 ZNS SSD相关存储系统研究与分析
ZNS SSD相关存储系统研究与分析




0. 基础
0.1. LSM-tree:
写操作:
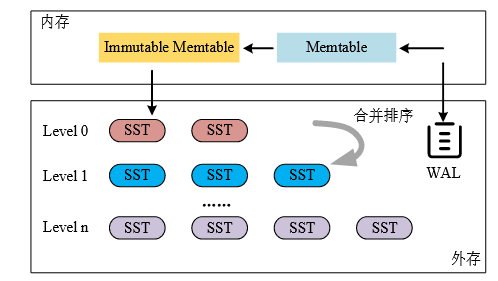
每当有数据插入或更新时,首先写WAL,然后数据被插入可变内存表。可变内存表满,则可变内存表变为不可变内存表,同时,WAL停止接收输入,创建一个新的WAL和可变内存表;
不可变内存表数量达到阈值后,每一个不可变内存表持久化为L0层的一个排序字符表文件(SSTable),SSTable中包含索引块和数据块,数据块内包含键值数据。
合并排序操作:
L0 层的 SST 文件是由不可变内存表写入到外存时产生的,而其他层的 SST 文 件则是由合并排序操作生成的。
当Li层中的容量达到阈值后,就会触发合并操作:
(1)选择Li层的一个SSTable作为Victim SST文件;
(2)识别出Li+1层中所有与Victim SST有键值重叠的SST作为Overlap SST;
(3)将Victim SST 和 Overlap SST都读入内存;
(4)合并和排序这些SST里面的有效键值对,同时删除里面的无效键值对
(5) 使原来的SST文件全部无效,生成新的SST文件并写入Li+1层。
读操作:
首先在可变内存表中查找;可变内存表无则查找不可变内存表;不可变内存表未找到,则在外存上的SST文件中查找.从最上层开始,逐层向下查找,直到找到所需数据或确认其不存在。其中 L0 层的SST文件之间键范围相互重叠,因此需要遍历 L0 层的所有 SST 文件。其它层的 SST 文件之间互相不重叠,每层只需要检查一个SST 文件。为了提高效率,每个SST文件都配备了布隆过滤器(Bloom Filter),布隆过滤器能够迅速判断一个数据是否可能存在于某个SST 文件中,从而有效减少不必要的外存读取操作。
0.2. ZNS SSD
0.3. 写放大
在 LSM-tree 中,为了保持数据的有序性并 更新数据版本,必须执行额外的数据复制和合并操作。在此过程中,原始数据量实际上会被“放大”。
合并操作和垃圾回收的过程都会产生写放大。
具体的体现为,写入10GB的数据,但实际写入量为13.4GB,大于了10GB。(可在db_bench中查看)
1. LeanKV
1.1. 总结
RocksDB+ZenFS。
认为RocksDB提供的写入提示比较模糊,ZenFS并不能很有效的来细分不同生命周期的SSTable文件,如果根据现有RocksDB的写入提示,ZenFS会简单地将同一层级的所有SSTable文件放置在一类分区中,将导致垃圾回收期间的额外数据迁移,因为待重置分区内可能存在很多有效的SS Table文件 。
提出了一种基于合并历史周期的生命预测方法,对具有相似生命周期的SSTable文件进行分组,将同一分组的SSTable存放到同一个分区。
LeanKV修改了RocksDB的刷新过程以及底层SSD写入原语。
1.2. 系统架构与数据布局
一个内存组件和一个外存组件构成。
内存组件上和RocksDB基本无异,尤其是合并操作的流程。但在执行合并操作时引入了一种创新型的策略,即根据不同的SSTable参与合并操作的频率分配不同的写入生命周期提示(WLTH).
外存组件上,根据之前设定好的写入生命周期提示,将SSTable文件分配到满足特定条件的存储分区中进行存储。
借鉴了RocksDB的架构,增加了SSTable文件的新特性Cscore。改进了RocksDB中计算SSTable文件写入生命周期的函数。借鉴了ZenFS的方法,对RocksDB内部的FileSystemWrapper类方法进行了调整,使得LeanKV可以通过libzbd与存储分区建立更直接的连接。
1.3. 生命周期
文中SST的生命周期定义:文件被产生的时刻t2到其被无效处理的时刻t1之间的差t2-t1
t1很好确定,关键是预测t2.可以通过SSTable文件所在的层数来预测t2。越低的层Ln+1容量越大,触发的合并操作越少,生命周期越长。
同层的SSTable生命周期也不同。引入新变量CScore衡量SSTable参与合并操作的频繁程度。SSTable到L0层时CScore初始化,参与合并操作后CScore增大。
注意到,SSTable越频繁参与合并操作,生命周期越短。
在RocksDB中,每一次合并操作都会在所谓的版本控制记录中记录下来,即在Version Set中创建一个新的版本记录。在这个新版本中一个非常关键的组成部分就是关于所有SSTable文件的元数据信息,这些信息被组织存储在一个以FileMetaData指针为基础的二维数组中。而FileMetaData数据结构本身包含了大量与SSTable文件密切相关的原始信息。例如,文件的唯一标识编号(File Number),文件的物理大小(File Size),包含的最大及最小键值(Smallest and Largest Keys),该文件参与合并操作的层级(Compaction Level)等。
LeanKV在此基础上引入了一个新变量CScore,与其他SSTable文件的元数据信息一样存放在每个SSTable文件的FileMetaData中。Cscore越大表明生命周期越短。首先为每个SStable文件的CScore赋予一个初始值,每当发生一次合并操作时,首先计算所有参与合并操作的SSTable文件的CScore值的平均值,然后在此基础上增加一定数值,最终将更新后的CScore值分配给由该合并操作产生的每一个新SSTable文件。

然后,基于CScore的不同,对SSTable文件进行适当的分组。
1.4. 分组算法
核心目标是为每个SSTable文件分配一个明确的集群标识符,以便于将具有相近生命周期特性的SSTable文件归纳到同一存储分区中,从而实现数据管理的优化和存储效率的提高。具体来说,一次合并操作完成后,此算法会被用于每一个新生成的SSTable文件,用于确定其对应的集群归属。随后,算法确保同一集群标识符下的SSTable文件被统一写入到同一个预定义的存储分区当中。

认为Level0和Level1的SSTable文件具有相似的生命周期特征,把Level0和Level1层归于一个集群。
对于Level2和Level3的SSTable文件,利用CScore进行分组,将其分为两个不同的集群。
对于更高层的SSTable文件,细分为3个集群,引入一个参数beta作为区分不同群的依据
1.5. 实验设置
db_bench:所有键值对的键大小设置为16字节,每个键对应的值的大小为1000字节。设置SSTable文件的大小为64MB,限制了LSM-tree的第0层和第一层的存储容量为不超过256MB。
1.5.1 写性能
db_bench提供的fillseq和fillrandom工作负载。
首先顺序写入10GB数据,这一步骤主要是为了对ZNS SSD进行预热,确保在接下来的性能测试中,存储设备能够在一个优化和统一的状态下运行。
接着采用fillrandom工作负载,随机向已有数据库中写入不同大小的数据集,包括60GB,70GB,80GB,90GB和100GB.
