




并发和多线程
3.1 并发基础
Java 并发 - 理论基础
Java 并发 - 线程基础
多线程的出现是要解决什么问题的? 本质什么?
CPU、内存、I/O 设备的速度是有极大差异的,为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献,主要体现为:
CPU 增加了缓存,以均衡与内存的速度差异;// 导致可见性问题
操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;// 导致原子性问题
编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。// 导致有序性问题
Java是怎么解决并发问题的?
Java 内存模型是个很复杂的规范,具体看Java 内存模型详解。
理解的第一个维度:核心知识点
JMM本质上可以理解为,Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。具体来说,这些方法包括:
volatile、synchronized 和 final 三个关键字
Happens-Before 规则
理解的第二个维度:可见性,有序性,原子性
原子性
在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。 请分析以下哪些操作是原子性操作:
x = 10; //语句1: 直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中
y = x; //语句2: 包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及 将x的值写入工作内存 这2个操作都是原子性操作,但是合起来就不是原子性操作了。
x++; //语句3: x++包括3个操作:读取x的值,进行加1操作,写入新的值。
x = x + 1; //语句4: 同语句3上面4个语句只有语句1的操作具备原子性。
也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
从上面可以看出,Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
可见性
Java提供了volatile关键字来保证可见性。
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
有序性
在Java里面,可以通过volatile关键字来保证一定的“有序性”。另外可以通过synchronized和Lock来保证有序性,很显然,synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。当然JMM是通过Happens-Before 规则来保证有序性的。
线程安全有哪些实现思路?
互斥同步
synchronized 和 ReentrantLock。
非阻塞同步
互斥同步最主要的问题就是线程阻塞和唤醒所带来的性能问题,因此这种同步也称为阻塞同步。
互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
CAS
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略: 先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
乐观锁需要操作和冲突检测这两个步骤具备原子性,这里就不能再使用互斥同步来保证了,只能靠硬件来完成。硬件支持的原子性操作最典型的是: 比较并交换(Compare-and-Swap,CAS)。CAS 指令需要有 3 个操作数,分别是内存地址 V、旧的预期值 A 和新值 B。当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。
AtomicInteger
J.U.C 包里面的整数原子类 AtomicInteger,其中的 compareAndSet() 和 getAndIncrement() 等方法都使用了 Unsafe 类的 CAS 操作。
无同步方案
要保证线程安全,并不是一定就要进行同步。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性。
栈封闭
多个线程访问同一个方法的局部变量时,不会出现线程安全问题,因为局部变量存储在虚拟机栈中,属于线程私有的。
线程本地存储(Thread Local Storage)
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行。如果能保证,我们就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
如何理解并发和并行的区别?
并发是指一个处理器同时处理多个任务。
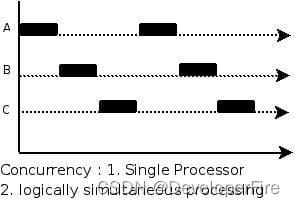
并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。

线程有哪几种状态? 分别说明从一种状态到另一种状态转变有哪些方式?
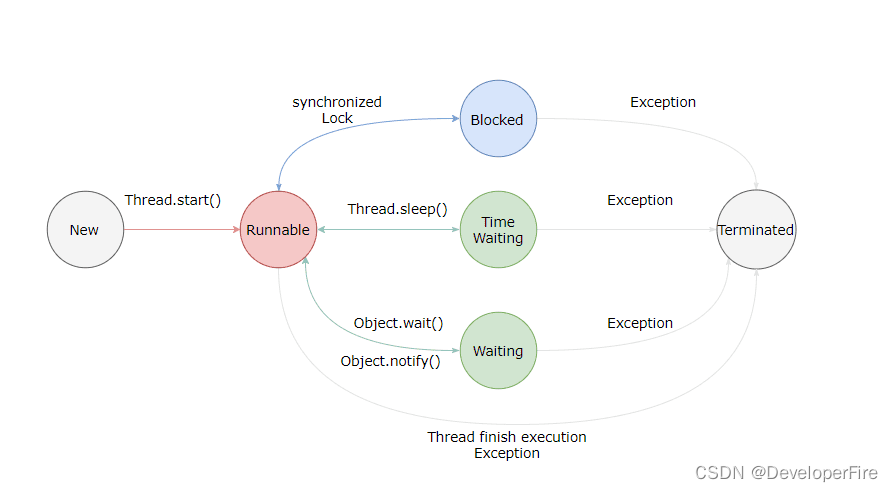
新建(New)
创建后尚未启动。
可运行(Runnable)
可能正在运行,也可能正在等待 CPU 时间片。
包含了操作系统线程状态中的 Running 和 Ready。
阻塞(Blocking)
等待获取一个排它锁,如果其线程释放了锁就会结束此状态。
无限期等待(Waiting)
等待其它线程显式地唤醒,否则不会被分配 CPU 时间片。
进入方法 | 退出方法 |
没有设置 Timeout 参数的 Object.wait() 方法 | Object.notify() / Object.notifyAll() |
没有设置 Timeout 参数的 Thread.join() 方法 | 被调用的线程执行完毕 |
LockSupport.park() 方法 | - |
限期等待(Timed Waiting)
无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
调用 Thread.sleep() 方法使线程进入限期等待状态时,常常用“使一个线程睡眠”进行描述。
调用 Object.wait() 方法使线程进入限期等待或者无限期等待时,常常用“挂起一个线程”进行描述。
睡眠和挂起是用来描述行为,而阻塞和等待用来描述状态。
阻塞和等待的区别在于,阻塞是被动的,它是在等待获取一个排它锁。而等待是主动的,通过调用 Thread.sleep() 和 Object.wait() 等方法进入。
进入方法 | 退出方法 |
Thread.sleep() 方法 | 时间结束 |
设置了 Timeout 参数的 Object.wait() 方法 | 时间结束 / Object.notify() / Object.notifyAll() |
设置了 Timeout 参数的 Thread.join() 方法 | 时间结束 / 被调用的线程执行完毕 |
LockSupport.parkNanos() 方法 | - |
LockSupport.parkUntil() 方法 | - |
死亡(Terminated)
可以是线程结束任务之后自己结束,或者产生了异常而结束。
通常线程有哪几种使用方式?
