




Hologres 查询优化过程实战
0 hologres 高可用治理

0.1 建表优化
hologres建表的分布键设置是充分发挥Hologres性能潜力的重要手段之一,合理的分布键设置可以在如下几个方面发挥重要的作用。
- 提高查询性能:通过合理选择分布键,可以确保查询操作尽可能地在单一分片上执行,减少跨节点的数据传输,从而加快查询速度。
- 均衡数据分布:良好的分布键能够保证数据均匀分布在各个节点上,避免某些节点成为瓶颈或出现存储热点问题,确保系统整体的高效运行。
- 优化写入效率:当数据写入时,如果分布键选择得当,可以使数据均匀分散到不同的节点,减少单一节点的压力,提高写入效率。
- 支持高并发:合适的分布键有助于实现负载均衡,使得系统能够更好地支持高并发场景下的查询和写入操作。
- 提升资源利用率:通过优化分布键,可以更有效地利用集群中的计算和存储资源,降低总体拥有成本。
优化必备知识点:
在阿里云 Hologres 中,distribution_key、clustering_key、segment_key 和 bitmap_columns 是四个关键的表结构优化参数,直接影响查询性能、存储效率和数据分布。

0.2 hologres配置优化

0.3 TG拆分
通常ads和维度表建议使用不同的TG,本质来说是将资源充分利用,不浪费资源。
不同的tg分配的shard数量不同,一般ads表使用的shard数多,dim表使用的shard数少
如果ads里表的数据量差异很大,也可以再次拆分tg来存储
0.4 shard数量和副本大小配置
- 理论上计算组的计算节点数要大于副本数。如某个tg的副本数是5, 相关计算组的资源至少是 5*16 = 80CU
- Shard 数 ≥ Worker 数的 2-3 倍
- shard是否倾斜,尽量避免倾斜
0.5 serverless与配置查询队列属性
- max_concurrency:最大并发数。默认值:-1,表示没有任何并发限制,取值范围:[ -1 , 2147483647 )。