选择这样的数据集大小范围,是基于ZNS SSD内置的垃圾回收机制特点。ZNS SSD会在存储空间的空闲率降至某一特定阈值以下时(默认为20%)时,启动垃圾回收过程,并且系统会定期检查。
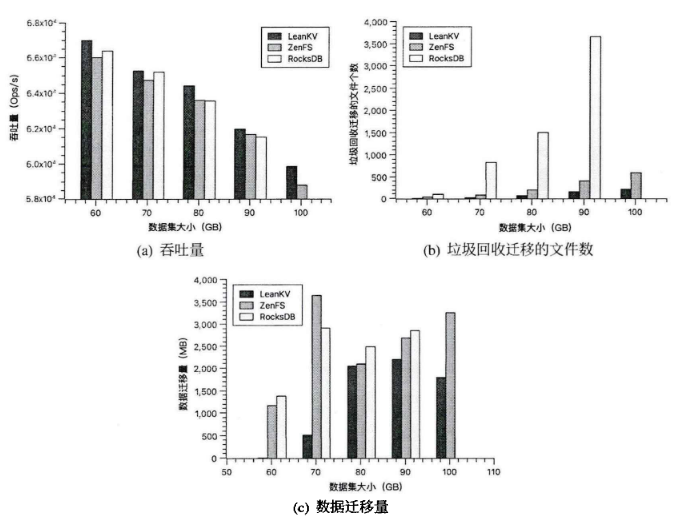
由于RocksDB在其数据放置策略中并未考虑SSTable的生命周期,因此在处理大规模数据写入任务时(如80GB,90GB,100GB),RocksDB常因put error而不得不提前结束
1.5.2. 更新性能
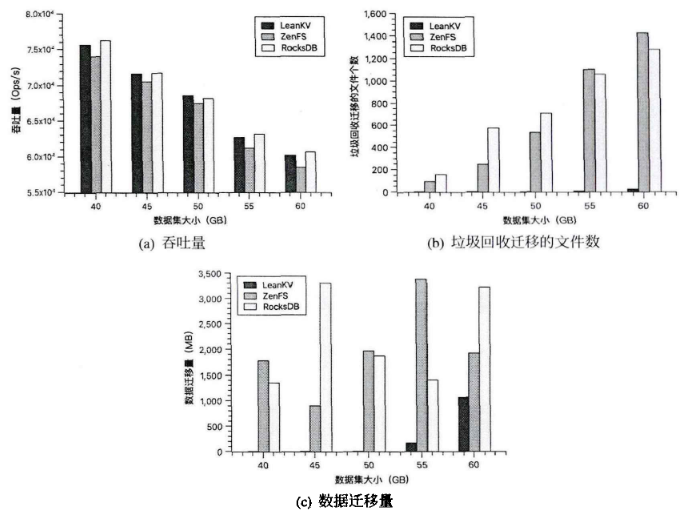
db_bench的overwrite工作负载。在更新XGB数据之前,先顺序写入XGB数据到ZNS SSD中,以此预热。
1.5.3. 读性能
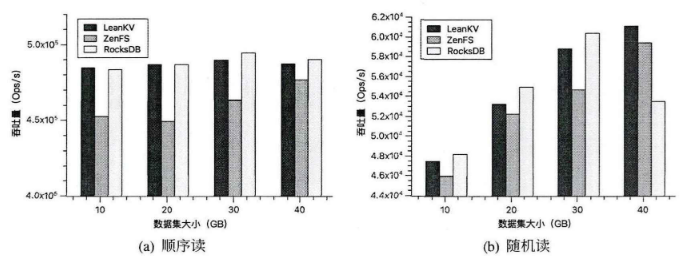
db_bench的readseq和readrandom,分别运行readseq和readrandom10GB、20GB、30GB和40GB的数据量。 对于每种工作负载,首先顺序写入40GB数据,然后随机写入40GB数据到ZNS SSD,最后,使用overwrite来更新40GB数据,再顺序读XGB数据,再随机读XGB数据。预先分别填充40GB的顺序数据和随机数据并给并更新40GB数据到ZNS SSD的目的是为了对LeanKV的读取性能进行全面、准确和可靠的评估。
1.5.4. 读写混合性能
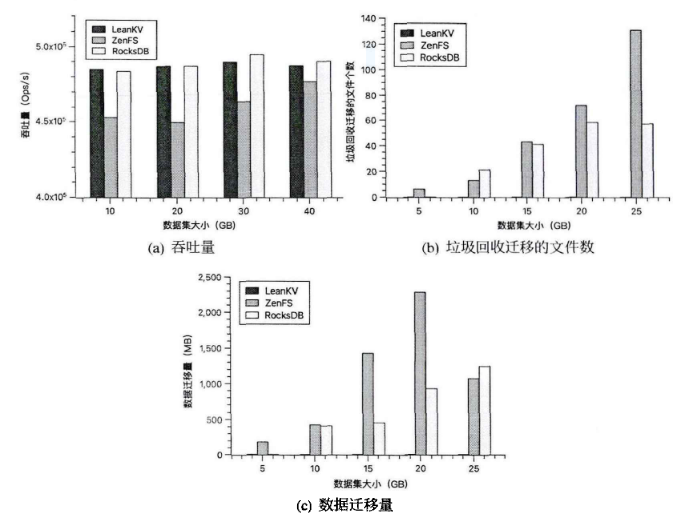
db_bench:readrandomwriterandom,读写比例设置为1比1
1.5.5. 多线程写性能
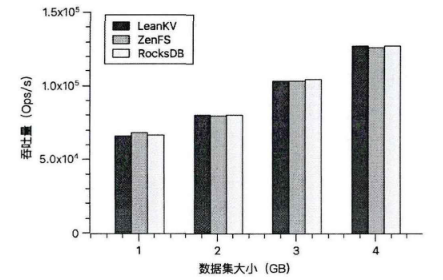
安排了不同线程数设置下的性能测试,具体包括了2,4,6,8,16线层级,运行fillrandom工作负载。预热ZNS SSD——在ZNS SSD上顺序写入50GB的数据,预热后,进一步将70GB的数据均匀地分配给不同的线程。
2. LeanKV+
2.1. 总结
在LeanKV的基础上,进一步优化了SSTable文件的分组和管理方法,以应对ZNS SSD的特定挑战。提出了一种基于K-means算法的SSTable文件聚类策略以优化SSTable文件分组的效果。
2.2. 基于K-means的聚类算法
在LeanKV系统处理大规模数据时,它在每个层级的每次合并过程中都会重新计算SSTable文件集群的分界点。
实际测试中发现,在实验测试的大部分负载下,在L2层进行合并操作的次数约为300次。基于这一数据,在LeanKV+中采取每合并15次更新一次分界点。

在每一次合并操作后,系统首先判断该操作所在的层数,如果层数大于等于第二层,并且在该层的合并次数达到了15次(或者15的倍数),则会触发重新计算边界点的操作,如果不满足这个条件,则仅将合并次数(通过变量CompTimes[Level]记录)加一。为了实现这一过程,引入数据结构Alldata,专门用于存储进行合并操作的层中所有SSTable文件的CScore值。
存储完成后,系统将对Alldata中的数据进行排序,并去除其中前后各5%的极端数据值。随后,findOptimalK函数通过遍历不同的k值,并计算相应的聚类成本(即误差平方和),以此找出能够使成本降低幅度最小的k值,作为最优的聚类数量。该函数首先假设聚类中心为数据集中的前k个点,然后通过不断迭代更新聚类标签和中心点,直至聚类中心点稳定。通过比较相邻k值的成本差异,该函数能够识别出在增加聚类数量时聚类成本下降幅度不再明显的点,据此确定该点作为最优的聚类数目,返回一系列k值中的三位数或者三分位数作为SSTable文件聚类的分界点。
设计并定义了一个新变量:OptK_Bound,专门记录经过K-means算法计算得到的各层最佳聚类分界值。具体来说,OptK_Bound是一个向量数组,其中的每一个元素(OptK_Bound[i])都对应着LSM-tree中特定层的聚类分界值。

3. ZNSKV
3.1. 总结
ZNSKV根据LSM-tree合并排序触发规律和文件选取策略来预测文件参与合并操作的概率,提供准确的文件数据寿命预测值。其次,ZNSKV将每个zone中首个文件的寿命预测值设置为该zone的寿命值,在处理文件数据写入请求时,选取寿命值和文件预测寿命值最接近的zone存储数据,以减少垃圾回收的数据迁移量。