有三种使用线程的方法:
实现 Runnable 接口;
实现 Callable 接口;
继承 Thread 类。
实现 Runnable 和 Callable 接口的类只能当做一个可以在线程中运行的任务,不是真正意义上的线程,因此最后还需要通过 Thread 来调用。可以说任务是通过线程驱动从而执行的。
基础线程机制有哪些?
Executor
Executor 管理多个异步任务的执行,而无需程序员显式地管理线程的生命周期。这里的异步是指多个任务的执行互不干扰,不需要进行同步操作。
主要有三种 Executor:
CachedThreadPool: 一个任务创建一个线程;
FixedThreadPool: 所有任务只能使用固定大小的线程;
SingleThreadExecutor: 相当于大小为 1 的 FixedThreadPool。
Daemon
守护线程是程序运行时在后台提供服务的线程,不属于程序中不可或缺的部分。
当所有非守护线程结束时,程序也就终止,同时会杀死所有守护线程。
main() 属于非守护线程。使用 setDaemon() 方法将一个线程设置为守护线程。
sleep()
Thread.sleep(millisec) 方法会休眠当前正在执行的线程,millisec 单位为毫秒。
sleep() 可能会抛出 InterruptedException,因为异常不能跨线程传播回 main() 中,因此必须在本地进行处理。线程中抛出的其它异常也同样需要在本地进行处理。
yield()
对静态方法 Thread.yield() 的调用声明了当前线程已经完成了生命周期中最重要的部分,可以切换给其它线程来执行。该方法只是对线程调度器的一个建议,而且也只是建议具有相同优先级的其它线程可以运行。
线程的中断方式有哪些?
一个线程执行完毕之后会自动结束,如果在运行过程中发生异常也会提前结束。
InterruptedException
通过调用一个线程的 interrupt() 来中断该线程,如果该线程处于阻塞、限期等待或者无限期等待状态,那么就会抛出 InterruptedException,从而提前结束该线程。但是不能中断 I/O 阻塞和 synchronized 锁阻塞。
对于以下代码,在 main() 中启动一个线程之后再中断它,由于线程中调用了 Thread.sleep() 方法,因此会抛出一个 InterruptedException,从而提前结束线程,不执行之后的语句。
public class InterruptExample {
private static class MyThread1 extends Thread {
@Override
public void run() {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new MyThread1();
thread1.start();
thread1.interrupt();
System.out.println("Main run");
}
}Main run
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at InterruptExample.lambda$main$0(InterruptExample.java:5)
at InterruptExample$$Lambda$1/713338599.run(Unknown Source)
at java.lang.Thread.run(Thread.java:745)interrupted()
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt() 方法就无法使线程提前结束。
但是调用 interrupt() 方法会设置线程的中断标记,此时调用 interrupted() 方法会返回 true。因此可以在循环体中使用 interrupted() 方法来判断线程是否处于中断状态,从而提前结束线程。
Executor 的中断操作
调用 Executor 的 shutdown() 方法会等待线程都执行完毕之后再关闭,但是如果调用的是 shutdownNow() 方法,则相当于调用每个线程的 interrupt() 方法。
线程的互斥同步方式有哪些? 如何比较和选择?
Java 提供了两种锁机制来控制多个线程对共享资源的互斥访问,第一个是 JVM 实现的 synchronized,而另一个是 JDK 实现的 ReentrantLock。
1. 锁的实现
synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
2. 性能
新版本 Java 对 synchronized 进行了很多优化,例如自旋锁等,synchronized 与 ReentrantLock 大致相同。
3. 等待可中断
当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。
ReentrantLock 可中断,而 synchronized 不行。
4. 公平锁
公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。
synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
5. 锁绑定多个条件
一个 ReentrantLock 可以同时绑定多个 Condition 对象。
线程之间有哪些协作方式?
