




背景
因果推断的关键是实现对目标估计量(例如平均处理效应ATE,Average Treatment Effect)的估计,在标准三大假设(SUTVA、Unconfounderness、Overlap)满足的情况下,目标估计量具有可识别性,因果推断问题自然也就转化为一个统计推断问题。因此,我们关注的是如何实现对目标估计量的有效估计(efficient estimation),即如何构建一个具有最小方差的最优无偏估计器。在半参数理论框架下,已有两类估计器被广泛探索应用:DR(Doubly Robust,双重鲁棒)估计器和TMLE(Targeted Maximum Likelihood Estimation,目标极大似然估计)估计器。DR估计器在原始插入估计器(Plug-in estimator)减去偏差项实现有效估计,而TMLE则是对原始分布进行扰动(在有限样本下,TMLE往往比DR估计器更加稳定)。在TMLE的基础上,Dragonnet[1] 设计了目标正则化(Targeted regularization),将TMLE理论嵌入到了神经网络的损失函数设计中,构建了二元处理变量场景下端到端的基于神经网络的有效估计器,VCNet[2] 则提出了函数目标正则化,将这一框架拓展到了连续处理变量的场景。
然而,虽然上述基于神经网络的有效估计器在实践中取得了显著进展,但是它们局限于高斯分布的结果变量。在业务场景下,我们面临的往往是其他类型的分布。例如在推荐场景下,“是否喜欢”服从的是伯努利分布;在滴滴网约车场景下,“发单量”服从的是泊松分布……因此,我们希望对目标正则化这一技术进行改进,克服其高斯分布假设的局限性,设计一个更加通用的,能够面向指数族分布结果变量的新目标正则化项。
为了实现上述目标,我们需要依次解决以下问题:
目标估计量定义:如何在一个统一框架下定义指数族分布的因果效应?我们将在第二节回答这个问题。
偏差分析:对于指数族分布,其plug-in估计器的偏差是什么?我们将在第三节回答这个问题。
偏差修正:如何修正上述偏差,得到有效估计器(efficient estimator)?我们将在第四节回答这个问题。
本文将对滴滴在这一领域内的研究成果做一个简单介绍,更多内容详见论文[3]。

问题设定
我们使用符号A来表示一维的处理变量,A可以是{0, 1}取值的二元变量,也可以是[0, 1]范围内的连续变量,X表示混淆变量,Y表示结果变量,其服从单参数的指数分散族(EDF,Exponetial Dispersion Family )如下所示:
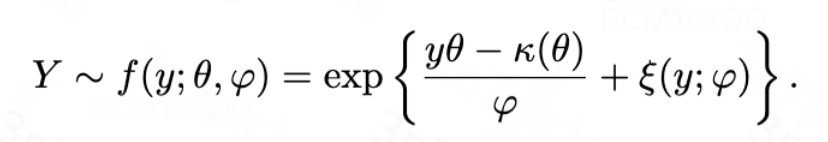
其中,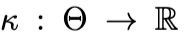 是累积函数(cumulant function),
是累积函数(cumulant function),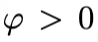 是分散参数(dispersion parameter),
是分散参数(dispersion parameter),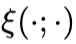 是归一化项,
是归一化项,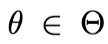 是自然/规范参数(natural/canonical parameter,下称自然参数),其可被建模为
是自然/规范参数(natural/canonical parameter,下称自然参数),其可被建模为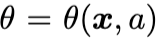
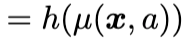 ,
,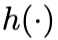 表示指数族分布中的链接函数(link function),
表示指数族分布中的链接函数(link function),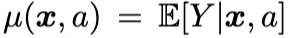 表示结果变量的条件期望。
表示结果变量的条件期望。
因此,在指数族框架下,参考[4]在自然参数尺度统一定义目标估计量为EDF的平均剂量规范函数(ADCF,Average Dose Canonical Function)。
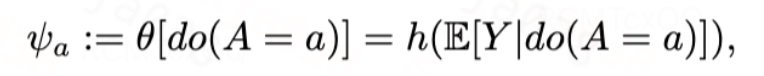
在标准三大假设(SUTVA、Unconfounderness、Overlap)满足的情况下,上述因果层面的目标估计量可转化为统计层面的目标估计量:
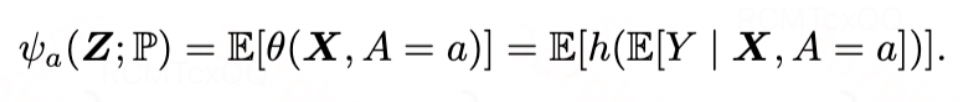

