




导语丨随着大数据组件从Storm + Druid/CK + HIVE 逐步升级为Flink + StarRocks + iceberg,如何更好利用StarRocks的各种特性给用户带来极致的性能体验也变的尤为重要。本文将详解StarRocks底层实现原理来帮助大家理解StarRocks是如何进行数据读取与计算,从而进一步帮助大家可以更好地基于StarRocks进行业务SQL的编写与优化。
作者:Deltaverse高级研发工程师 even
1、背景
虽然说Starrocks 有向量化、RBO、CBO等引擎内核优化手段,但是由于统计信息收集存在随机性与局部性以及用户查询的复杂性,不能100%保证选择的执行计划就一定是最优的执行计划,所以我们需要进一步理解其底层存储与计算原理来进一步从SQL层减少资源使用的同时提高执行效率,实现降本增效。
2、执行原理
Starrocks执行的本质就是FE将SQL语句进行语法解析生成执行计划树,然后将执行计划发送给BE,BE读取对应的数据,执行相应的节点操作。如下图即为一个最基本的执行计划树,大部分执行计划都是由一个或者多个该执行计划组合而成,其中箭头方向即为数据流向。为了更好地理解Starrocks执行原理,接下来,我将从底至上依次讲解数据读取、分组聚合以及JOIN等实现,帮助大家可以更好地理解自己SQL是如何执行的同时知道应该如何进行优化。
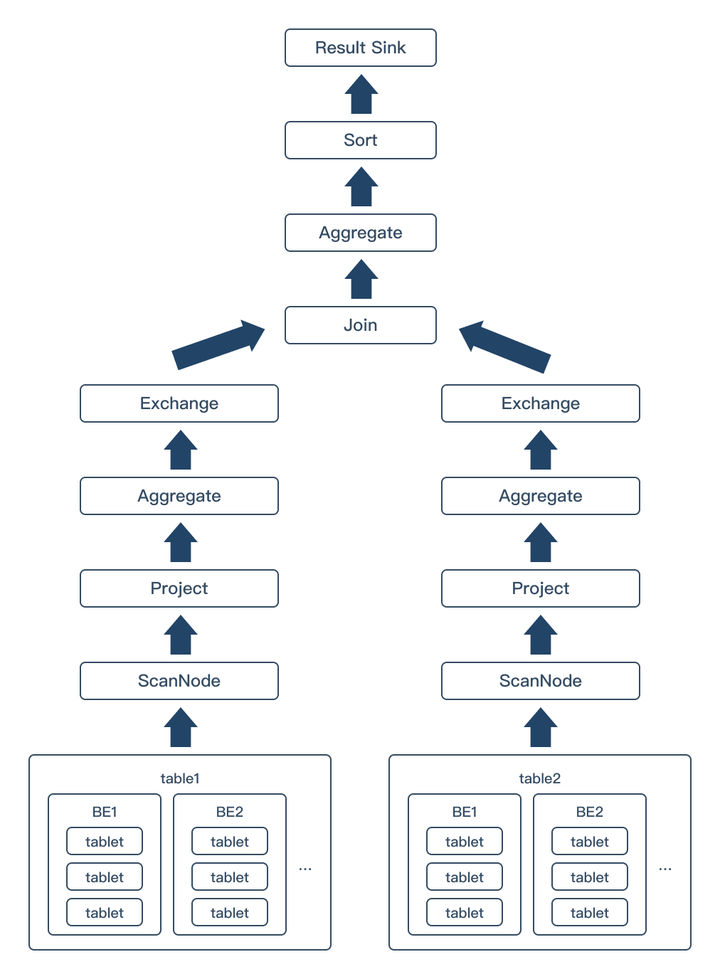
2.1 从数据存储理解如何在建表语句与Where条件中提高数据读取速度
对于数据的读取,在SQL中能做的就是尽可能让其使用索引并且尽可能少的扫描数据。通过理解Starrocks数据存储原理有助于用户更好地完成这个目标,让自己的SQL执行的更快。
2.1.1 数据分布
Starrocks 采用 Range+Hash 的数据分布方式。
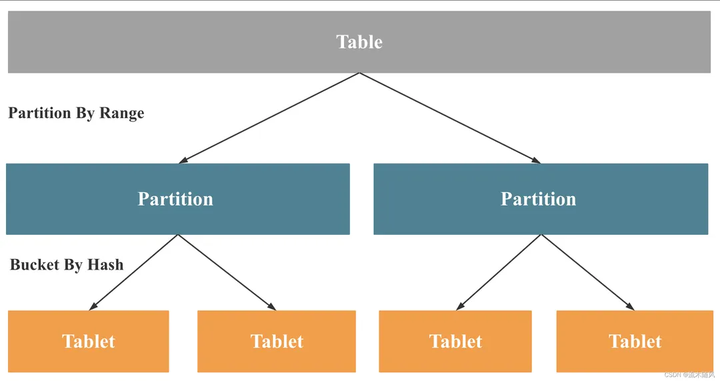
Range: 即分区,按区间范围进行数据分布。比如: 按天、月分区,则会将数据按对应范围进行划分管理。
分区管理的优点:
-
在查询中作为Starrocks第一级过滤,进行分区裁剪,减少数据扫描量,加速查询。所以建议使用where条件最常用的字段,且类型必须为日期或者整数类型。
-
对于每个分区提供了副本数、分桶数、冷热策略和存储介质等存储策略,可以灵活的根据不同分区的数据特点来选择最合适的存储策略,节省数据存储成本。
Hash: 即分桶,通过哈希函数把数据映射到不同节点上。
在同一分区内,分桶键哈希值相同的数据形成 Tablet,分桶数即为该分区的Hash取模的底数,即分区分桶数 = 分区Tablet数。Tablet是数据实际存储的物理单元,也是Starrocks计算实例处理数据的基本单位。比如: 集群有3个BE,查询并行度设置为8,则Starrocks会创建24个计算实例进行数据处理与计算,但是如果查询的数据只存在于10个Tablet中,则就会出现最多10个计算实例在处理这10个Tablet数据,而还有14个计算实例没有数据处理的情况,导致数据倾斜。而对于MPP架构的Starrocks来说,最终的执行时间是由执行最慢的计算实例决定的,所以这样数据倾斜就会拖慢整个计算。从这个逻辑看就可以知道分桶的目的就是将数据打散,使数据尽量均匀地分布在集群的各个BE节点上,以便在查询时充分发挥集群多机多核的优势。
那么如何通过分桶来将数据打散呢?