当多个线程可以一起工作去解决某个问题时,如果某些部分必须在其它部分之前完成,那么就需要对线程进行协调。
join()
在线程中调用另一个线程的 join() 方法,会将当前线程挂起,而不是忙等待,直到目标线程结束。
对于以下代码,虽然 b 线程先启动,但是因为在 b 线程中调用了 a 线程的 join() 方法,b 线程会等待 a 线程结束才继续执行,因此最后能够保证 a 线程的输出先于 b 线程的输出。
public class JoinExample {
private class A extends Thread {
@Override
public void run() {
System.out.println("A");
}
}
private class B extends Thread {
private A a;
B(A a) {
this.a = a;
}
@Override
public void run() {
try {
a.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("B");
}
}
public void test() {
A a = new A();
B b = new B(a);
b.start();
a.start();
}
}public static void main(String[] args) {
JoinExample example = new JoinExample();
example.test();
}A
Bwait() notify() notifyAll()
调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。
它们都属于 Object 的一部分,而不属于 Thread。
只能用在同步方法或者同步控制块中使用,否则会在运行时抛出 IllegalMonitorStateExeception。
使用 wait() 挂起期间,线程会释放锁。这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。
wait() 和 sleep() 的区别
wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;
wait() 会释放锁,sleep() 不会。
await() signal() signalAll()
java.util.concurrent 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
3.2 并发关键字
关键字: synchronized详解
关键字: volatile详解
关键字: final详解
Synchronized可以作用在哪里?
对象锁
方法锁
类锁
Synchronized本质上是通过什么保证线程安全的?
加锁和释放锁的原理
深入JVM看字节码,创建如下的代码:
public class SynchronizedDemo2 {
Object object = new Object();
public void method1() {
synchronized (object) {
}
}
}使用javac命令进行编译生成.class文件
>javac SynchronizedDemo2.java使用javap命令反编译查看.class文件的信息
>javap -verbose SynchronizedDemo2.class得到如下的信息:
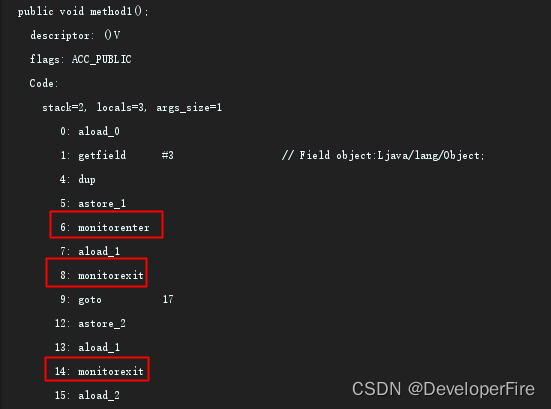
关注红色方框里的monitorenter和monitorexit即可。
Monitorenter和Monitorexit指令,会让对象在执行,使其锁计数器加1或者减1。每一个对象在同一时间只与一个monitor(锁)相关联,而一个monitor在同一时间只能被一个线程获得,一个对象在尝试获得与这个对象相关联的Monitor锁的所有权的时候,monitorenter指令会发生如下3中情况之一:
monitor计数器为0,意味着目前还没有被获得,那这个线程就会立刻获得然后把锁计数器+1,一旦+1,别的线程再想获取,就需要等待
如果这个monitor已经拿到了这个锁的所有权,又重入了这把锁,那锁计数器就会累加,变成2,并且随着重入的次数,会一直累加
