




项目背景
随着人工智能技术的飞速发展,机器学习训练已成为推动行业智能化转型的关键力量。这些大模型以其强大的语言理解和生成能力,在自然语言处理、图像识别、智能推荐等多个领域展现出极大的潜力。然而,机器学习的训练与部署对存储系统提出了前所未有的挑战。海量的训练数据、复杂的模型结构以及高频的数据读写需求,使得传统的非结构化存储方案难以胜任。
滴滴不断致力于提升用户体验,积极拥抱人工智能技术,在探索过程中,也遇到了数据存储与处理的瓶颈。传统的存储系统往往只支持单一协议,数据在不同协议间的转换不仅耗时费力,还极大地影响了机器学习模型的训练效率和部署速度。具体问题表现如下 :
机器学习等业务数据非常多,最少百PB级别存储量,主要小文件为主,基本上每个卷文件数达到几千万到百亿之间。
提供一定性价比。充分利用资源的同时有不错的性能,通常元数据延迟在10MS以下,带宽吞吐要求百GB以上。
机器学习等业务希望拥有对象存储的易用性,又能支持文件系统,同一份数据能支持多协议无损访问互通。业务通常会把需要训练的大模型、机器学习数据通过S3协议上传,通过机器学习的POSIX协议挂盘训练,过一段时间后自动删除,降低数据在多存储系统迁移成本、训练效率和数据管理成本。
支持云原生,同一块的机器学习数据盘,会被1万个容器根目录或子目录挂载读取。
多团队之间高效利用同一集群同一份数据且互不干扰。用户使用不同协议访问数据,不同权限管理数据保持数据不被影响干扰,最典型是A用户上传数据后,不希望B用户有权限删除。
为了满足业务需求,我们总结了新一代的非结构化存储系统,最少需要满足以下几个特性:
最少要支持百PB以上数据存储。
单卷或桶需要支持百亿级别的文件存储。
高性能低延迟的元数据存储服务,写控制2MS以内,读控制在10MS以内。
高并发高吞吐的存储底座,带宽吞吐要求百GB以上。
支持云原生,基于CSI插件可以快速地在Kubernetes上使用。
支持多租户,充分利用物理资源,同时支持相应的QoS能力来保证租户之间隔离。
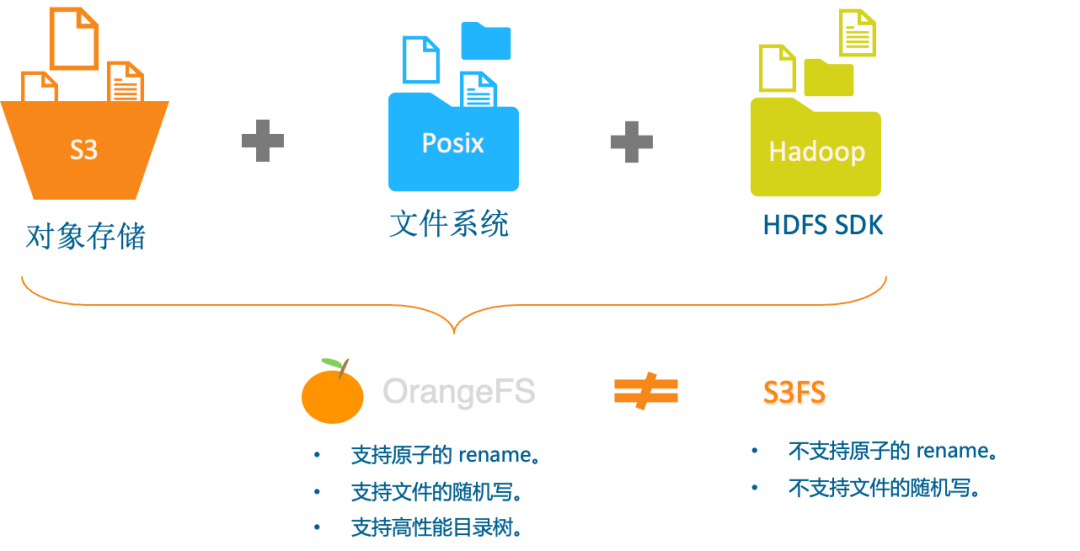
多协议无损融合互通,实现Posix、S3、HDFS三种不同存储协议无损访问互通。
支持多云架构,充分利用公有云能力,能保证云上云下架构一致,应用与不同的场景,云下可以使用滴滴自研的存储引擎,云上可以使用AWS S3、阿里云OSS、腾讯云COS、谷歌云等。
方案探索
探索已有存储
我们对滴滴内部现有的非结构化存储来探索否满足以上特性?