同时涉及了一种新型合并排序方式Compactino-GC,选取所在zone无效数据占比较多、合并排序写放大较小的文件参与合并排序操作,从而在合并排序的同时完成部分数据迁移操作,减少后续垃圾回收操作需要迁移的数据量。最后,Compaction-GC会根据存储设备空闲容量占比情况自适应调整合并排序文件选取策略,在存储设备空闲容量较多时尽可能降低合并排序操作带来的写放大,在容量较少时尽可能提高垃圾回收效率。
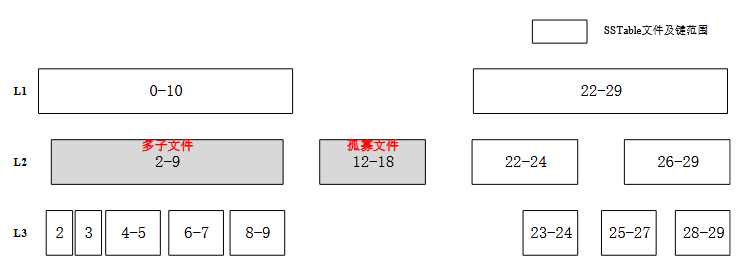
3.2. 系统总体架构
ZNSKV总体结构分为4个层次
(1)键值存储引擎:基于RocksDB进行改进,添加文件寿命预测模块、Compaction-GC模块和迁移数据识别模块。
(2)用户态文件系统层:基于ZenFS进行改进,添加数据布局模块和数据迁移模块,根据键值存储引擎中的数据寿命预测信息,在可写入的zone中选取zone寿命与文件寿命最接近的完成写入在不影响用户数据读写的情况下,将键值存储引擎中标记为需要迁移的文件写入到长寿命的zone内。
(3)Linux内核层。libzbd函数库调用用户空间API
(4)硬件层,真实的ZNS SSD设备。
3.3. 细粒度文件寿命预测方法
3.3.1. 文件类型分组
基于RocksDB进行改进设计,元数据主要有MANIFEST和CURRENT文件,其中MANIFEST保存当前数据库的状态信息,主要是SST文件的各个版本信息,而CURRENT文件记录了当前最新的MANIFEST文件编号。每当键值存储系统中有SSTable文件改动,都会生成相应的版本信息,并触发同步写MANIFEST文件的操作,用于异常断电后的数据回复。此类元数据需要频繁变动,因此元数据文件生命周期极短。
WAL以无序状态保存了内存组件中尚未持久化的键值对,当内存中的键值对完成持久化操作之后对应的WAL文件就会被删除,因此WAL文件的寿命很短。
SSTable文件的寿命则区别很大,需要额外加以区分。
3.3.2. SSTable文件寿命预测
现有的方案通常根据文件所在层级信息来预测文件寿命,但实际上同一层文件之间的寿命方差很大,所以还需要进一步对同一层的文件寿命加以区分。
LSM-tree中除了L0层外的每一层都存在一个设定的容量阈值,并且一个级别的容量阈值一般为上一级别的m倍。Ln层的实际容量与所设定的容量阈值的比值为当前层级的合并分数,记为Score。触发合并排序操作时,只会挑选Score大于1的层级中的文件,当有多个层级Score值大于1时,会挑选Score值最大的层级中的文件进行合并排序。
根据层级合并分数选定层级后,需要在该层级中选取合并排序文件。选取合并排序文件时会根据文件合并排序产生的写放大来决定选取的优先级。有些文件与下一层较多文件存在键范围重叠,这类文件参与合并排序时产生的数据读写量较多,合并排序优先级较低。文件优先级记为Pri,Pri值越大的文件代表被选取参与合并排序操作的概率越大,其寿命可能越短。
综合上面因素,对文件寿命建立一个预测模型,其中f(m^n)表示文件寿命与层级放大系数m以及所在层级n的关系,g(Pri)表示文件寿命与文件参与合并排序优先级的关系,h(Score)表示文件寿命与所在层级Score值的关系。
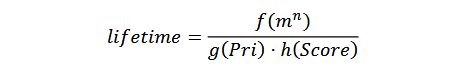
3.4. 高效数据布局方法
文件系统的数据布局模块接收到键值存储引擎下发的文件写入请求后,尽可能的将文件连续存储在同一个zone内,避免文件失效时无效数据过于分散导致垃圾回收开销增大。
3.4.1. 数据管理与映射关系
ZNSKV统一管理着设备逻辑地址空间,按4KB大小进行分块,划分出的逻辑地址单元称为LBA。处理文件写入请求时,文件系统会先分配好LBA,然后维护文件偏移地址到LBA的索引关系。文件系统以ZoneFile为粒度管理键值存储系统中的文件,一个ZoneFile对应一个SSTable文件或者WAL文件。当zone的剩余空间足够完全存储接收到的文件时,ZoneFile顺序使用zone内LBA资源。为了 减少索引开销,可以通过用一个 LBA 的起始地址加上偏移量来索引一个文件。
但是 zone 剩余可用空间可能不足以完全存储一个文件,此时就需要将 ZoneFile 进行切割处理。ZoneFile 会被切分成 extent 进行管理,extent 表示连续的 LBA 集合,一个 extent 只能存在于一个 zone 内。一般情况下 ZoneFile 远小于 zone 的大 小,因此一个文件大部分情况下只会分配一个 extent。ZNSKV 中文件可能存储在一 个或多个zone 内,需要在文件和LBA之间建立一个映射关系,以便更好管理数据。文件在 zone 上的存储以 extent 形式存在,一个 zone 内可能存储有多个 extent,但是 每个extent只会存在于一个zone内。因此在文件和extent之间建立一层映射表, extent 与 LBA 之间再建立一层映射管理,通过这两层映射建立文件与 LBA 之间的映射关系。