这把锁已经被别的线程获取了,等待锁释放
monitorexit指令:释放对于monitor的所有权,释放过程很简单,就是讲monitor的计数器减1,如果减完以后,计数器不是0,则代表刚才是重入进来的,当前线程还继续持有这把锁的所有权,如果计数器变成0,则代表当前线程不再拥有该monitor的所有权,即释放锁。
下图表现了对象,对象监视器,同步队列以及执行线程状态之间的关系:
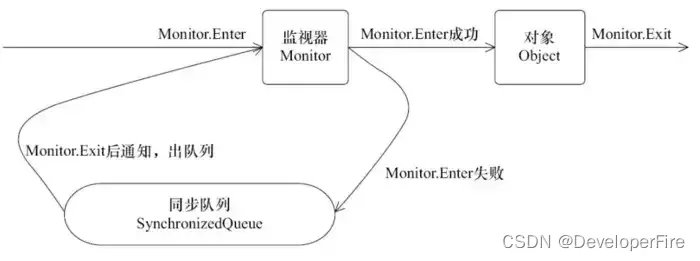
该图可以看出,任意线程对Object的访问,首先要获得Object的监视器,如果获取失败,该线程就进入同步状态,线程状态变为BLOCKED,当Object的监视器占有者释放后,在同步队列中得线程就会有机会重新获取该监视器。
可重入原理:加锁次数计数器
看如下的例子:
public class SynchronizedDemo {
public static void main(String[] args) {
synchronized (SynchronizedDemo.class) {
}
method2();
}
private synchronized static void method2() {
}
}对应的字节码
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: ldc #2 // class tech/pdai/test/synchronized/SynchronizedDemo
2: dup
3: astore_1
4: monitorenter
5: aload_1
6: monitorexit
7: goto 15
10: astore_2
11: aload_1
12: monitorexit
13: aload_2
15: invokestatic #3 // Method method2:()V
Exception table:
from to target type
5 7 10 any
10 13 10 any上面的SynchronizedDemo中在执行完同步代码块之后紧接着再会去执行一个静态同步方法,而这个方法锁的对象依然就这个类对象,那么这个正在执行的线程还需要获取该锁吗? 答案是不必的,从上图中就可以看出来,执行静态同步方法的时候就只有一条monitorexit指令,并没有monitorenter获取锁的指令。这就是锁的重入性,即在同一锁程中,线程不需要再次获取同一把锁。
Synchronized先天具有重入性。每个对象拥有一个计数器,当线程获取该对象锁后,计数器就会加一,释放锁后就会将计数器减一。
保证可见性的原理:内存模型和happens-before规则
Synchronized的happens-before规则,即监视器锁规则:对同一个监视器的解锁,happens-before于对该监视器的加锁。继续来看代码:
public class MonitorDemo {
private int a = 0;
public synchronized void writer() { // 1
a++; // 2
} // 3
public synchronized void reader() { // 4
int i = a; // 5
} // 6
}该代码的happens-before关系如图所示:
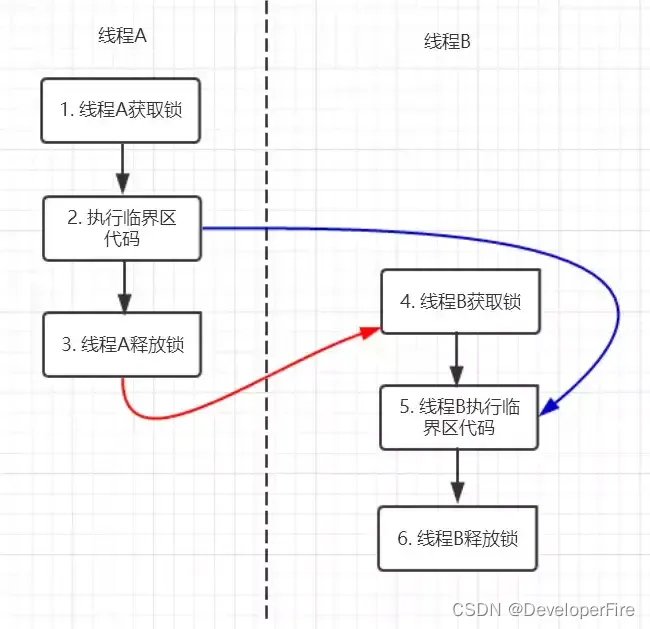
在图中每一个箭头连接的两个节点就代表之间的happens-before关系,黑色的是通过程序顺序规则推导出来,红色的为监视器锁规则推导而出:线程A释放锁happens-before线程B加锁,蓝色的则是通过程序顺序规则和监视器锁规则推测出来happens-befor关系,通过传递性规则进一步推导的happens-before关系。现在我们来重点关注2 happens-before 5,通过这个关系我们可以得出什么?
根据happens-before的定义中的一条:如果A happens-before B,则A的执行结果对B可见,并且A的执行顺序先于B。线程A先对共享变量A进行加一,由2 happens-before 5关系可知线程A的执行结果对线程B可见即线程B所读取到的a的值为1。
Synchronized使得同时只有一个线程可以执行,性能比较差,有什么提升的方法?