- max_queue_size:最大排队数量,指支持的最大排队SQL数量。默认值:-1,表示队列无限大,取值范围:[ -1 , 2147483647 )。
- queue_timeout_ms:最长排队时长(单位:ms),即在排队时长超过该值时,将自动关闭查询。默认值:-1,表示不限制排队时长,取值范围:[ -1 , 2147483647 )。
当前每个计算组都分配有一个default queue,所以默认都是提交到default queue上。
可以支持配置规则,通过规则将查询路由到不同的query queue上。
当前支持的条件属性: - user_name
- command_tag
- db_name
- engine_type
- digest 针对BI场景,可能合适的使用场景
- storage_mode。
- serverless或者query queue都是独立一块资源出来单独使用。区别是serverless不受实例影响,query queue受实例影响。
- 适合的场景是个别极大查询无法优化,极耗资源。这类可以使用serverless或者query queue来查询。
- 不太适合于容灾资源,主要是因为serverless为每个查询分配了固定的cu,不支持高并发的场景
0.6 服务端查询治理
服务端和数仓的数据架构是整体服务高可用至关重要的一环。需要考虑如下几个点的平衡。
- 展示数据时效性:缓存机制
- DB压力:是否是所有的查询都要下发到DB,比如有限个数据的分组和整体数据是下发2个查询,还是1个查询,服务端计算汇总。
- 服务端运维便捷性:是否是所有的逻辑都在服务端进行计算转化,服务端过渡设计,也会导致后期维护困难
- 可扩展性:一个数据表尽量配置一个mapper的方法或者一个北斗模型,通过服务端参数动态传入进行可扩展性延伸
- 设置合理的缓存机制
- BI级缓存,针对时效性不高的数据楼层设置更久的缓存过期时间
- SQL级缓存,根据不同的入参设置1min缓存过期时间,整体缓存命中率日常在40%-50%之间
- 减少数据库查询次数
- 优化服务端代码,合并查询请求,把部分数据处理逻辑放到服务端,减少数据库查询请求
