





背景
近年来,基于观测数据的因果推断在补贴定价等领域得到广泛的应用,其旨在评估不同处理变量( Treatment,例如优惠券金额)对结果变量(Outcome,例如GMV)所能带来的处理效应(Treatment effect),进而我们能够根据不同处理效应选择最优的处理变量。在网约车市场下,我们常常关注短期处理效应和长期处理效应:
针对短期处理效应,已经有许多成熟的模型可以使用,例如DML、GRF、CFR等。
针对长期处理效应,我们发现现有方法难以直接应用在复杂的商业环境下。因为现有方法依赖于理想假设(二元策略变量或不存在未观测混淆变量)去估计长期平均处理效应(Long-term average treatment effect)。然而,在真实市场环境下,上述理想假设容易被违背,同时平均层面的长期处理效应不足以提供个性化的决策。
本文旨在解决更普遍的长期处理效应估计问题,即在考虑连续处理变量和未观测混淆存在的情况下,估计长期异质性剂量-响应曲线(Long-term Heterogeneous Dose-Response Curve,简写为Long-term HDRC)。本文将对滴滴在这一领域内的研究成果做一个简单介绍,更多内容详见论文[1]。
上述Long-term HDRC的估计问题存在以下两大挑战:
目标估计量的可识别性问题。该问题主要是因为长期历史观测数据存在未观测混淆变量,导致可识别性假设不满足。因此研究如何引入短期随机试验数据,通过数据融合的方式消除长期历史观测数据中未观测混淆的影响,是我们首要解决的问题。
反事实估计误差的问题。该问题主要是因为连续处理变量导致反事实空间巨大,若简单拟合长期历史观测数据这一事实数据,学到的估计器很难有效泛化到反事实空间。因此如何推导Long-term HDRC下的反事实估计泛化界限,并基于此设计估计器,是我们面临的第二个问题。

问题设定
我们使用符号A表示一维的连续处理变量,X表示可观测的混淆变量,U表示未观测的混淆变量,S(a)表示不同时间步
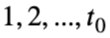
下的潜在短期结果向量,Y(a)表示时间步T下的潜在长期结果。使用大写字母表示随机变量,小写字母表示随机变量的取值。考虑数据融合的场景,即拥有大量的长期历史观测数据
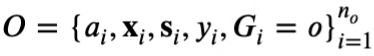
和少量的短期随机试验数据
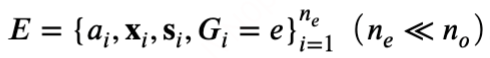
引入
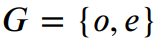
作为数据集的指示变量。注意两类数据中均包含处理变量A、混淆变量X及短期结果S,而长期结果Y仅存在于长期历史观测数据中。基于这两份数据,我们的目标是学习估计器以无偏估计个体在不同处理变量下的长期结果,即长期异质性剂量-响应曲线(Long-term HDRC):
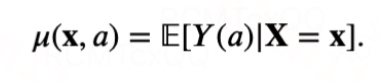
目标估计量Long-term HDRC无法单独从短期随机试验数据或长期历史观测数据识别,因为前者缺失长期结果Y,后者存在未观察到的混淆变量U。为此,我们提出基于数据融合的长期异质性剂量-响应曲线估计框架,除了经典的SUTVA(假设1)和Overlap(假设2)之外,还需要以下关键假设:
假设3: 对于观测数据,给定全部混淆变量X和U,处理变量A和潜在结果S(a), Y(a)独立,形式化地,有
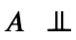
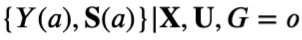
且
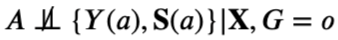
假设4: 对于实验数据,仅给定可观测混淆变量X,处理变量A和潜在结果S(a), Y(a)独立,形式化地,有
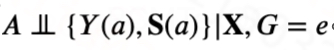
假设5: 给定可观察的混淆变量X,潜在结果S(a), Y(a)的分布在实验数据和观测数据中保持一致,形式化地,有
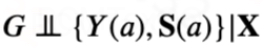
假设6: 对于观测数据,给定可观察的混淆变量X和潜在短期结果S(a),处理变量A与长期潜在结果Y(a)相互独立,形式化地,有
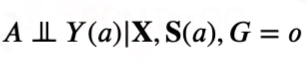
假设1~4都是因果推断领域常见的假设。假设5保证不同数据类型𝐺之间潜在结果的条件分布相同,这个假设是合理的,因为实验数据和观察数据之间的差异通常是处理分配机制,而潜在结果分布保持不变且稳定;假设6未观测混淆U的影响被短期结果S所阻断,即不存在U->Y的边,该假设最初由Susan Athey在[2]中提出以实现二元处理变量下长期平均处理效应的识别,在本文我们重新利用该假设实现更复杂的Long-term HDRC识别。满足上述假设的因果图如下所示:
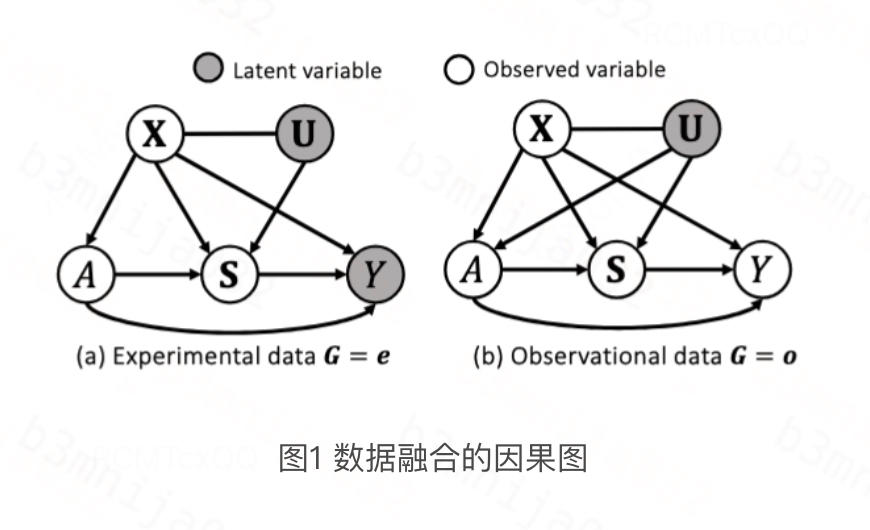

理论框架
挑战一:目标估计量的可识别性
为了实现目标估计量的可识别性,首先需要解决长期历史观测数据中未观测混淆的影响。在本小节,在理论上提出一种新颖的加权方案使得目标估计量Long-term HDRC可识别,接着提出一种带有理论保证且计算高效的最优传输(Op
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