Plug-in估计器及偏差分析
对于指数族分布,其plug-in估计器的整体架构仍然遵循Dragonnet/VCNet,如下图所示:
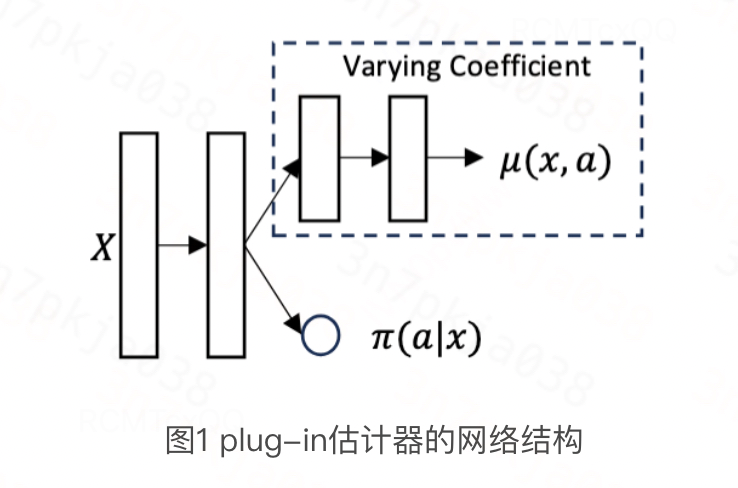
训练该plug-in估计器的损失函数如下所示,第一项表示EDF的负对数似然,第二项表示广义倾向性得分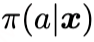 的负对数似然:
的负对数似然:
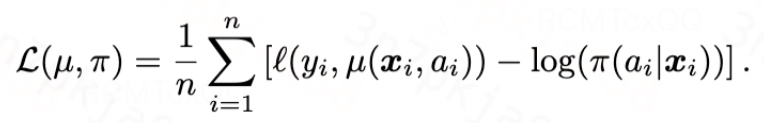
当损失函数收敛之后,我们构造plug-in估计器如下:
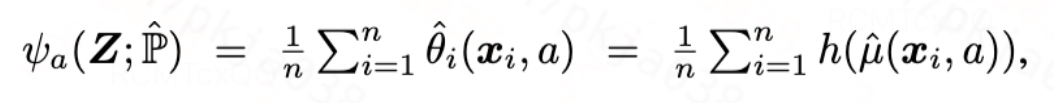
接下来,我们通过推导ADCF的von-Mises展开式,展示该plug-in估计器的偏差所在。

对于von-Mises展开式(5),其第二项是关于nuisance functions的二次项,这意味着它仅由 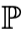 与
与 之间误差的二阶乘积构成,因此有
之间误差的二阶乘积构成,因此有 。因此,Plug-in估计器的偏差主要取决于第一项所表示的一阶偏差
。因此,Plug-in估计器的偏差主要取决于第一项所表示的一阶偏差 。
。