- 优化BI层dubbo接口重试配置,减少无效的数据查询
- 页面楼层延迟加载
- 前端最早是一次性将工作台首页的接口一次性请求,优化方式是对首页接口进行分组,分批次请求。由并行请求优化为【串行+并行】。减轻服务端和DB的压力。
- 前端选择需要的指标请求服务端,按需请求DB
- 服务端按需路由请求
- 根据业务需求,选择需要的指标,动态生成查询SQL。
0.6.2 设置合理的超时时间

1 分析查询过程
这里涉及到两部分东西 ,一个是表的存储 也就是建表时侯的各种参数,另一个是表的查询,我们分开讨论,分开分析。
这种东西如果不知道从哪里入手,那么从使用往回推是肯定没问题的,我们默认啊的字段是按照三范式来做的,也就是说 不考虑字段的冗余存储,这总情况下直接先从使用处 往回倒推肯定没毛病好吧。
1 使用分析命令 分析查询sql
说的简单点 分析执行命令 使用 EXPLAIN analyze 分析查询语句,我们可以看到每个语句分别在做什么,分别触发了什么索引。
索引这个东西,在不关注的时候没甚么用,单节点部署的hologres也没甚么用,但是在shard数,数据量,表的维度 ,等等某些东西多的时候,他的作用就会不知不觉的显现出来,例如 十几万的查询,如果索引设置的不合理,可能需要查询 1000多ms,如果合理的话 可能100ms就足够了,这是1000%的查询性能提升啊,如果一个app的页面又50个接口,每个接口查5个表,这个提升可就大了,所以索引如何设置 ,每种索引有什么作用 可以参考我的 另一篇帖子 。:hologres 建表/索引/查询优化,或者背诵下图:
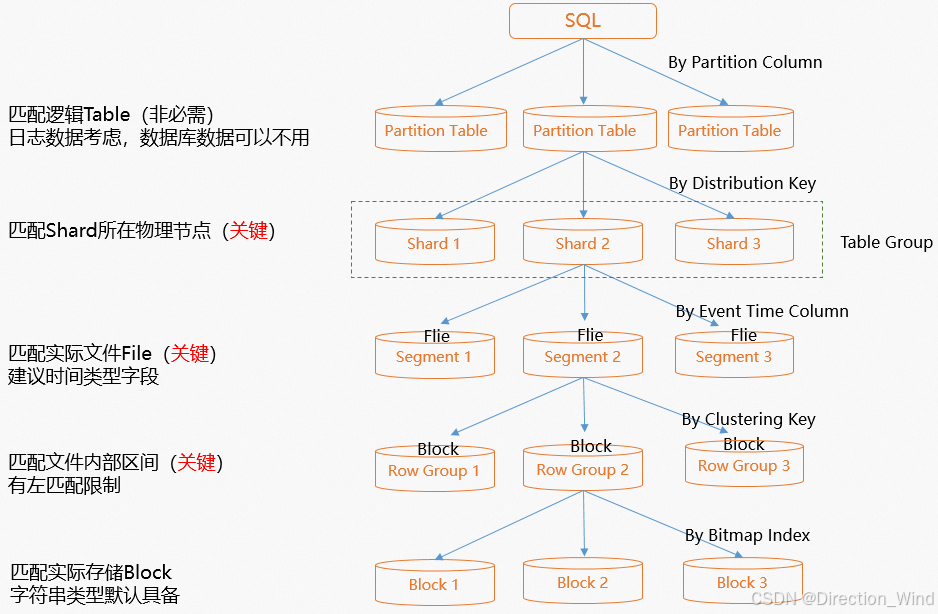
那么好 我们实战来看一下

根据分析结果 我们看下
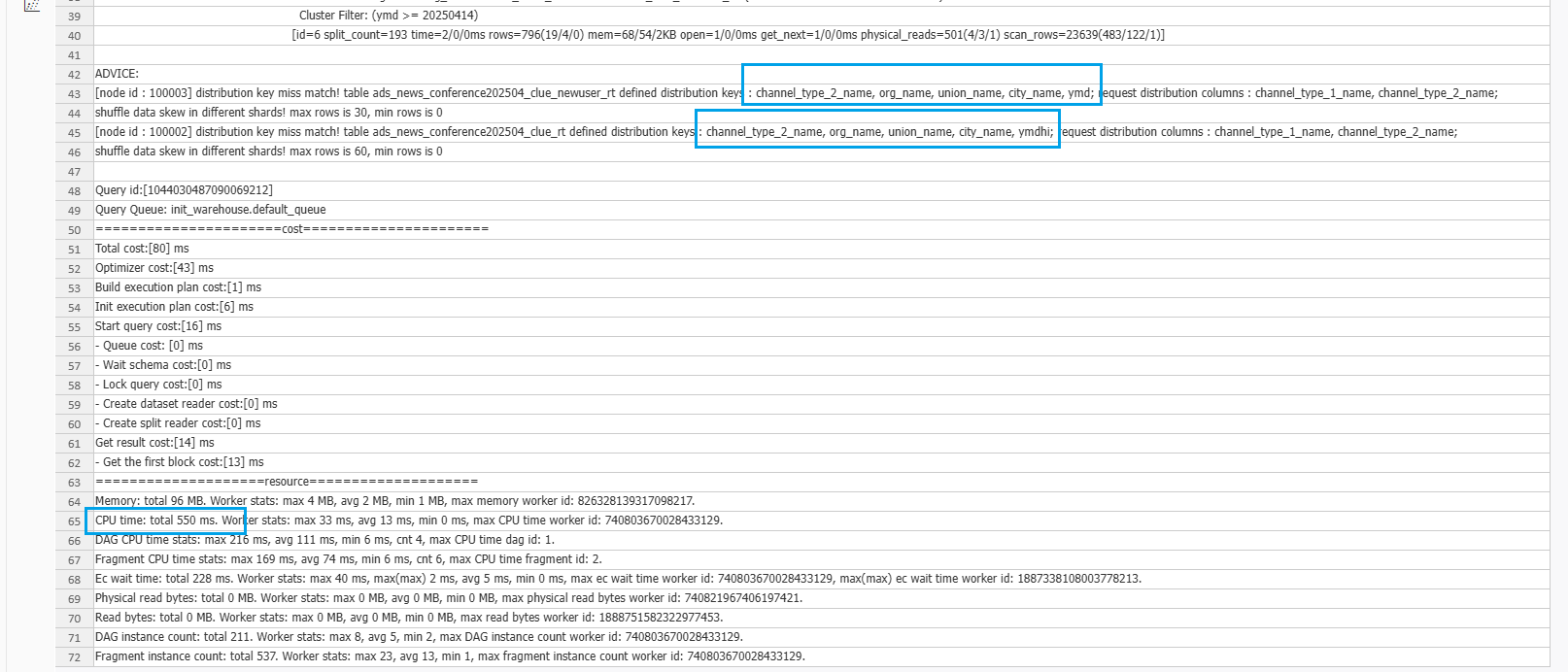
说了什么呢,说我们的 distribution_key ,没有被命中,这个索引的设置记住几个词,尽量分散,尽量全部命中,尽量别超过2个,一定是主键的子集。所以我们按照他的优化结果来
把distribution_key 也就是 存储的分布键,设置为他说的两个字段,之后再分析