首先分桶需要设置两个值
1.分桶键: 即按照这个字段/字段组合的值进行Hash取模。
-
由于需要将数据尽可能打散,让每个tablet中的数据量尽可能相当,所以建议选择高基数(即该字段的去重数比较大)且不存在单值倾斜的字段。高基数是因为假设我们使用低基数的字段,该字段去重数比较少,比如只有10个值,而我们分桶数设置成100,这样就会导致只有10个Tablet有数据,并不会打散数据。而单值倾斜的字段的意思是,这列有个值数据量非常大,这样也是不适合的,因为这样容易导致有个tablet非常大,从而导致数据倾斜。NULL值现象比较容易出现这种情况,即一个字段有大量的NULL值,这时候需要考虑这个NULL值合不合理,如果不合理则在ETL阶段就对其进行过滤,如果合理则可能需要考虑换一个字段作为分桶键或者通过多个字段组合作为分桶键了。对于多字段组合分桶键时建议不超过3个字段。
-
由于分桶是Starrocks第二级过滤,所以建议选择经常作为查询条件的列为分桶键,这样可以通过分桶键减少数据扫描量,提高查询效率。
2.分桶数: 即为该分区的Hash取模的底数。
其决定了分区的Tablet数,从而决定着查询并行度。那是不是这个值越大越好呢?这肯定不是的,主要原因是虽然Starrocks的数据都存储在BE,但是FE作为Starrocks的大脑,在生成执行计划时它需要知道哪些数据在哪个BE上,这样才能进行计算任务的分发。也正是由于这个原因,所以FE需要在内存中存储每个Tablet信息,这样如果分桶数太大时就会导致FE内存消耗巨大,产生性能瓶颈,从而影响集群稳定性。那应该设置多少分桶数比较合适呢?建议压缩后每个Tablet大小为1G左右。
可以按照以下公式进行估算:
估算公式: 分桶数=分区数据实际大小/5G;
例:假设按天进行分区,每天10亿数据,每条数据1kB; 则 分桶数 = 1kB* 1 000 000 000 / 5G = 200
说明: 除以5是由于Starrocks默认使用Lz4压缩,压缩比约为5。
2.1.2 数据存储
前面说了Tablet是数据实际存储的物理单元,那Tablet具体又是如何存储的呢?
以下为数据在BE中的存储结构:
Slot: 一共1024个槽位,用于通过一致性Hash算法解决分布式存储时BE扩缩容数据迁移问题。
|— Tablet: 实际存储的物理单元
| |— RowSet: Rowset是Tablet中一次数据变更的数据集合,每次变更会生成一个版本号 version
| |— Segment.dat: Rowset中的数据分段,也是Starrocks最终的数据存储文件
StarRocks的OLAP表的数据就是通过这四个层级组织存储结构的。
2.1.3 Starrocks数据文件
接下来我们就看看Starrocks数据是如何存储的呢?以及在快速定位到需要的数据,减少数据扫描上做了哪些工作与设计。

如上图即为Segment.dat文件的文件结构。其主要为3个大区域:
1.DataRegion: 用户数据。从图中可以看出Starrocks数据文件是列式存储的。
使用列式存储主要有以下优点:
-
由于同一列数据类型相同,且对于排序的列,相同值也聚集在一起,这样会有比较好的压缩效果。
-
对于OLAP查询时,只需要扫描需要的列,不用全部列扫描,减少数据扫描量,提高查询效率。
而每列数据又被分成多个列级数据块,即图中的Data Page。
2.Index Region: 索引区域。
其中又有两个区域:
1.Column x Index: 列级索引;从图中可以看到有三种列级索引: Boolm Filter、BitMap、Ordinal Index。但并不是所有列都有这三种索引。首先对于排序键的列,会生成其Ordinal Index。而其他列以及索引只有在建表语句中指定了该列使用Boolm Filter或者BitMap索引才会生成。
比如 : 在建表语句的列语句中使用: INDEX index_name (column_name) USING BITMAP 这样才会对这列生成BitMap索引。而Boolm Filter索引是在建表语句的PROPERTIES中指定: PROPERTIES("bloom_filter_columns" = "k1,k2");
或者也可以使用 Create Index 语句进行添加。
2.Short Key Index: 也称为排序键索引/前缀索引。用于快速查找排序键对应的数据。
3.Footer: 文件页脚。其中也有三个信息:
-
FileFooterPB: 其中还存有 ZoneMap Index;其中存储该数据文件所有简单列(即数值/时间类型的列)的最大最小值。用于快速判断查询的数据是否在该数据文件中。
-
PB Checksum & PB Length : 用于验证数据文件是否损坏。
-
MAGIC CODE:Starrocks数据文件魔数,Starrocks数据文件类型标识。
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









