 malloc / free 碎片和锁竞争 |
Q:为什么线程需要池化?
- 在 Linux / C++ 中,线程的创建和销毁并是存在消耗的,频发地创建、销毁是非常消耗CPU效率的:
创建线程需要:分配栈空间、初始化线程控制块(TCB)、内核态参与调度
高频创建线程会导致:性能抖动、上下文切换成本增加、系统资源不可控
二、实现
模型抽象
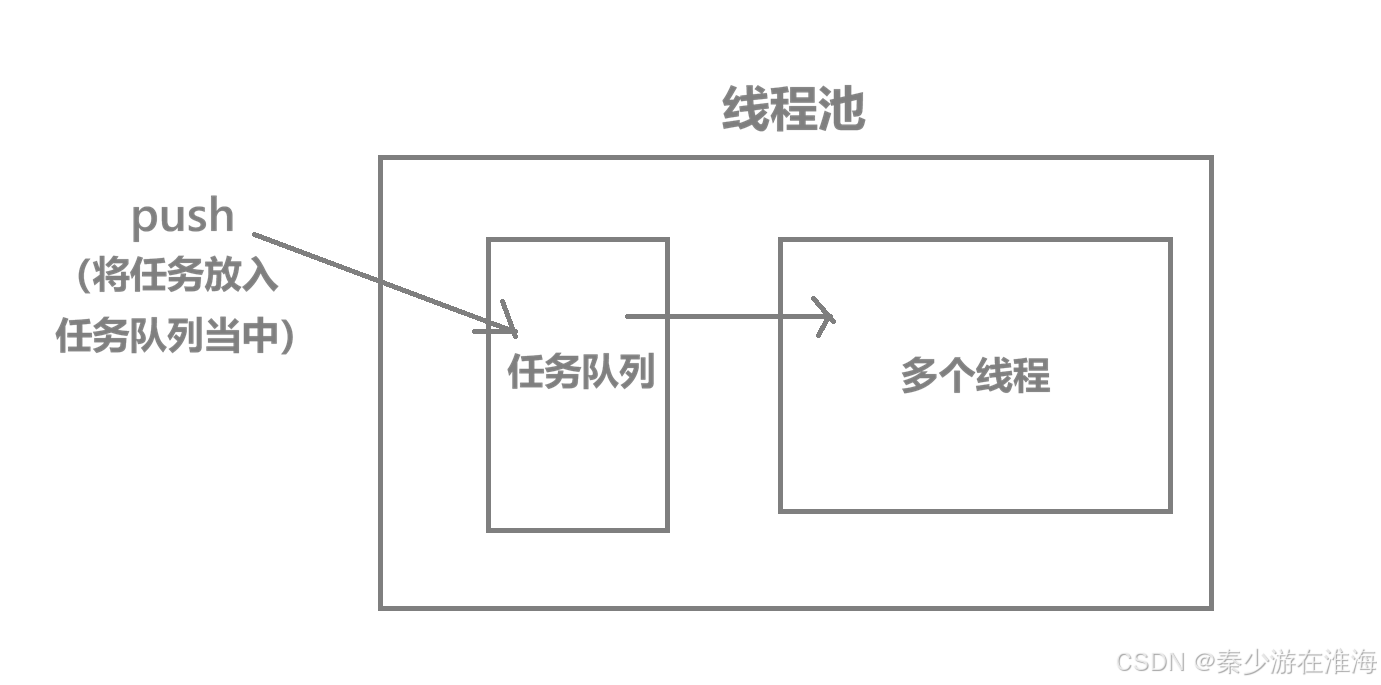
Producer–Consumer 模型:
生产者:push() 提交任务、消费者:工作线程 entry() 取任务执行
共享资源:任务队列、条件变量、运行状态标志
代码实现
#pragma once
#include<iostream>
#include<string>
#include<vector>
#include<mutex>
#include<condition_variable>
#include<memory>
#include<atomic>
#include<functional>
#include<thread>
#include<future>
#define threaddefaultnum 3
class threadpool
{
using Functor = std::function<void()>;
public:
threadpool(int threadnum = threaddefaultnum)
:_is_running(true)
{
//创建线程池
for(int i = 0;i<threadnum;i++)
{
_threads.emplace_back(&threadpool::entry , this);
}
}
//禁掉拷贝构造、赋值重载
threadpool(const threadpool& tp) = delete;
threadpool& operator=(const threadpool& tp) = delete;
//向任务队列中放任务
template<typename F,typename ...Args>
auto push(F&& func , Args&& ... args) ->std::future<decltype(func(args...))>
{
using return_type = decltype(func(args...));
//bind
auto tmp_func = std::bind(std::forward<F>(func) , std::forward<Args>(args)...);//完美转发
//利用package_task进行包装
auto task = std::make_shared<std::packaged_task<return_type()>>(tmp_func);
//获取futrue
std::future<return_type> fu = task->get_future();
//将任务放入任务队列当中
{
std::unique_lock<std::mutex> lock(_mutex);
if(_is_running==false) return std::future<return_type>();
_tasks.push_back([task](){(*task)();});
}
_cv.notify_one();
return fu;
}
//停止线程池
void stop()
{
{
std::unique_lock<std::mutex> lock(_mutex);