简单来说在JVM中monitorenter和monitorexit字节码依赖于底层的操作系统的Mutex Lock来实现的,但是由于使用Mutex Lock需要将当前线程挂起并从用户态切换到内核态来执行,这种切换的代价是非常昂贵的;然而在现实中的大部分情况下,同步方法是运行在单线程环境(无锁竞争环境)如果每次都调用Mutex Lock那么将严重的影响程序的性能。不过在jdk1.6中对锁的实现引入了大量的优化,如锁粗化(Lock Coarsening)、锁消除(Lock Elimination)、轻量级锁(Lightweight Locking)、偏向锁(Biased Locking)、适应性自旋(Adaptive Spinning)等技术来减少锁操作的开销。
锁粗化(Lock Coarsening):也就是减少不必要的紧连在一起的unlock,lock操作,将多个连续的锁扩展成一个范围更大的锁。
锁消除(Lock Elimination):通过运行时JIT编译器的逃逸分析来消除一些没有在当前同步块以外被其他线程共享的数据的锁保护,通过逃逸分析也可以在线程本地Stack上进行对象空间的分配(同时还可以减少Heap上的垃圾收集开销)。
轻量级锁(Lightweight Locking):这种锁实现的背后基于这样一种假设,即在真实的情况下我们程序中的大部分同步代码一般都处于无锁竞争状态(即单线程执行环境),在无锁竞争的情况下完全可以避免调用操作系统层面的重量级互斥锁,取而代之的是在monitorenter和monitorexit中只需要依靠一条CAS原子指令就可以完成锁的获取及释放。当存在锁竞争的情况下,执行CAS指令失败的线程将调用操作系统互斥锁进入到阻塞状态,当锁被释放的时候被唤醒。
偏向锁(Biased Locking):是为了在无锁竞争的情况下避免在锁获取过程中执行不必要的CAS原子指令,因为CAS原子指令虽然相对于重量级锁来说开销比较小但还是存在非常可观的本地延迟。
适应性自旋(Adaptive Spinning):当线程在获取轻量级锁的过程中执行CAS操作失败时,在进入与monitor相关联的操作系统重量级锁(mutex semaphore)前会进入忙等待(Spinning)然后再次尝试,当尝试一定的次数后如果仍然没有成功则调用与该monitor关联的semaphore(即互斥锁)进入到阻塞状态。
Synchronized由什么样的缺陷? Java Lock是怎么弥补这些缺陷的?
synchronized的缺陷
效率低:锁的释放情况少,只有代码执行完毕或者异常结束才会释放锁;试图获取锁的时候不能设定超时,不能中断一个正在使用锁的线程,相对而言,Lock可以中断和设置超时
不够灵活:加锁和释放的时机单一,每个锁仅有一个单一的条件(某个对象),相对而言,读写锁更加灵活
无法知道是否成功获得锁,相对而言,Lock可以拿到状态
Lock解决相应问题
Lock类这里不做过多解释,主要看里面的4个方法:
lock(): 加锁
unlock(): 解锁
tryLock(): 尝试获取锁,返回一个boolean值
tryLock(long,TimeUtil): 尝试获取锁,可以设置超时
Synchronized只有锁只与一个条件(是否获取锁)相关联,不灵活,后来Condition与Lock的结合解决了这个问题。
多线程竞争一个锁时,其余未得到锁的线程只能不停的尝试获得锁,而不能中断。高并发的情况下会导致性能下降。ReentrantLock的lockInterruptibly()方法可以优先考虑响应中断。 一个线程等待时间过长,它可以中断自己,然后ReentrantLock响应这个中断,不再让这个线程继续等待。有了这个机制,使用ReentrantLock时就不会像synchronized那样产生死锁了。
Synchronized和Lock的对比,和选择?
存在层次上
synchronized: Java的关键字,在jvm层面上
Lock: 是一个接口
锁的释放
synchronized: 1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程释放锁
Lock: 在finally中必须释放锁,不然容易造成线程死锁
锁的获取
synchronized: 假设A线程获得锁,B线程等待。如果A线程阻塞,B线程会一直等待
Lock: 分情况而定,Lock有多个锁获取的方式,大致就是可以尝试获得锁,线程可以不用一直等待(可以通过tryLock判断有没有锁)
锁的释放(死锁产生)
synchronized: 在发生异常时候会自动释放占有的锁,因此不会出现死锁
Lock: 发生异常时候,不会主动释放占有的锁,必须手动unlock来释放锁,可能引起死锁的发生
锁的状态
synchronized: 无法判断
Lock: 可以判断
锁的类型
synchronized: 可重入 不可中断 非公平
Lock: 可重入 可判断 可公平(两者皆可)
性能
synchronized: 少量同步
Lock: 大量同步
Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离) 在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
ReentrantLock提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。在资源竞争不激烈的情形下,性能稍微比synchronized差点点。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍。而ReentrantLock确还能维持常态。
调度
synchronized: 使用Object对象本身的wait 、notify、notifyAll调度机制
Lock: 可以使用Condition进行线程之间的调度
用法
synchronized: 在需要同步的对象中加入此控制,synchronized可以加在方法上,也可以加在特定代码块中,括号中表示需要锁的对象。
Lock: 一般使用ReentrantLock类做为锁。在加锁和解锁处需要通过lock()和unlock()显示指出。所以一般会在finally块中写unlock()以防死锁。
底层实现
synchronized: 底层使用指令码方式来控制锁的,映射成字节码指令就是增加来两个指令:monitorenter和monitorexit。当线程执行遇到monitorenter指令时会尝试获取内置锁,如果获取锁则锁计数器+1,如果没有获取锁则阻塞;当遇到monitorexit指令时锁计数器-1,如果计数器为0则释放锁。
Lock: 底层是CAS乐观锁,依赖AbstractQueuedSynchronizer类,把所有的请求线程构成一个CLH队列。而对该队列的操作均通过Lock-Free(CAS)操作。
Synchronized在使用时有何注意事项?