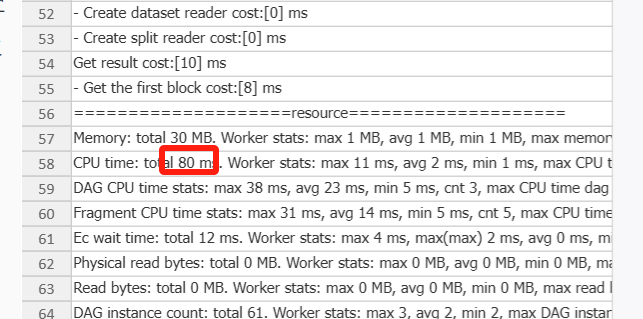
足够明显吧
这里附上表的索引设置
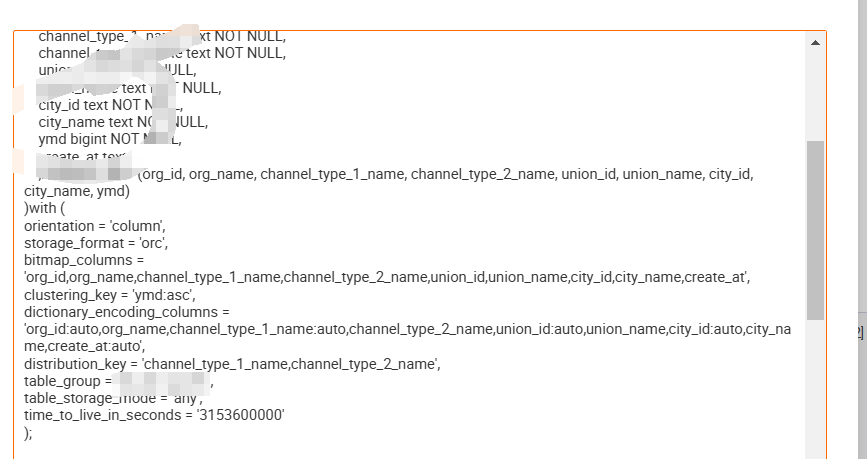
2 查询优化命令
这里是说 hologres 在不停更新,他每个版本都有一些新的能力,如果升到3.1,会有一些能力。
例如 我们可以配置以下参数,来减少查询时候的 数据shuffle。
常用的SQL性能优化参数:
–关闭数据重分布
– set optimizer_enable_motion_redistribute = true;
–关闭cache
set hg_experimental_enable_result_cache = off;
set hg_experimental_enable_query_use_block_cache = off;
–开启hint语法支持
SET pg_hint_plan_enable_hint=on;
–打开详细执行计划
– set hg_experimental_show_execution_statistics_in_explain = on;
–常规执行计划
Explain Analyze
–巨详细执行计划(JSON)
– explain (format pb)
指定query关闭数据重分布,降低shuffle消耗方法:
SET pg_hint_plan_enable_hint=on;
WITH dim_sale_org AS (
SELECT/*+HINT set(optimizer_enable_motion_redistribute off) */
3 数据计算组
这里是什么意思呢,数据表在存储的时候是要设置数据计算组的,hologres 1个workder,16个cu,1个workder最少1个shard(数据分片数)如果没有shard,那这个workder就无法被配工作。
但是如果你的表数据量很小,shard还比较多的话,他就会被分散到很多的shard中,反而降低了效率,所以可以设计几个数据计算组,分别有不同的shard数,小表设置的计算组shard数量少,大表设置的计算组的shard数量多。一方面可以做资源隔离,另一方面提高计算效率