if(_is_running == false) return;
_is_running = false;
}
_cv.notify_all();
//等待线程退出
for(auto& thread : _threads)
{
thread.join();
}
}
~threadpool()
{
stop();
}
private:
//线程的入口函数
void entry()
{
while(true)
{
std::vector<Functor> t;
{
std::unique_lock<std::mutex> lock(_mutex);
_cv.wait(lock , [this](){
return !_tasks.empty() || !_is_running;
});
t.swap(_tasks);
}
//判断是否退出
if(_tasks.empty() && _is_running==false)
{
std::cout << "线程退出" << std::endl;
break;
}
//执行任务
for(auto& task : t)
{
task();
}
}
}
private:
//任务队列、线程池、锁 条件变量 标志位
std::atomic<bool> _is_running;
std::vector<Functor> _tasks;
std::mutex _mutex;
std::condition_variable _cv;
std::vector<std::thread> _threads;
};三、细节补充
构造时创建threadnum 个 线程 (传入线程的入口函数entry) --> 向任务队列中push 任务 --> 只要任务队列中任务线程池中的线程就会去处理(锁、条件变量) --> 关闭线程池 (stop)
Q:为什么禁用拷贝构造与赋值重载?
//禁掉拷贝构造、赋值重载
threadpool(const threadpool& tp) = delete;
threadpool& operator=(const threadpool& tp) = delete;需要与单例模式区别开来,单例模式至少满足的条件:构造函数 private、提供全局唯一访问点(如 getInstance())、禁止拷贝 / 移动;
Q:为什么不实现为单例模式?
- 线程池是 “可配置、可管理的资源对象”, 而并非 “全局工具” ,如果实现为单例模式,破坏可测试性以及难以控制其生命周期;
禁止了拷贝是为了避免线程资源被错误复制,由上层控制线程池的生命周期。
entry
循环进行,任务队列中有任务,线程执行任务;任务队列中没有任务,线程等待不退出;
当标志位 _is_running 为 false 并且 任务队列为空时线程就退出循环;
//线程的入口函数
void entry()
{
while(true)
{
std::vector<Functor> t;
{
std::unique_lock<std::mutex> lock(_mutex);
_cv.wait(lock , [this](){
return !_tasks.empty() || !_is_running;
});
t.swap(_tasks);
}
//判断是否退出
if(_tasks.empty() && _is_running==false)
{
std::cout << "线程退出" << std::endl;
break;
}
//执行任务
for(auto& task : t)
{
task();
}
}
}Q:为什么需要使用临时数组std::vector<Functor> t?