锁对象不能为空,因为锁的信息都保存在对象头里
作用域不宜过大,影响程序执行的速度,控制范围过大,编写代码也容易出错
避免死锁
在能选择的情况下,既不要用Lock也不要用synchronized关键字,用java.util.concurrent包中的各种各样的类,如果不用该包下的类,在满足业务的情况下,可以使用synchronized关键,因为代码量少,避免出错
Synchronized修饰的方法在抛出异常时,会释放锁吗?
会
多个线程等待同一个Synchronized锁的时候,JVM如何选择下一个获取锁的线程?
非公平锁,即抢占式。
synchronized是公平锁吗?
synchronized实际上是非公平的,新来的线程有可能立即获得监视器,而在等待区中等候已久的线程可能再次等待,这样有利于提高性能,但是也可能会导致饥饿现象。
volatile关键字的作用是什么?
防重排序 我们从一个最经典的例子来分析重排序问题。大家应该都很熟悉单例模式的实现,而在并发环境下的单例实现方式,我们通常可以采用双重检查加锁(DCL)的方式来实现。其源码如下:
public class Singleton {
public static volatile Singleton singleton;
/**
* 构造函数私有,禁止外部实例化
*/
private Singleton() {};
public static Singleton getInstance() {
if (singleton == null) {
synchronized (singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}现在我们分析一下为什么要在变量singleton之间加上volatile关键字。要理解这个问题,先要了解对象的构造过程,实例化一个对象其实可以分为三个步骤:
分配内存空间。
初始化对象。
将内存空间的地址赋值给对应的引用。
但是由于操作系统可以对指令进行重排序,所以上面的过程也可能会变成如下过程:
分配内存空间。
将内存空间的地址赋值给对应的引用。
初始化对象
如果是这个流程,多线程环境下就可能将一个未初始化的对象引用暴露出来,从而导致不可预料的结果。因此,为了防止这个过程的重排序,我们需要将变量设置为volatile类型的变量。
实现可见性
可见性问题主要指一个线程修改了共享变量值,而另一个线程却看不到。引起可见性问题的主要原因是每个线程拥有自己的一个高速缓存区——线程工作内存。volatile关键字能有效的解决这个问题,我们看下下面的例子,就可以知道其作用:
public class VolatileTest {
int a = 1;
int b = 2;
public void change(){
a = 3;
b = a;
}
public void print(){
System.out.println("b="+b+";a="+a);
}
public static void main(String[] args) {
while (true){
final VolatileTest test = new VolatileTest();
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
test.change();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
test.print();
}
}).start();
}
}
}直观上说,这段代码的结果只可能有两种:b=3;a=3 或 b=2;a=1。不过运行上面的代码(可能时间上要长一点),你会发现除了上两种结果之外,还出现了另外两种结果:
......
b=2;a=1
b=2;a=1
b=3;a=3
b=3;a=3
b=3;a=1// 这里
b=3;a=3
b=2;a=1
b=3;a=3
b=3;a=3
b=2;a=3// 这里......为什么会出现b=2;a=3和b=3;a=1这种结果呢? 正常情况下,如果先执行change方法,再执行print方法,输出结果应该为b=3;a=3。相反,如果先执行的print方法,再执行change方法,结果应该是 b=2;a=1。那b=3;a=1的结果是怎么出来的? 原因就是第一个线程将值a=3修改后,但是对第二个线程是不可见的,所以才出现这一结果。如果将a和b都改成volatile类型的变量再执行,则再也不会出现b=2;a=3和b=3;a=1的结果了。
保证原子性:单次读/写
volatile不能保证完全的原子性,只能保证单次的读/写操作具有原子性。
volatile能保证原子性吗?
不能完全保证,只能保证单次的读/写操作具有原子性。
32位机器上共享的long和double变量的为什么要用volatile?
因为long和double两种数据类型的操作可分为高32位和低32位两部分,因此普通的long或double类型读/写可能不是原子的。因此,鼓励大家将共享的long和double变量设置为volatile类型,这样能保证任何情况下对long和double的单次读/写操作都具有原子性。
如下是JLS中的解释:
17.7 Non-Atomic Treatment of double and long
For the purposes of the Java programming language memory model, a single write to a non-volatile long or double value is treated as two separate writes: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write.
Writes and reads of volatile long and double values are always atomic.
Writes to and reads of references are always atomic, regardless of whether they are implemented as 32-bit or 64-bit values.
Some implementations may find it convenient to divide a single write action on a 64-bit long or double value into two write actions on adjacent 32-bit values. For efficiency’s sake, this behavior is implementation-specific; an implementation of the Java Virtual Machine is free to perform writes to long and double values atomically or in two parts.
Implementations of the Java Virtual Machine are encouraged to avoid splitting 64-bit values where possible. Programmers are encouraged to declare shared 64-bit values as volatile or synchronize their programs correctly to avoid possible complications.