4 hologres 大量点查 也就是 flink lookup join holo表
hologres 一般都是与flink一起使用,所以hologres表做 flink的 lookup join 维表也是常见场景,有人应该发现了,如果用hologres维表 ,有时候任务会阻塞死,这种情况是因为维表 join的键不是表的主键,这种情况会发生阻塞,实际上还是大量点查导致的。
5 定期巡检分布键
1、查hologres.hg_table_info 这张表,抠出来里面的distribution_key,然后常见字段匹配(ymd等等)+人工确认结合
2、计算组10里面加新的巡检任务,去统计每张表的数据分布是否存在数据倾斜,select hg_shard_id, count(1) from bi_car.ads_wide_ord_pipeline_ssu_price_rt_yu7sale group by hg_shard_id; 然后比一下偏差情况
可以配置单worker cpu打满告警和倾斜告警
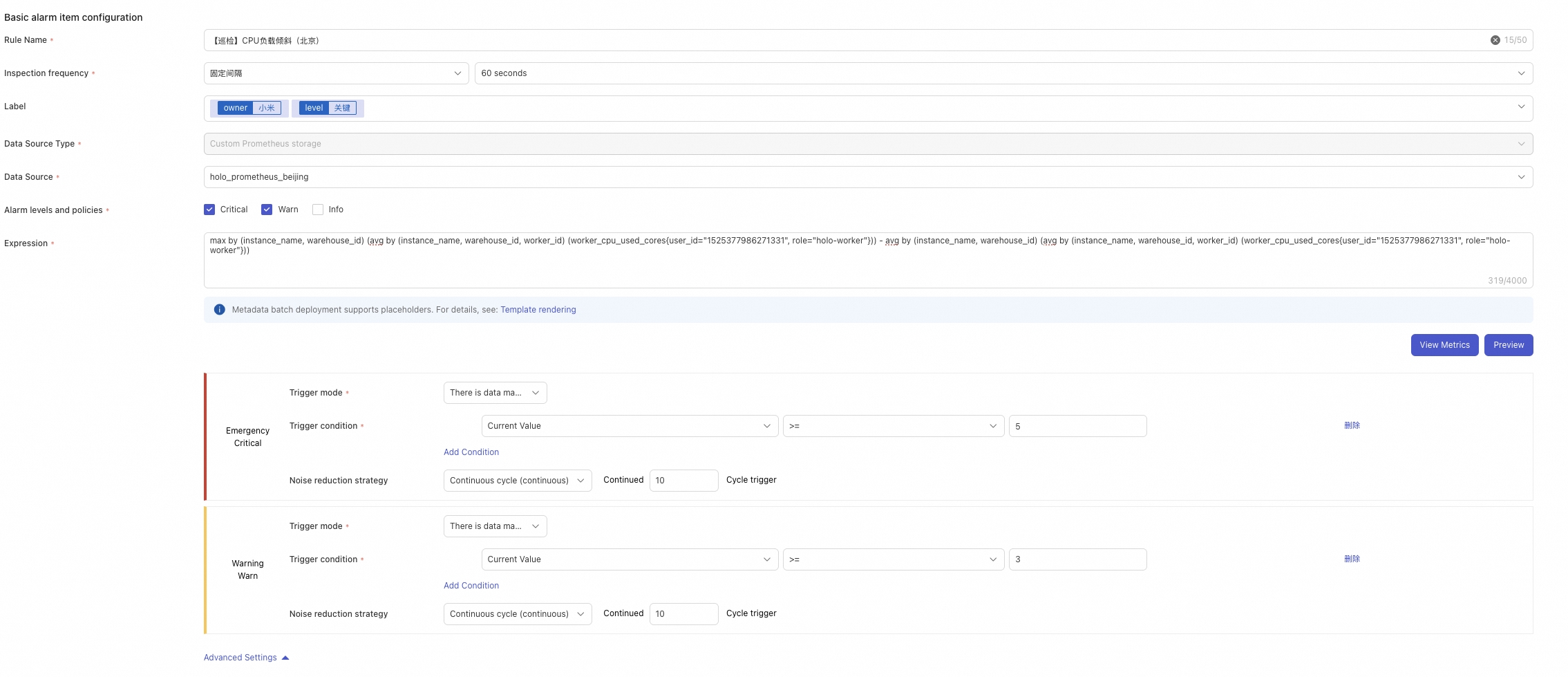
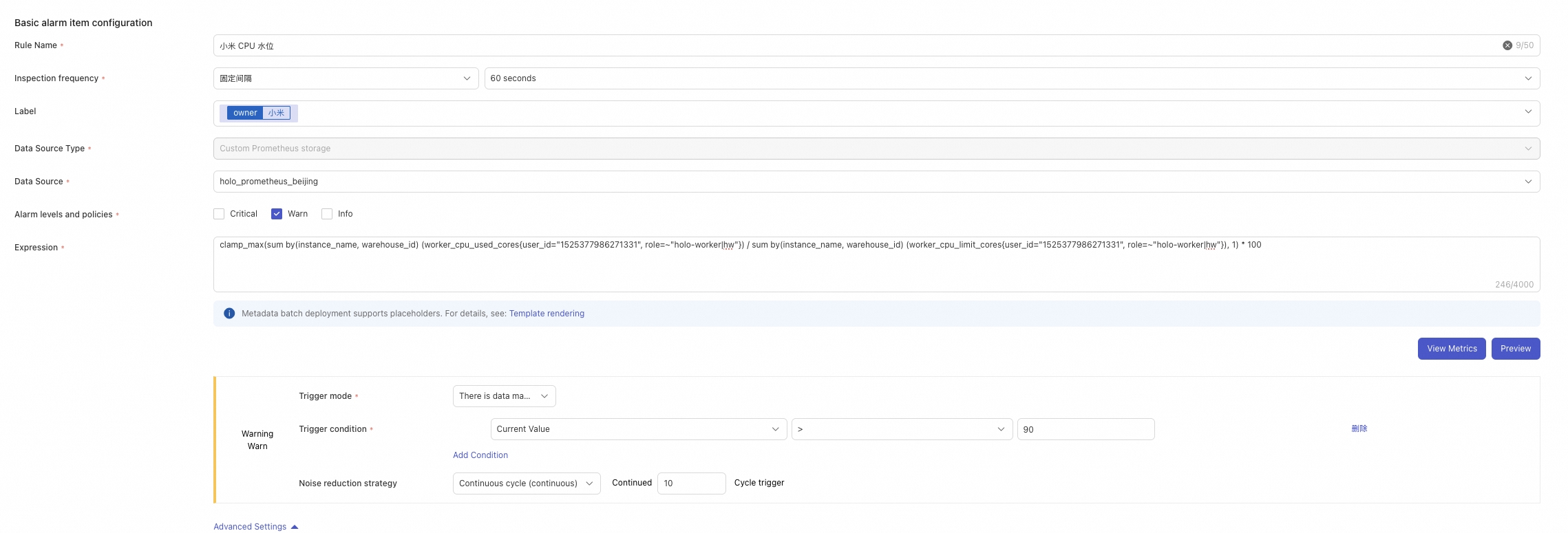
6 查看holo实时写入情况
select
query,
command_tag, count(1), avg(cpu_time_ms)::bigint, sum(cpu_time_ms)::bigint
from hologres.hg_query_log
where 1 = 1
and query_start >= ‘2025-05-21 13:20:00+08’
and query_start <= ‘2025-05-25 02:42:00+08’
group by 1,2
order by 2 desc
limit 100;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