- 在持有锁的时间内尽可能少地执行逻辑代码,将任务从共享队列中批量取出后,在锁外执行,既减少了锁竞争,又避免任务执行过程中长时间占用互斥锁。同时,在高并发场景下,频繁加锁 / 解锁的成本比一次性批量取任务要高,使用临时容器(vector)可以显著减少同步开销,提高吞吐量。
使用临时数组是为了将“取任务”和“执行任务”解耦,缩短临界区长度,减少锁竞争,
Q:关于条件标量的wait
push
传入的函数可能为lambda、普通函数、成员函数、函数对象,并且这些函数参数是任意的、返回值也是任意的,此处的push 必然需要使用模板来支持泛型编程;异步操作需要取出该函数执行的结果(使用package_task + future ),函数push 的返回值类型为用户所传入的函数的返回值类型(使用decltype 进行推导),参数使用万能引用
template<typename F,typename ...Args>
auto push(F&& func , Args&& ... args) ->std::future<decltype(func(args...))>将函数返回类型重命名为return_type --> bind (统一处理,方便将函数放入任务队列当中) --> package_task 包装
using return_type = decltype(func(args...));
//bind
auto tmp_func = std::bind(std::forward<F>(func) , std::forward<Args>(args)...);//完美转发
//利用package_task进行包装
auto task = std::make_shared<std::packaged_task<return_type()>>(tmp_func);Q:什么是万能引用?
需要注意的是,并不是所有带 && 的均为万能引用,万能引用必须满足一下两个条件:
- 必须是模板参数推导出来的类型
- 写成 T&& (或者 auto&&)
template<typename T>
void func(T&& x); // x 是万能引用
auto&& x = expr; // auto&& 也是万能引用与右值引用进行区分:
void func(int&& x); //右值引用,不是万能引用
template<typename T>
void func(const T&& x); //不是万能引用万能引用会根据实参是左值还是右值推导成 T& 或 T&&;
eg. template<typename T>
void func(T&& x);
| 传入 | T 推导为 | x 实际类型 |
| 左值 |
|
|
| 右值 |
|
|
Q:bind 中为什么要使用完美转发?
看这个错误示例
template<typename T>
void func(T&& x) {
other(x); // ❌
}即使你这样调用:
func(10);x在函数体内永远是左值!
所以:
- 原本的右值被“降级”成了左值
完美转发的存在可以维持参数原本的左右值属性,还可以避免不必要的拷贝;
注:在源代码中 func 可能为lambda、普通函数等,如果没有使用完美转发,那么lambda / 临时对象会被当成左值;
Q:为什么packaged_task 需要使用智能指针shared_ptr 来指向?
衍生问题:可以不用只能指针吗?只能使用shared_ptr吗?paskage_task的底层原理?
packaged_task 内部独占一个可调用对象、一个promise、以及 shared_state“写权限”,可以理解为 packaged_task 是 shared_state 的写端,而 future 是 shared_state 的读端;
注:shared_state 用来表示 promise / future 之间共享的那块状态与数据。
一个 shared state 包含:
一个存放结果或异常的位置
一个 ready 标志
用于同步的机制(mutex / condition_variable)
而packaged_task 、promise、future 可以指向shared_state,(packaged_task内部包含promise)而packaged_task 对 shared_state 有着写权限(负责将数据放入shared_state 之中),而future对shared_state 有读权限(负责从shared_state 当中读取数据,不能向其中写入);
packaged_task
│
│(内部 promise,写)
▼
shared_state <──────── future
(堆) (读)
因为packaged_task 中存在shared_state , 所以packaged_task 不支持拷贝,只支持移动(如果支持拷贝的话,读、写端会混乱);所以此处auto task = std::make_shared<std::packaged_task<return_type()>>(tmp_func); 必须使用智能指针,(任务队列中的任务类型为Functor)而由于function要求内部对象必须是支持拷贝的,unique_ptr 不支持拷贝,auto_ptr 更不适用,weak_ptr 无法管理资源,所以此处只能使用shared_ptr ;
简单来说就是:
packaged_task 和 unique_ptr 都是 move-only 类型,因为它们表示对某种资源的独占所有权;
而线程池任务队列通常基于 std::function,要求任务对象可拷贝,因此需要用 shared_ptr 作为可拷贝的间接层。
注: move-only 类型 ,不支持拷贝,只支持移动;
获取future:
//获取futrue
std::future<return_type> fu = task->get_future();Q: 为什么不是在函数执行完毕再获取future?
