




 本文介绍了如何处理笑脸数据集(genki4k)和口罩数据集,涉及SVM、CNN模型的训练与测试。首先,对数据集进行正负样本划分,并进行预处理。接着,构建小型卷积网络,训练模型并评估精度。同时,展示了使用摄像头采集人脸和训练口罩检测模型的过程,最终能成功识别戴口罩和未戴口罩的人脸。
本文介绍了如何处理笑脸数据集(genki4k)和口罩数据集,涉及SVM、CNN模型的训练与测试。首先,对数据集进行正负样本划分,并进行预处理。接着,构建小型卷积网络,训练模型并评估精度。同时,展示了使用摄像头采集人脸和训练口罩检测模型的过程,最终能成功识别戴口罩和未戴口罩的人脸。
文章目录
掌握笑脸数据集(genki4k)正负样本的划分、模型训练和测试的过程(至少包括SVM、CNN
训练数据集
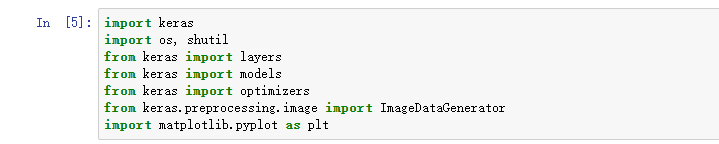
导入keras:

需要导入的库:
import keras
import os, shutil
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
————————————————
效果:
对数据集设置训练测试集、正负样本路径
train_dir='./smile/train'
train_smiles_dir='./smile/train/smile'
train_unsmiles_dir='./smile/train/unsmile'
test_dir='./smile/test'
test_smiles_dir='./smile/test/smile'
test_unsmiles_dir='./smile/test/unsmile'

定义打印出训练集和测试集的正负样本尺寸函数
 # 定义构建小型卷积网络并进行数据集预处理函数
# 定义构建小型卷积网络并进行数据集预处理函数

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