目前各种平台下的商用虚拟机都选择把 64 位数据的读写操作作为原子操作来对待,因此我们在编写代码时一般不把long 和 double 变量专门声明为 volatile多数情况下也是不会错的。
volatile是如何实现可见性的?
内存屏障。
volatile是如何实现有序性的?
happens-before等
说下volatile的应用场景?
使用 volatile 必须具备的条件
对变量的写操作不依赖于当前值。
该变量没有包含在具有其他变量的不变式中。
只有在状态真正独立于程序内其他内容时才能使用 volatile。
例子 1: 单例模式
单例模式的一种实现方式,但很多人会忽略 volatile 关键字,因为没有该关键字,程序也可以很好的运行,只不过代码的稳定性总不是 100%,说不定在未来的某个时刻,隐藏的 bug 就出来了。
class Singleton {
private volatile static Singleton instance;
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
syschronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}例子2: volatile bean
在 volatile bean 模式中,JavaBean 的所有数据成员都是 volatile 类型的,并且 getter 和 setter 方法必须非常普通 —— 除了获取或设置相应的属性外,不能包含任何逻辑。此外,对于对象引用的数据成员,引用的对象必须是有效不可变的。(这将禁止具有数组值的属性,因为当数组引用被声明为 volatile 时,只有引用而不是数组本身具有 volatile 语义)。对于任何 volatile 变量,不变式或约束都不能包含 JavaBean 属性。
@ThreadSafe
public class Person {
private volatile String firstName;
private volatile String lastName;
private volatile int age;
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
public int getAge() { return age; }
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public void setAge(int age) {
this.age = age;
}
}所有的final修饰的字段都是编译期常量吗?
不是
如何理解private所修饰的方法是隐式的final?
类中所有private方法都隐式地指定为final的,由于无法取用private方法,所以也就不能覆盖它。可以对private方法增添final关键字,但这样做并没有什么好处。看下下面的例子:
public class Base {
private void test() {
}
}
public class Son extends Base{
public void test() {
}
public static void main(String[] args) {
Son son = new Son();
Base father = son;
//father.test();
}
}Base和Son都有方法test(),但是这并不是一种覆盖,因为private所修饰的方法是隐式的final,也就是无法被继承,所以更不用说是覆盖了,在Son中的test()方法不过是属于Son的新成员罢了,Son进行向上转型得到father,但是father.test()是不可执行的,因为Base中的test方法是private的,无法被访问到。
说说final类型的类如何拓展?
比如String是final类型,我们想写个MyString复用所有String中方法,同时增加一个新的toMyString()的方法,应该如何做?
外观模式:
/**
* @pdai
*/
class MyString{
private String innerString;
// ...init & other methods
// 支持老的方法
public int length(){
return innerString.length(); // 通过innerString调用老的方法
}
// 添加新方法
public String toMyString(){
//...
}
}final方法可以被重载吗?
我们知道父类的final方法是不能够被子类重写的,那么final方法可以被重载吗? 答案是可以的,下面代码是正确的。