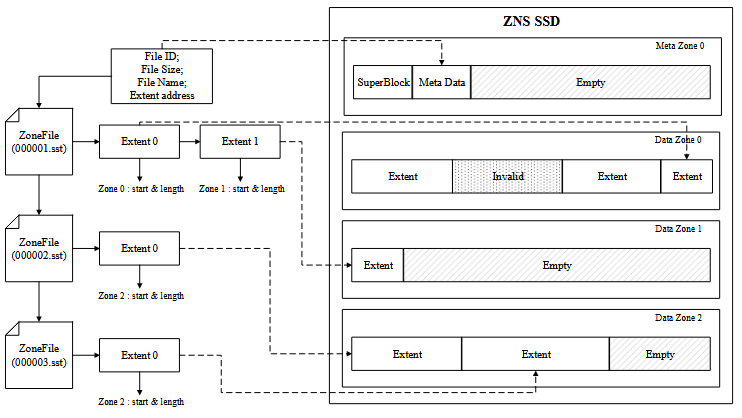
数据布局模块还用于向键值存储引擎传递ZNS SSD的zone容量信息。需要文件系统提供 zone 信息传输接口来打破键值存储引擎与文件系统之间的 信息隔离,以帮助键值存储引擎进行合并排序操作的同时完成部分垃圾回收操作。 zone 信息传输接口需要维护一个包含所有 zone 的容器,容器中的每个元素对应着一个 zone,而每个 zone 又对应一个 extent 容器,每个 extent 都与 SSTable 文件存在映 射关系。通过这几层映射可以在合并排序操作进行文件选取时提供每个 SSTable 所 在 zone 的无效数据占比信息。由于在两次文件选取优先级更新操作之间可能存在文 件的生成和删除操作,因此每次更新文件选取优先级时都需要调用一次 zone 信息传 输接口,获取 zone 信息的开销与 zone 的数量成正比,调用一次 zone 信息传输接口 的复杂度为 O(n),n 为 zone 的数量。
3.4.2. zone分配策略
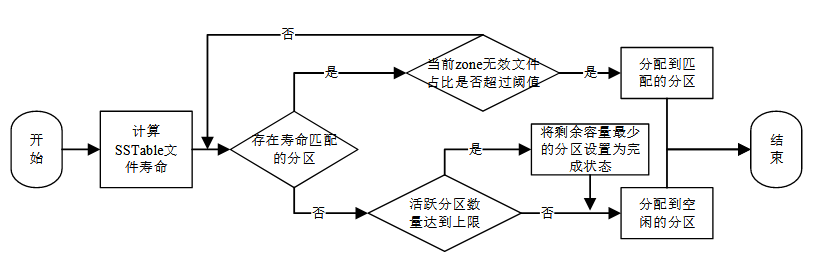
同一个文件的数据会尽可能的写入到同一个 zone 内。键值存储引擎为每个发 送到文件系统的文件都添加了文件寿命信息来供文件系统使用。另外文件系统会为 每个 zone 设置寿命值,zone 的寿命设置为与第一个写入到 zone 的文件寿命一致。
在一个新文件写入请求到来时,需要分配一个用于存储该文件的 zone。文件系统首先根据文件的寿命信息和 zone 的寿命信息来计算文件与 zone 的寿命差值lifetime_diff,分配lifetime_diff绝对值最小的 zone 用于接受数据写入。
如果存在多个 zone 的寿命值与文件寿命值差值为best_diff,则选取起始地址最小的 zone。
如果best_diff超过设定的阈值,代表现有可选的 active zone 寿命与文件寿命差值较大,都不适合用来存储待写入的文件。如果此时 active zone 数量没有达到上限,则直接分配一个空闲 zone 进行写入;如果 active zone 数量达到了上限,则需要 在现有 active zone 中寻找未在读写的 zone 将其转换为完成状态,当有多个未在读写 的 active zone 时,则选取其中剩余可用容量最少的 zone 转换为完成状态,此后便可 以打开一个空闲 zone 进行分配。如果在文件写入过程中,分配好的 zone 剩余可用容 量不足时,则使用相同的算法分配另一个 zone 接收此文件未写完的数据。
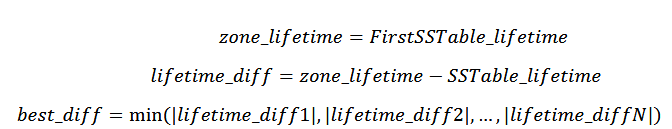
由于 ZNS SSD 并不总是能够提供合适的 zone 供数据进行写入,未能够写入 ZNS SSD 的数据保存在 ZNSKV 的数据缓冲区中。数据缓冲区的功能包括数据对齐和数 据暂存。ZNS SSD 的写入要求写入数据块的长度是按照 LBA 的粒度对齐的,这样才 能够减少空间浪费。数据缓冲区按照规定的格式存放排序好的键值对,构造成一个数 据块写入到 SSTable,然后下发到文件系统等待分配 zone。由于在文件布局过程中切 换 zone 的状态以及等待可用的 zone 资源会给文件的写入带来额外的延迟,而键值存 储引擎中 WAL 文件的写入性能与用户的写入性能直接相关,因此在对文件进行布局 时会识别文件类型,额外为 WAL 保留一个 open zone 资源。这样做可以避免 ZNSKV 键值存储系统的后台合并排序操作产生大量文件写入请求时,ZNS SSD 所有可用的 zone 资源都处于占用状态,WAL 文件无法及时写入造成长尾延迟。
3.5. 去冗余的合并排序方法
3.5.1. Compaction-GC方法
将垃圾回收操作融入到合并排序操作中,对需要迁移的文件进行合并排序操作,就能减少有效 数据迁移带来的写放大。
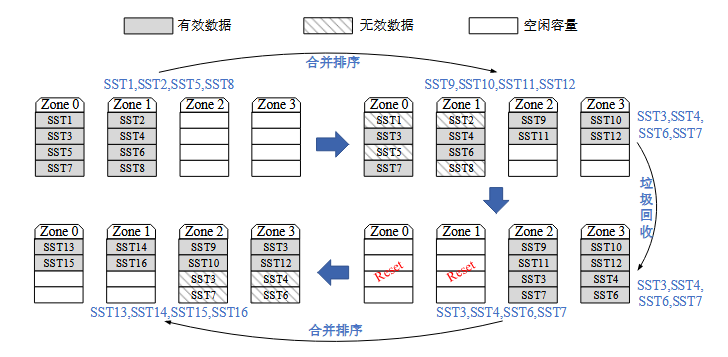
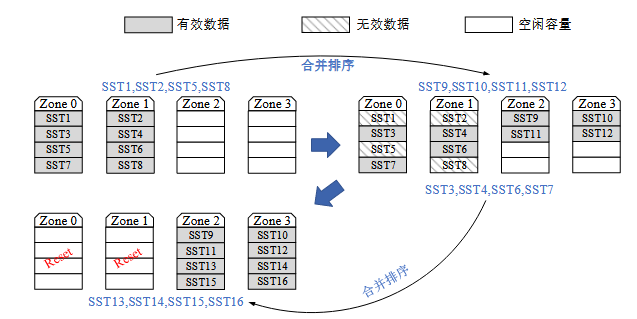