future 并不保存结果本身,它和 promise / packaged_task 共享一块“共享状态(shared state),shared_state 的空间开辟在堆上,由标准库管理。
整个异步获取函数执行结果的流程为:
- 使用packaged_task 封装任务 --> get_future() 获取future --> 任务放入任务队列当中 --> 线程池中的线程执行任务 --> promise(packaged_task 内部包含promise) 将结果写入shared_state 当中 --> get (future )从 shared_state 中拿到执行的结果;
因为shared_state 内部存在同步机制,在函数(任务)执行前获取future 并不会影响获取这个函数执行的结果,并且由于是线程池中的线程领取任务执行,我们也不知道什么时候该任务执行结束,不好在代码层面实现“在函数执行完毕再获取future”;
将任务放入任务队列当中并返回:
//将任务放入任务队列当中
{
std::unique_lock<std::mutex> lock(_mutex);
if(_is_running==false) return std::future<return_type>();
_tasks.push_back([task](){(*task)();});
}
_cv.notify_one();
return fu;Q:条件变量的唤醒操作为什么放在锁外?
条件变量的唤醒通常放在锁外,是为了避免被唤醒的线程立刻因为互斥锁不可用而再次阻塞,从而减少无效的上下文切换,提高并发效率;同时只要共享状态的修改已经在锁保护下完成,唤醒操作本身并不需要再持有锁。
Q:为什么“唤醒本身不需要锁”?
条件变量的唤醒一般放在锁外,是因为唤醒本身不涉及共享状态的访问,如果在锁内唤醒,被唤醒线程会立刻竞争互斥锁,很可能再次阻塞,造成不必要的上下文切换;只要在锁保护下完成状态修改,再释放锁后进行通知,就能保证线程被唤醒时条件已满足且可以立即继续执行,
例子:
在锁内 notify( ❌)
{
std::unique_lock<std::mutex> lock(m);
ready = true;
cv.notify_one(); //在锁内
} // 这里才释放锁
会发生什么?
1️⃣ 线程 B 调用 notify_one
-
操作系统把线程 A 标记为 “可运行”
2️⃣ 线程 A 被唤醒
-
但 必须先重新 lock(m) 才能从 wait 返回
3️⃣ 问题来了:
-
mutex 还在 B 手里 ❌
-
A 只能 再次阻塞在 mutex 上
B 退出作用域,释放锁
- A 再次被调度
- 才真正继续执行
结果:
- A 被“唤醒了一次”
- 但立刻又被“卡住”
- 多了一次上下文切换
这就是那句话的意思:
“刚唤醒 → 又睡回去”
stop
判断线程池是否运行 --> 正在运行则置标志位为false --> 唤醒所有线程(如果任务队列中有任务,就会将任务队列中的任务执行完) --> 等待所有线程退出
//停止线程池
void stop()
{
{
std::unique_lock<std::mutex> lock(_mutex);
if(_is_running == false) return;
_is_running = false;
}
_cv.notify_all();
//等待线程退出
for(auto& thread : _threads)
{
thread.join();
}
}Q: 为什么需要将对 _is_running 的操作放在锁内?
即便是 _is_running 为 atmoic ,由于多线程之间读写并发,只要一个变量被多个线程访问,
且至少有一个写,就必须同步。将其读写放在互斥锁保护下,可以避免数据竞争并保证状态变化对所有线程可见,从而防止线程无法正确退出或发生未定义行为。
总结
- 构造时创建threadnum 个 线程 (传入线程的入口函数entry) --> 向任务队列中push 任务 --> 关闭线程池 (stop)
- entry: 循环(直到任务队列为空&&结束线程池才退出循环)、临时数组swap任务、锁外执行任务
- push: 模板、万能引用、decltype、bind、完美转发、package_task包装任务、获取future、将任务放入任务队列中(先判断线程是否结束,未结束才放入)、锁外唤醒线程(避免无效的上下文切换)、返回
- stop : 判断状态、唤醒所有线程(将任务队列中的任务执行完)、等待线程退出

















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