有效估计器的构建
DR估计器
对于plug-in估计器的偏差,一种最直观的思路就是在原估计器基础上,直接将一阶偏差减掉,如此我们便得到了针对指数族分布的DR估计器:
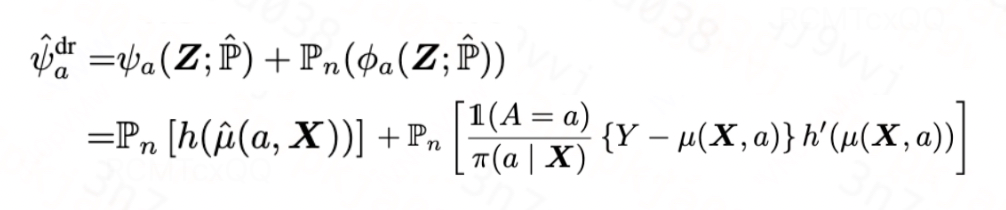
DR估计器建立在 和
和 的基础上,即使两者有一个是不一致,我们也能得到一致估计器(consistent estimator),若两者均一致,那么我们则能得到更快的收敛速率。然而,如[1, 2]中所言,由于DR估计器中倾向性得分出现在分母的位置,这会导致DR估计器在有限样本量下不稳定。
的基础上,即使两者有一个是不一致,我们也能得到一致估计器(consistent estimator),若两者均一致,那么我们则能得到更快的收敛速率。然而,如[1, 2]中所言,由于DR估计器中倾向性得分出现在分母的位置,这会导致DR估计器在有限样本量下不稳定。
目标正则化
TMLE则是另一种修正plug-in估计器偏差的方法,其通过对原始分布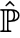 进行扰动,使其变成目标分布
进行扰动,使其变成目标分布 ,且满足目标分布
,且满足目标分布 上的一阶偏差为0,即
上的一阶偏差为0,即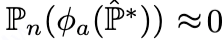 。具体地,我们学习一个新的受扰动的
。具体地,我们学习一个新的受扰动的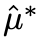 ,使得其满足
,使得其满足
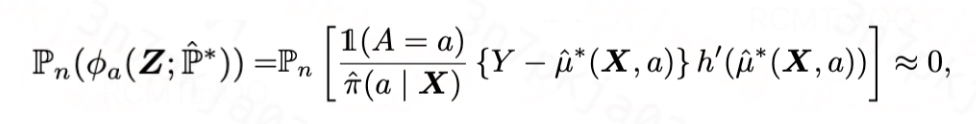
当 满足上式的时候,我们可以得到新的有效估计器如下:
满足上式的时候,我们可以得到新的有效估计器如下:
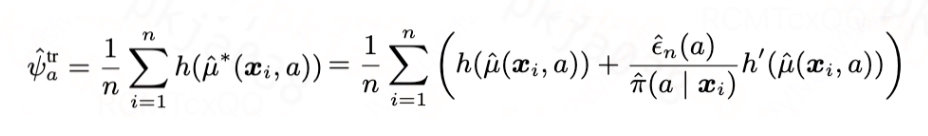
那么如何将学习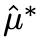 的过程设计成目标正则化项,并将其融入图1所示的plug-in估计器的损失函数中呢?我们发现,只要令该目标正则化项的导数等于一阶偏差
的过程设计成目标正则化项,并将其融入图1所示的plug-in估计器的损失函数中呢?我们发现,只要令该目标正则化项的导数等于一阶偏差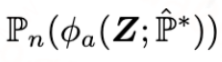 ,那么当训练使得目标正则化项收敛的时候,其导数为0,意味着一阶偏差也为0,即
,那么当训练使得目标正则化项收敛的时候,其导数为0,意味着一阶偏差也为0,即
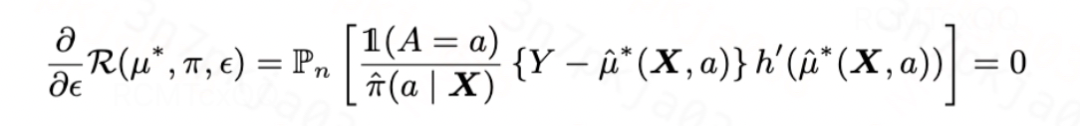
沿着这个思路,我们设计目标正则化项为
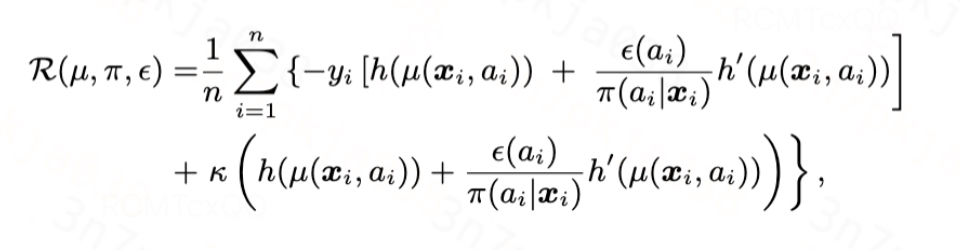
综上,基于TMLE理论,我们设计有效估计器的损失函数如下,其中第一项是plug-in估计器的损失函数,第二项是针对指数族分布的目标正则化项:
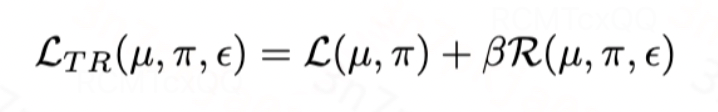
我们可以在理论上证明,当以下假设满足的时候,我们设计的估计器有良好的收敛性质:

目标正则化的具体例子
上一节已经给出了面向指数族分布的目标正则化项的通用形式。在具体实践中,只需要针对不同的分布,指定不同的累积函数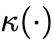 、链接函数
、链接函数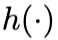 即可。
即可。
高斯分布:高斯分布的累积函数为 ,链接函数为恒等函数,代入得到
,链接函数为恒等函数,代入得到
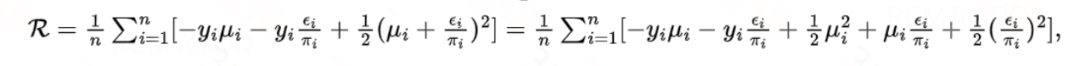
这和Dragonnet/VCNet中给出的目标正则化项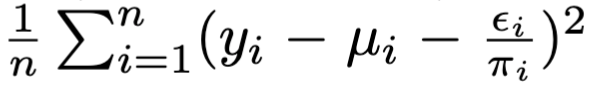 是等价的。
是等价的。
伯努利分布:伯努利分布的累积函数为 ,链接函数为logit函数,代入得到
,链接函数为logit函数,代入得到
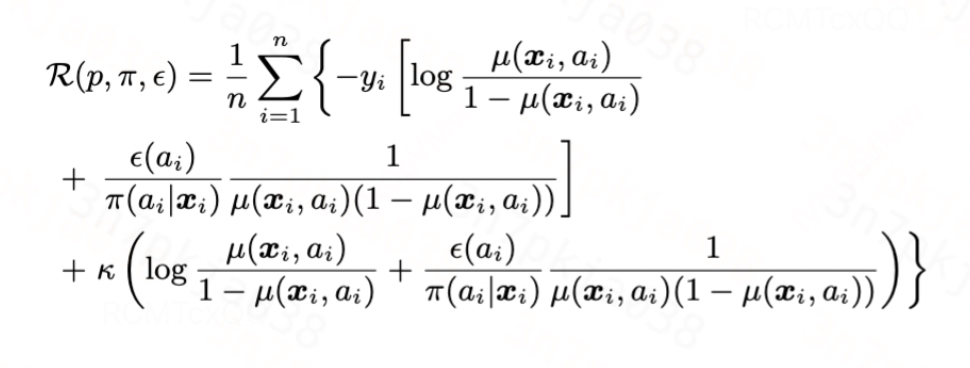
由于空间限制,此处累积函数不再具体代入。
泊松分布:泊松分布的累积函数为指数函数,链接函数为对数函数,代入得到:
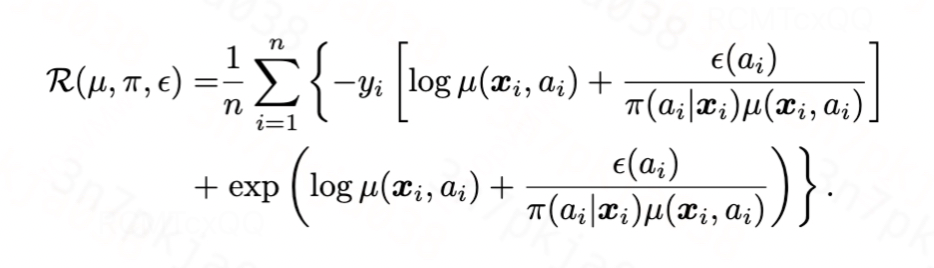

实验
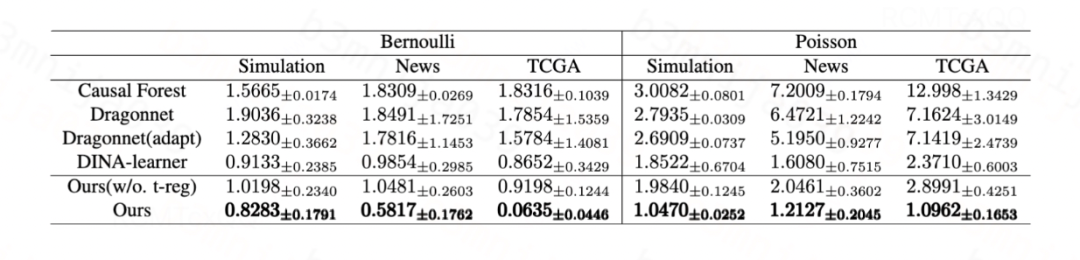
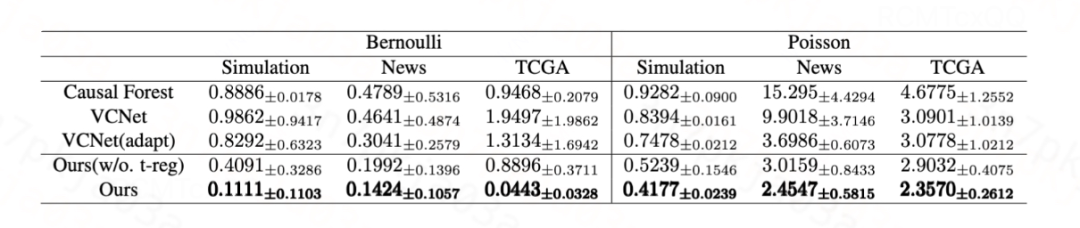
对于高斯分布,我们提出的方法和Dragonnet/VCNet中的目标正则化等价,其有效性已在[1, 2]中得到验证。对于伯努利分布和泊松分布,我们分别在生成数据和半生成数据(News、TCGA)上验证所提出的目标正则化的有效性。
对于二元处理变量,我们使用ATE的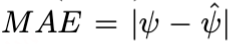 作为评估指标:
作为评估指标:
对于连续处理变量,我们使用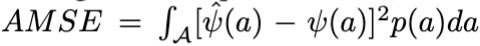 作为评估指标:
作为评估指标:
此外,该算法也已经在滴滴宏观、微观的多个因果效应估计场景中取得显著效果,被广泛应用在各类因果效应估计模型中。