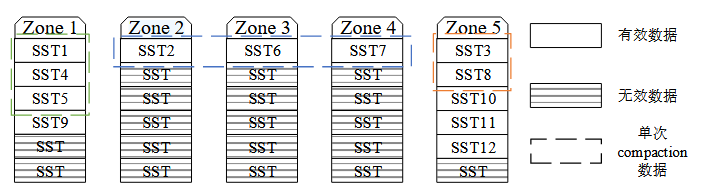
如图 11所示,在第一次合并排序操作之后,Zone 0 和 Zone 1 内的无效数据较多,Compaction-GC 此时避免采用数据迁移的方法进行垃圾回收,而是对 Zone 0 和 Zone 1 内的有效数据进行合并排序操作,生成新的 SSTable 文件写入到空闲地址上, 之后 Zone 0 和 Zone 1 内只存有无效数据,可以执行重置操作回收存储空间。 Compaction-GC 不仅完成了对数据的合并排序,还清理了无效数据完成了垃圾回收, 在此过程中一共只进行了 8 个文件的读写操作,相比原先合并排序与垃圾回收互相独立的设计,Compaction-GC 可以大大减少系统写放大。
然而图11 中展现的是一种特殊情况,即清理 Zone 0 和 Zone 1 中的无效数据时,其 中的有效数据 SST3、SST4、SST6 和 SST7 可以一起参与合并排序操作。然而 Compaction-GC 选取的 SSTable 可能分散在多个不同的 zone 内,产生更多待清理的 无效数据。Compaction-GC 选取 SSTable 进行合并排序时还有可能带来很高的合并排序写放大。为了保证 Compaction-GC 合并排序操作写放大较低的同时又能促进无效 数据的清理,需要设计合并排序文件选取算法。
3.5.2. 合并排序文件选取办法
文件选取时可以按照合并排序写放大来决定文件选取的优先级,此优先级记为 CompactionPri,CompactionPri 值越大代表文件被选取参与合并排序操作的概率越高。合并排序涉及的文件总数据量更大的 SSTable 文件进行合并排序操作带来的写放大更高,其 CompactionPri 值应该更小。因此 CompactionPri 值与参与合并排序的所有文件容量总大小负相关。
![]()
其中 filesize 代表合并排序中每个 SSTable 文件的大小。
文件选取时可以按照垃圾回收写放大来决定文件选取的优先级,此优先级记为 GCPri,GCPri 值越大代表文件被选取参与合并排序操作的优先级越高。合并排序所 涉及的文件所在 zone 无效数据占比越多越有可能降低垃圾回收写放大,其 GCPri 值越大。因此 GCPri 值与参与合并排序的 SSTable 所在 zone 的无效数据占比正相关。
![]()
其中 filesize 代表合并排序中每个SSTable 文件的大小,GP(garbage proportion)表示文件所在 zone 的无效数据占比。
综合二者对文件选取优先级的影响,可得如下公式
![]()
3.5.3. 自适应文件选取
设备在不同的空闲空间状态下垃圾回收操作对系统的影响有所不同,这就意味着垃圾回收对文件选 取优先级的影响大小也不同。 因此,垃圾回收操作对文件选取优先级的影响大小需要根据设备当前空闲容量占比进行自适应调整。
采取自适应的合并排序文件选取的策略,根据 ZNS SSD 空闲容量比例动态调整垃圾回收对文件选 取优先级影响的权重。这样可以在设备空闲容量较多时尽可能降低系统写放大,而在 设备空闲容量较少时提升无效数据清理效率尽可能提供足够的空闲存储空间。
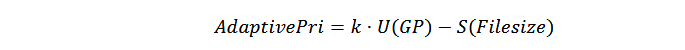
自适应文件选取优先级称为 AdaptivePri,文件参与合并排序的优先级与 其所在 zone 无效数据占比相关,其中 U(GP)表示与 zone 无效数据占比相关的函数, 文件所在 zone 无效数据占比越大其被选取的优先级越高。S(Filesize)表示文件参与合 并排序操作后带来的写放大,带来的写放大越大文件被选取的优先级越低。垃圾回收优化权重通过 k 值来调控,k 值越大无效数据清理速率就越快。
3.6. 选择性数据迁移方法
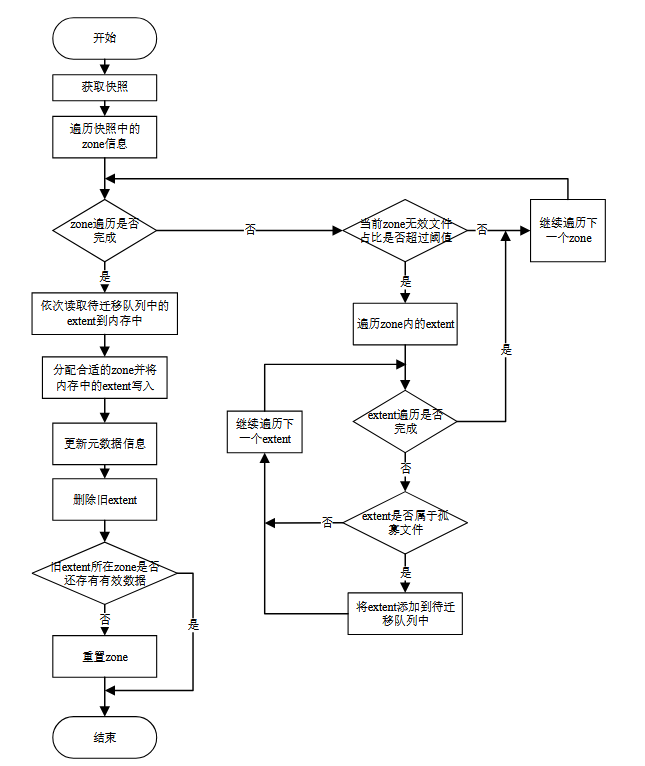
选择性数据迁移的功能是在 zone 中无效数据超过设定阈值时,迁移其中很可能 不会参与合并排序操作的数据,数据迁移完成后若 zone 内不再存有任何有效数据则 可以重置 zone 得到空闲存储空间。
键值存储系统 中存在一部分与其他 SSTable 文件不存在键范围重叠的 SSTable 文件,称之为“孤寡 文件”。
“孤寡 文件”的存在使得 Compaction-GC 操作无法完全取代垃圾回收功能,因为“孤寡文件”参与合并排序操作时只需简单的修改键值存储系统中相关的元数据信息,ZNS SSD 上的数据不需要做任何修改即可完成一次合并排序操作,此类文件的数据不会进行移动。