public class FinalExampleParent {
public final void test() {
}
public final void test(String str) {
}
}父类的final方法能不能够被子类重写?
不可以
说说基本类型的final域重排序规则?
先看一段示例性的代码:
public class FinalDemo {
private int a; //普通域
private final int b; //final域
private static FinalDemo finalDemo;
public FinalDemo() {
a = 1; // 1. 写普通域
b = 2; // 2. 写final域
}
public static void writer() {
finalDemo = new FinalDemo();
}
public static void reader() {
FinalDemo demo = finalDemo; // 3.读对象引用
int a = demo.a; //4.读普通域
int b = demo.b; //5.读final域
}
}假设线程A在执行writer()方法,线程B执行reader()方法。
写final域重排序规则
写final域的重排序规则禁止对final域的写重排序到构造函数之外,这个规则的实现主要包含了两个方面:
JMM禁止编译器把final域的写重排序到构造函数之外;
编译器会在final域写之后,构造函数return之前,插入一个storestore屏障。这个屏障可以禁止处理器把final域的写重排序到构造函数之外。
我们再来分析writer方法,虽然只有一行代码,但实际上做了两件事情:
构造了一个FinalDemo对象;
把这个对象赋值给成员变量finalDemo。
我们来画下存在的一种可能执行时序图,如下:
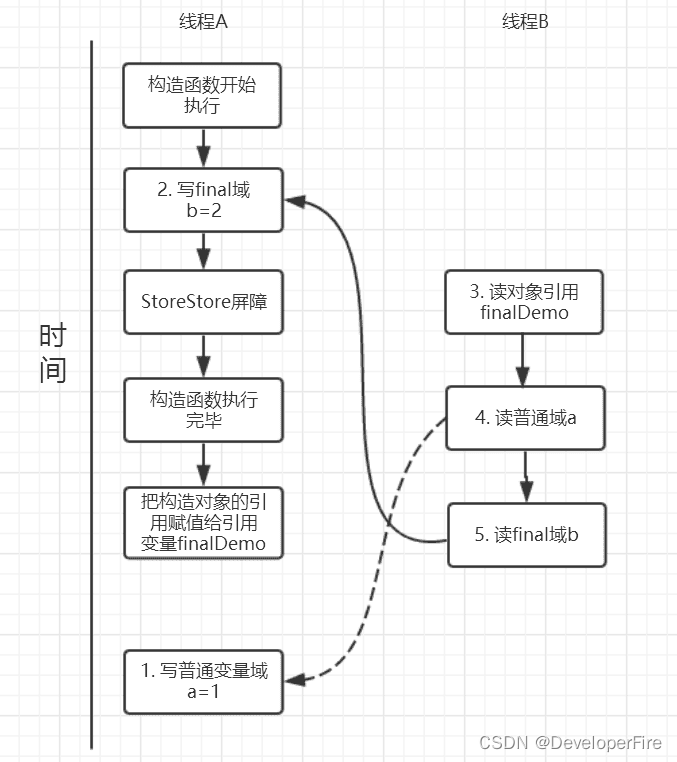
由于a,b之间没有数据依赖性,普通域(普通变量)a可能会被重排序到构造函数之外,线程B就有可能读到的是普通变量a初始化之前的值(零值),这样就可能出现错误。而final域变量b,根据重排序规则,会禁止final修饰的变量b重排序到构造函数之外,从而b能够正确赋值,线程B就能够读到final变量初始化后的值。
因此,写final域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域就不具有这个保障。比如在上例,线程B有可能就是一个未正确初始化的对象finalDemo。
读final域重排序规则
读final域重排序规则为:在一个线程中,初次读对象引用和初次读该对象包含的final域,JMM会禁止这两个操作的重排序。(注意,这个规则仅仅是针对处理器),处理器会在读final域操作的前面插入一个LoadLoad屏障。实际上,读对象的引用和读该对象的final域存在间接依赖性,一般处理器不会重排序这两个操作。但是有一些处理器会重排序,因此,这条禁止重排序规则就是针对这些处理器而设定的。
read()方法主要包含了三个操作:
初次读引用变量finalDemo;
初次读引用变量finalDemo的普通域a;
初次读引用变量finalDemo的final域b;
假设线程A写过程没有重排序,那么线程A和线程B有一种的可能执行时序为下图:
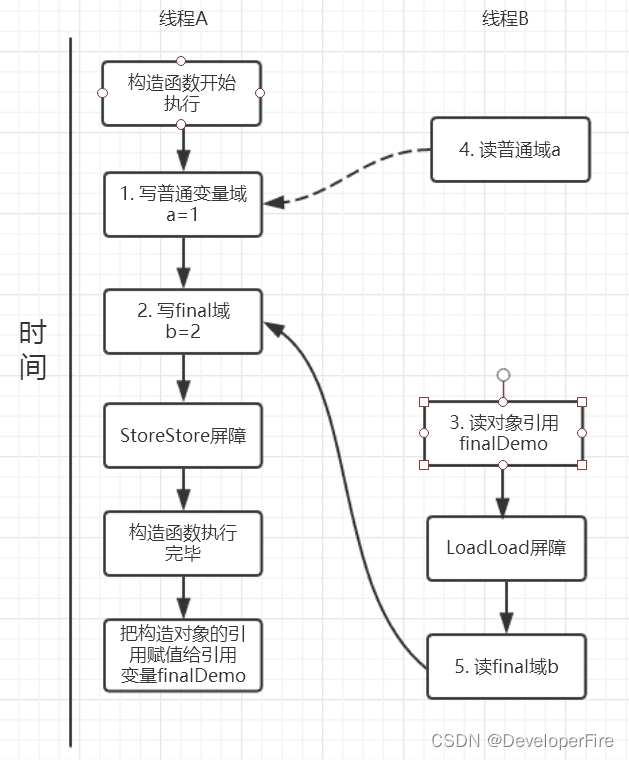
读对象的普通域被重排序到了读对象引用的前面就会出现线程B还未读到对象引用就在读取该对象的普通域变量,这显然是错误的操作。而final域的读操作就“限定”了在读final域变量前已经读到了该对象的引用,从而就可以避免这种情况。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读这个包含这个final域的对象的引用。
说说final的原理?
写final域会要求编译器在final域写之后,构造函数返回前插入一个StoreStore屏障。
读final域的重排序规则会要求编译器在读final域的操作前插入一个LoadLoad屏障。
PS:很有意思的是,如果以X86处理为例,X86不会对写-写重排序,所以StoreStore屏障可以省略。由于不会对有间接依赖性的操作重排序,所以在X86处理器中,读final域需要的LoadLoad屏障也会被省略掉。也就是说,以X86为例的话,对final域的读/写的内存屏障都会被省略!具体是否插入还是得看是什么处理器。


















 2233
2233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