总结
在本文中,我们聚焦于构建面向指数族分布的有效估计器。具体而言,我们首先对平均剂量规范函数(ADCF)进行 von-Mises 展开,揭示了指数族分布下 plug-in 估计器的一阶偏差项;基于上述理论结果,我们将函数目标化正则化技术推广至指数族情形,构建了相应的神经网络估计器,并给出了其理论收敛速率。实验结果验证了我们理论推导的正确性以及所提模型的有效性。
参考文献
[1] Shi C, Blei D, Veitch V. Adapting neural networks for the estimation of treatment effects[J]. Advances in neural information processing systems, 2019, 32.
[2] Nie L, Ye M, Nicolae D. VCNet and Functional Targeted Regularization For Learning Causal Effects of Continuous Treatments[C]//International Conference on Learning Representations.
[3] Li J, Yang Z, Dan J, et al. Treatment Effect Estimation for Exponential Family Outcomes using Neural Networks with Targeted Regularization[J]. arXiv preprint arXiv:2502.07295, 2025.
[4] Gao Z, Hastie T. Estimating heterogeneous treatment effects for general responses[J]. arXiv preprint arXiv:2103.04277, 2021.
欢迎感兴趣的同学一起加入我们
可投递您的简历至
stevenxujixing@didiglobal.com
zhenpeng@didiglobal.com
团队使命
作为网约车交易市场技术核心团队,我们应用机器学习、运筹优化、因果推断、深度强化学习及生成式AI技术(LLM) ,构建支撑千万级日订单的动态双边市场智能决策系统。通过供需预测建模、动态定价策略、智能补贴分配、生态治理引擎 等策略引擎建设,持续优化平台商业价值与司乘体验,驱动全球领先的出行市场效率革新。
供需调节策略方向的主要工作
负责设计研发面向司乘双边市场的动态定价和跨品类联合补贴策略引擎,涉及的技术方向包括:精细化的时空供需预测建模、针对海量数据的细粒度因果建模、大规模运筹优化与求解算法设计、大规模离线仿真系统设计与研发等。
负责设计研发面向用户长期增长的智能增长营销策略引擎,构建可持续优化的收益管理与增长引擎系统,涉及的技术方向包括:长周期用户价值(LTV)建模、基于强化学习的序列化决策模型设计、大规模运筹优化与收益管理系统设计等。
负责设计研发面向供需调节和用户增长的智能运营系统,构建面向多目标高度封装的全自动智能化的运营引擎,助力网约车业务精细化运营提效。涉及的技术方向包括:不同粒度、周期的时序预测建模、大规模运筹优化求解算法、支持深度人机结合的工业化运营引擎架构。
负责设计研发面向网约车交易场景的司乘生态治理引擎,构建面向不同品类业务特点的判责、治理策略系统,涉及技术包括:多模态深度学习建模、大语言模型技术、原子预测和小样本学习等技术。
基础要求
计算机/运筹学/统计学/应用数学硕士及以上学历。
深入掌握机器学习经典模型算法(统计模型/深度模型)及实际场景落地经验。
精通算法设计与数据结构,具备大规模系统开发能力(Python/Java/Spark)。
出色的复杂问题拆解能力与跨团队协作意识。
核心优势
算法研究:在机器学习、运筹优化、强化学习、因果推断等方向有论文/专利成果。
工程能力:精通Spark/Flink等计算框架,有大数据数据处理经验。
行业经验:具备定价策略/用户增长/智能营销等场景落地经验者优先。
竞赛成就:ACM/ICPC金牌、Kaggle Master等顶尖赛事获奖者。





















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