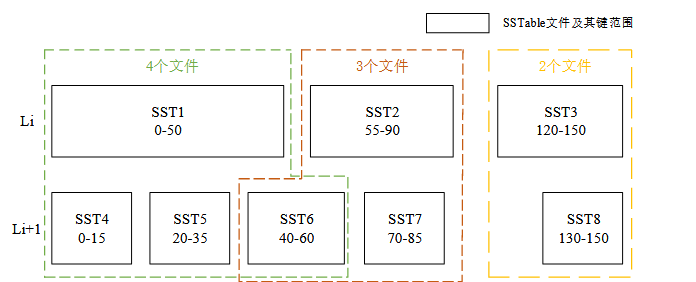
如图14左侧灰色 SSTable 为“多子文件”,在 L3 层中存在 5 个文件与 L2 层中的“多子文件”存 在键范围重叠,重叠文件数量明显多于 L2 层中的其他文件,文件参与合并排序操作 带来的写放大比同层其他文件大很多,此类文件主动被选取参与合并排序操作的可 能性相对较小。对于系统中存在的“孤寡文件”和“多子文件”,需要在其所在的 zone无效数据占比较多时对其进行迁移操作。
SSTable 在文件系统中以 extent 的形式进行存储,在迁移的时候以 extent 为单位 进行操作,数据迁移需要进行四个子任务:目标 extent 选取、空闲分区分配、有效数 据复制和元数据更新。具体的设计是,对于每个 zone 都维护无效数据、有效数据以 及空闲容量的信息。在迁移模块生效时通过维护的信息计算所有 zone 的无效数据占比值 r。
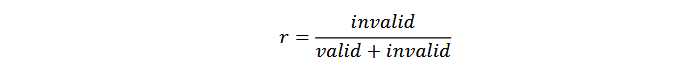
若 zone 的空闲容量为 0 且 r 值大于设定阈值,该 zone 会被加入候选队列。候选队列内的每个 extent 都对应一个 SSTable 或者 WAL, 由于 WAL 文件寿命都很短,不需要进行迁移,在此只考虑属于 SSTable 的 extent。 在数据迁移模块中额外判断文件是否属于“孤寡文件”或“多子文件”开销较大。为 了减少文件识别开销,本方案在合并排序文件选取模块计算文件合并排序优先级时 会对与其他文件不存在键范围重叠的“孤寡文件”进行标记,另外优先级计算所得的 SSTable 合并排序写放大数据会和文件系统中的 ZoneFile 元数据一起维护,这样可以 避免额外的计算开销。后续在进行 extent 识别时,只需查找其对应的 ZoneFile 是否 被标记为为“孤寡文件”。另外查询 extent 所对应的 ZoneFile 合并排序写放大是否大 于设定的写放大阈值,当合并排序写放大大于设定阈值时,该 extent 会被认定为“多 子文件”的数据等待迁移。选取好待迁移的 extent 之后,文件系统会为每个 extent 分 配空闲容量足够且寿命合适的 zone。在 zone 分配完成后会将需要迁移的 extent 先复 制到内存中,等待文件系统调度将内存中存储的 extent 写入到之前分配的 zone 中, 避免数据迁移影响前台用户写入性能。extent 写入完成后会修改 extent 与 zone 的映 射关系,以及 extent 在 zone 中的起始地址。
3.7. 具体实现
3.7.1 文件寿命预测
初始分组:

键值存储系统元数据和 WAL 寿命分别设置为 1 和 2。本方案所设置的 LSM-tree 层数n最高为 7 层, 因此将寿命分成 7 组。
层级 Score 计算:
L0 层的 Score 计算方式与其他层的 Score 计算方式不同.
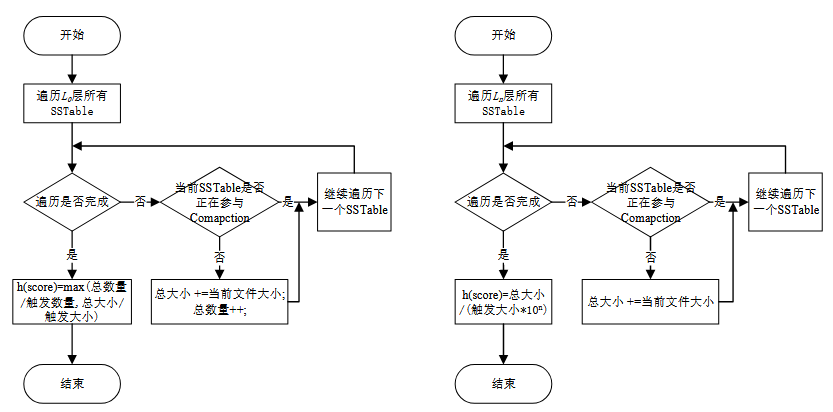
L0层计算当前容量/触发容量,当前数量/触发数量两者的最大值,其他层只计算容量。
文件合并排序优先级计算:
ZNSKV 中 SSTable 文件的元数据由 FileMetaData 结构体维护。 其中包含文件大小信息,SSTable 中的最小和最大 key 以及 SSTable 是否正在参与合 并操作的标识符。
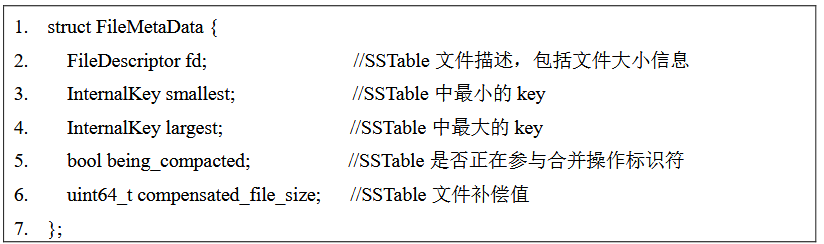
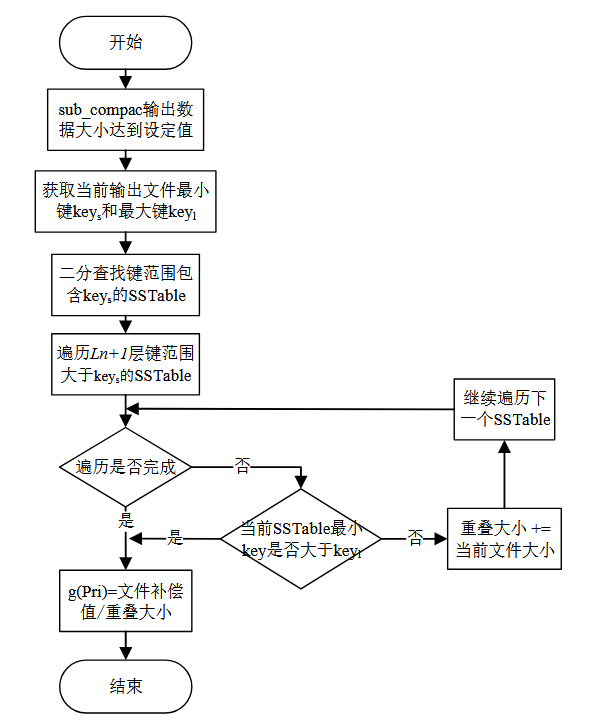
考虑到 LSM-tree 中 delete 条目比较多的时候空间放大 会更为严重,因此 delete 条目比较多的 SSTable 应该具有更高的合并排序优先级,这 样就能更好的清理 LSM-tree 中的旧数据。为此需要对新写入到 Ln 层的 SSTable 文件 大小进行补偿,SSTable 文件中删除条目超过文件总数据条目的一半时,文件补偿值 大小会大于文件实际数据量大小。
文件 Pri 值越大的文件合并排序优先级越高,因此 Pri 与文件补偿值成正比,与 Ln+1 层重叠文件总数据量成反比。
最后综合初始寿命值、 所在层级 Score 值和文件合并排序优先级来计算 SSTable 文件的寿命预测值。
3.7.2. 数据传输接口
ZNSKV 的键值存储引擎基于 RocksDB 实现,部分接口沿用 RocksDB 已有代码。FileSystem 类是 RocksDB 封装的 一层与文件系统交互的存储访问接口,提供了对文件操作的抽象接口类,本方案使用 到的主要包括:
(1) class FSWritableFile:对文件进行顺序写
(2) class FSSequentialFile:对文件进行顺序读
(3) class FSRandomAccessFile:对文件进行随机读
RocksDB 在执行合并排序写入文件时,使用 class FSWritableFile 中的 append 接 口对数据进行顺序写入。因此在 class FSWritableFile 中添加成员 lifetime 来记录文件 寿命预测模块所预测出的文件寿命信息。在 ZenFS 中,class ZonedWritableFile 继承 了 class FSWritableFile,每次 RocksDB 进行写入新的文件时文件系统都会调用 ZonedWritableFile 中的成员创建一个文件 ZoneFile 并将文件的寿命信息传递到 ZoneFile 中。ZoneFile 对象会具体实现数据顺序写入的 append 操作,append 接口会 根据 ZoneFile 携带的文件寿命信息完成数据写入。除了数据读写接口,ZenFS 中还 额外添加了用于数据迁移的接口 MigrateExtents,在 RocksDB 中可通过这个接口对指 定的数据以 extent 粒度进行迁移,具体迁移操作在数据迁移模块中实现。
系统中的主要数据结构:
首先,ZNS SSD 中包含若干个 zone 的存储资源,将这些存储资源划分成两部分,一部分存储系统元数据称为 Journal Zones,对应 图中的元数据分区;另一部分存储普通数据称为 Data Zones,对应图中的数据分区。
其次,系统中有多种管理数据的结构,如 RocksDB 中以 FSWritableFile 结构管理写 入文件,以 FileMetaData 结构管理 SSTable 文件信息。ZenFS 中以 Zonefile 结构管理 文件,每个 Zonefile 会对应一个 WritableFile,而 Zonefile 会划分为更小粒度的 extent 结构写入 zone 中。
最后,设备状态以 ZonedBlockDevice 结构进行管理,包括设备的 容量信息和 zone 状态信息等。
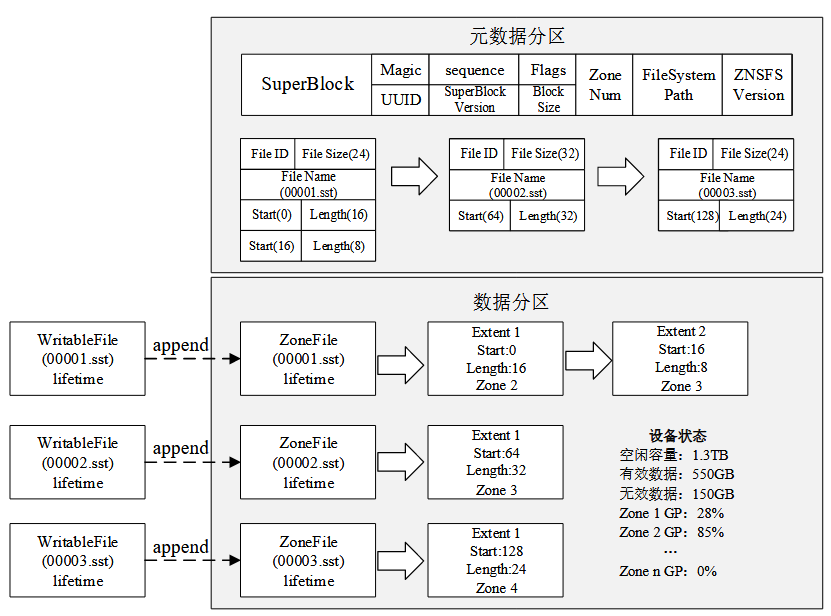
文件系统定义了两种类型的 zone,称为 Journal Zones 和 Data zones.在 ZonedBlockDevice 类中分别用 vector<Zone *> meta_zones 和 vector<Zone *> io_zones 两个容器对 Journal Zones 和 Data zones 进行管理,需要获 取 Journal Zones 和 Data zones 资源时需要访问这两个容器。


Journal Zones 存储有文件系统的 元数据,包括 superblock 以及文件与逻辑地址的映射关系。其中 superblock 主要用来 初始化 ZenFS 或者在 ZenFS 异常后从 ZNS SSD 读取相关数据进行恢复。
Data zones 则主要用于保存 SSTable 和 WAL 这样的数据文件。普通文件数据进行写入时都是在 io_zones 集合中获取可用的 active zone 和 open zone 资源,active zone 和 open zone 数量存在上限,该限制通过成员变量 active_io_zones_和 open_io_zones_来控制。
当 active_io_zones_和 open_io_zones_达到上限值时就不可再申请新的 active 和 open zone 资源,max_nr_active_io_zones_和 max_nr_open_io_zones_分别维护二者的上限值。
ZenFS 会将文件系统元数据写入 ZNS SSD 中前三个 zone 中,这三个 zone 称为 Journal zones,其中两个作为滚动缓存区保证随时都能够有空间存储元数据,同一时刻只有 一个 Journal zone 处于活跃状态,当前 Journal zone 写满后会切换到另一个 Journal zone 进行写入。额外的第三个 Journal zone 作为替补,会在有 Journal zone 处于离线状态时进行替换。
文件数据管理:RocksDB 以 FSWritableFile 类管理写入文件.