GIFT对象存储系统:自研的对象存储,起源于滴滴基础平台,项目2016年9月开始建设,我们2017年4月开始接手,目前分成2.0和3.0版本, 2.0支持百亿级小文件系统,3.0兼容S3协议。这系统支持多租户、百PB以上数据存储、单桶最高支持百亿级文件数、高并发高吞吐存储底座、兼容S3协议。但是不支持POSIX协议、也不支持HDFSF协议、更不支持多协议融合,所以不满足需求。
Ceph存储系统:提供对象、块、文件等存储系统,但文件和对象是两个独立系统,数据迁移成本高,不满足需求。
HDFS开源项目:主要离线hadoop大数据生态场景,大文件存储为主,不满足需求。
GlusterFS开源项目:只POSIX协议的文件存储,性能满足需求,但不支持多租户、不支持HDFS协议、不兼容S3协议、不支持多存储语义、同时单卷容量也不满足需求。
探索多存储组合
通过上面单一系统结论,发现滴滴内部的单个非结构化存储系统是不满足需求,所以我们是不是可以考虑多个系统组合支持来解决业务问题,我们的组合方案:GlusterFS文件系统 + GIFT对象存储方案 和 类S3FS + GIFT对象存储方案。
将大批量的机器学习数据存储到GIFT对象存储系统中,需要训练时,再将需要训练的数据集复制到GlusterFS文件系统中,由机器平台挂载训练。
随着训练集数据越来越多,需要复制数据集占用整体训练时间比例越来越长。
GlusterFS文件系统支持数据盘的容量也越来越不满足训练需求。
同时数据在GlusterFS和GIFT对象存储都需要各存储一份,也比较浪费空间。
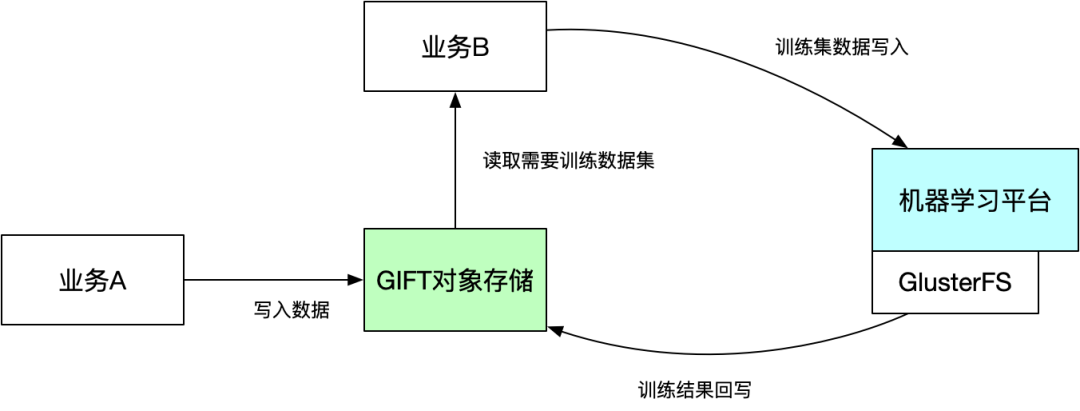
我们思考,是不是可以直接用一套系统来实现,上面实现S3和POSIX协议,这样就解决掉空间浪费和数据复制效率等问题。所以,我们就开始探索GIFT对象存储基础上直接使用类S3FS的文件系统。但又带来另外2个新的问题,即:无法提供原子的 rename 和 随机写,具体如下:
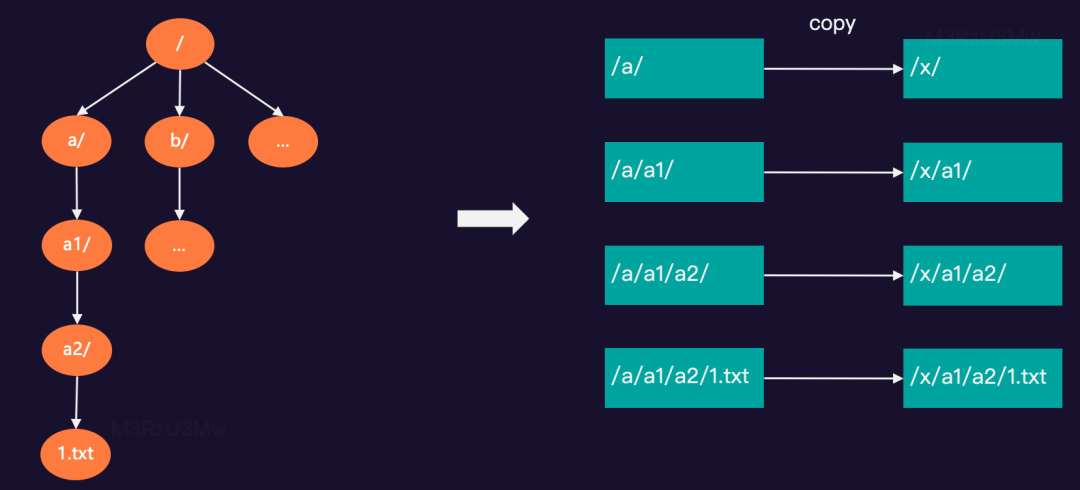
基于GIFT对象存储实现的S3FS,可以把 GIFT的 bucket 挂载到系统中以 POSIX 方式访问,但无法提供原子的 rename。例如:在test桶中有“/a/a1/a2/1.txt…”等文件,需要rename根目录下的a/文件夹为x/。
同时对随机写的操作也非常重,需要对整个先文件下载下来,修改后在重新上传到对象存储中。
探索业界方案
无论是使用已有单个存储系统,还是多个存储系统组合,都不能完美解决业务问题,所以我们开始探索业界的解决方案:Juicefs+RDS+Gift对象存储系统
JuiceFS 是个非常优秀的分布式文件系统,它兼容Posix、S3和HDFS协议,同时支持云原生。我们在社区版JuiceFS本的的基础上支持多租户、黑洞,超时、异步写等能力,满足了我们DBPROXY业务日志存储1PB左右存储需求。但应用于机器学习、大模型训练这类的场景还是有些问题,具体如下:
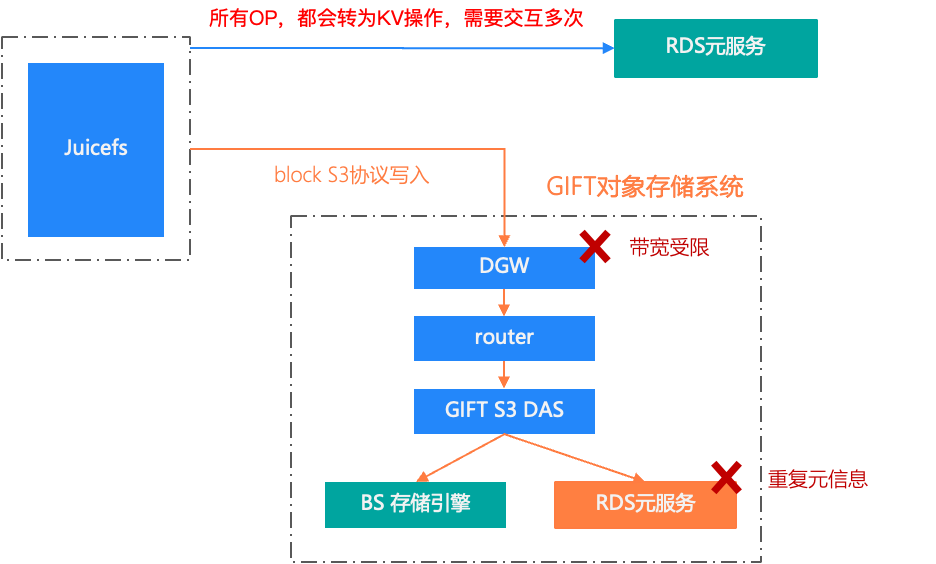
社区版JuiceFS使用RDS存储元服务,主从同步本身有延迟,所以我们使用主库写,备库读会读写不一致问题,如果直接切到主库读写压力又非常大。
所有的OP操作都会被转为KV,需要多次与RDS元服务交互,延迟相对比较高。
读写数据块的链路比较长。读一个数据块,需要经过GIFT多层才能到的BS存储引擎,同时GIFT本身也需要元服务,在加上JuiceFS元数据,就存在两份元信息。
所有流量都要经过GIFT的DGW服务,而DGW的带宽是非常有限,无法最大化的利用机器网带宽。
新一代存储
OrangeFS 新一代存储系统设计吸收探索方案的经验,同时研究并吸取了 Ceph、HDFS、CubeFS、JuiceFS、seaweedfs(Facebook haystack思想)等开源的设计思想,结合GIFT对象存储等原架构的设计思想和线上实践经验基础上演进。
复用GIFT技术
GIFT是滴滴自研的对象存储系统,从2017年接手以来,自研的2.0发版至今已支撑滴滴千亿级别大小文件存储,单桶最高达百亿级。这个系统主要由协议层、配置中心,RDS元数据、数据存储引擎等子系统组成。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