FSWritableFile 以 append 接口向 ZNS SSD 追加写入 数据,写入的数据附带寿命信息 lifetime 以及写入优先级信息 IOPriority。

Zonefile 是 ZenFS 用于管理文件的对象,每当有 FSWritableFile 对象创建时,ZenFS 会相应的在文件系统中创建一个 Zonefile 对象对其进行管理,FSWritableFile 所附带的相关元数 据信息会传递到 Zonefile。

Zonefile 中的数据以 extent 为单元写入 Data Zones 中 。Zonefile 文件会被写入到一个 extent 集合 std::vector<ZoneExtent*> extents_中。
extent 是一个变长 但是 block 对齐的连续 LBA 地址,其会被顺序写入 zone 内。每个 zone 能够存储多 个 extent,但是一个 extent 不会跨越多个 zone 存储。extent 的分配和释放都是一个内 存数据结构来管理的,当一个文件变更或者这个 extent 的数据持久化到 ZNS SSD 时, 内存的数据结构也会对应持久化到 journal_zone 之中。而且内存中这个数据结构会持 续跟踪 extent 的状态,每个 extent 只对应一个 zone,所对应的 zone 由 zone 指针维护.
zone 的数据结构维护有有效数据容量信息,当 extent 被删除后 zone 有效数据容量会减去该 extent 占用的容量。Zone 类维护了每个 zone 的起始地址和最 大容量信息,维护的可用容量信息会随着数据的写入不断进行更新,另外还会维护 zone 内存储的有效数据大小,当 zone 的有效数据为 0 时就可以进行重置操作。另外, 每个 zone 会维护自己的寿命信息,其寿命等于第一个写入其中的 Zonefile 的寿命。
SSTable、Zonefile、extent 以及 zone 之间可以直接或间接的建立映射关系,这些映射 关系可以形成一个快照以供 Compaction-GC 模块和数据迁移模块使用。
zone分配算法实现:RocksDB 采用 append 接口将文件数据传 输到 ZenFS,然后 ZenFS 会具体处理 append 接口下发的数据写入请求,将数据顺序 写入到合适的 zone 内。为了更好的将 extent 存储在寿命相近的的 Data zones 内,ZenFS 会在处理数据写入请求的时候调用分配函数,在处于打开状态的 Data zones 中 选取最佳的 zone 进行写入,选取的流程如图所示:
3.7.3. 合并排序文件选取策略
Compaction-GC 文件选取:ZNSKV 通过修改 RocksDB 原有的合并排序功能实现 Compaction-GC 模块。
Compaction-GC 的触发条件有两类:文件个数和文件大小。
对于 L0 层的合并,触发条件是 SSTable 文件个数,通过参数 level0_file_num_compaction_trigger 控制,Score 通过 SSTable 文件数目与 level0_file_num_compaction_trigger 的比值得到。
L1-Ln 层的合并触发条件是 SSTable 文件总大小,通过参数 max_bytes_for_level_base 和层级放 大系数 m 来控制每一层的容量阈值,Score 是本层当前的实际容量与本层容量阈值 的比值。
ZNSKV 中通过一个任务队列维护合并排序任务流.
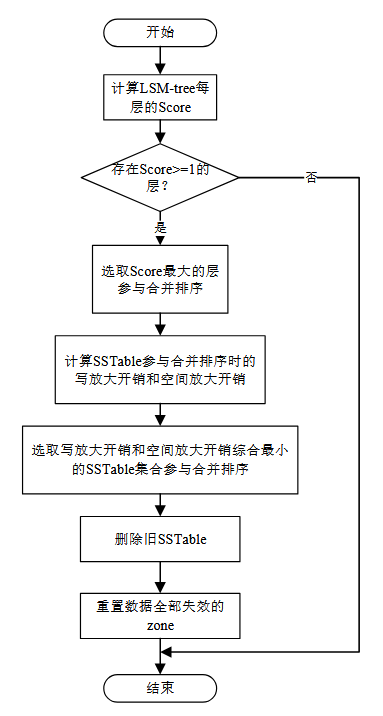
文件选取策略决定了参与合并排序操作的文件。 合并文件选取是设计的核心内容,选取何种文件进行合并操作与键值存储系统的写 放大密切相关。
文件的选取主要包含如下几个部分:1ZNS SSD 快照信息获取;2 找出 Ln+1 与当前文件存在键范围重叠的 SSTable 文件;3计算当前文件以及 Ln+1 层 与当前文件存在键范围重叠的文件所在 zone 的无效数据占比,根据公式来计算文件合并优先级;4在 Ln 层选取 Pri 值最大的文件。
自适应文件选取: 自适应文件选取会根据设备当前空闲容量来调整文件选取时合并排序写放大和 垃圾回收写放大之间优化的权重。设备空闲容量足够时主要偏向于降低合并排序写 放大,设备空闲容量不足时主要偏向于降低垃圾回收写放大。
ZNS SSD 内的空闲容量是会动态变化的, 在此文件系统向键值存储引擎提供了对设备状态访问的接口函数 GetFreeSpace(),用 于获取设备中剩余的空闲容量 vailid,在挂载文件系统时可以获取设备总容量 capacity。

垃圾回收效率的权重 k 值需要根据实际 的已使用容量占比 P 值动态变化,垃圾回收的效率由 k 值来调控。一开始设备空闲 容量充足,k 值随 P 值的增大缓慢提升,因为 p 值较小时说明空闲空间容量还足够使 用。当 p 值超过 70%时,存储设备面临存储即将空间不足的问题,此时 k 值增大的 幅度有所提高,在选取文件进行合并排序时更优先的考虑对垃圾回收写放大的影响, 尽快清理无效数据,回收存储空间。
低开销数据迁移:键值存储系统中“孤寡文件”和“多子文件”的存在依旧会降低 ZNS SSD 的空间利用率。 在此实现了数据迁移功能,将“孤寡文件”和“多子文件”文件所对应的部分 extent 数据迁移到其他 zone 中。
数据迁移功能的实现包括三部分,首先是在键值存储引擎 中识别需要迁移的数据,其次是在文件系统中处理数据迁移,最后要更新元数据保证 数据一致性。
ZNSKV 会在键值存储引擎中识别出需要迁移的 extent 集合,并将集合中的 extent 指针通过数据迁移接口 IOStatus MigrateExtents()发送到文件系统进行处理。extent 具体的迁移操作在文件系统中完成,迁移流程如图所示。
在 RocksDB 中获取 ZNS SSD 所有 zone 的快照信息.
4. LifetimeKV
4.1. 总结
RocksDB+ZenFS改造实现
键值存储引擎层:基于 SST 文件裁剪的范围合并排序算法和基于生命周期的合并文件选取策略
用户态文件系统层:添加了分层数据布局模块和自适应垃圾回收模块。

















 2447
2447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









