




 本文介绍了Python在处理文本和二进制数据方面的强大能力,包括CSV和JSON文本格式的读写,pickle序列化存储,以及如何使用数据库进行高效数据管理。
本文介绍了Python在处理文本和二进制数据方面的强大能力,包括CSV和JSON文本格式的读写,pickle序列化存储,以及如何使用数据库进行高效数据管理。
读写文本格式的数据
因为其简单的文件交互语法、直观的数据结构,以及诸如元组打包解包之类的便利功能,Python在文本和文件处理方面已经成为一门招人喜欢的程序语言。
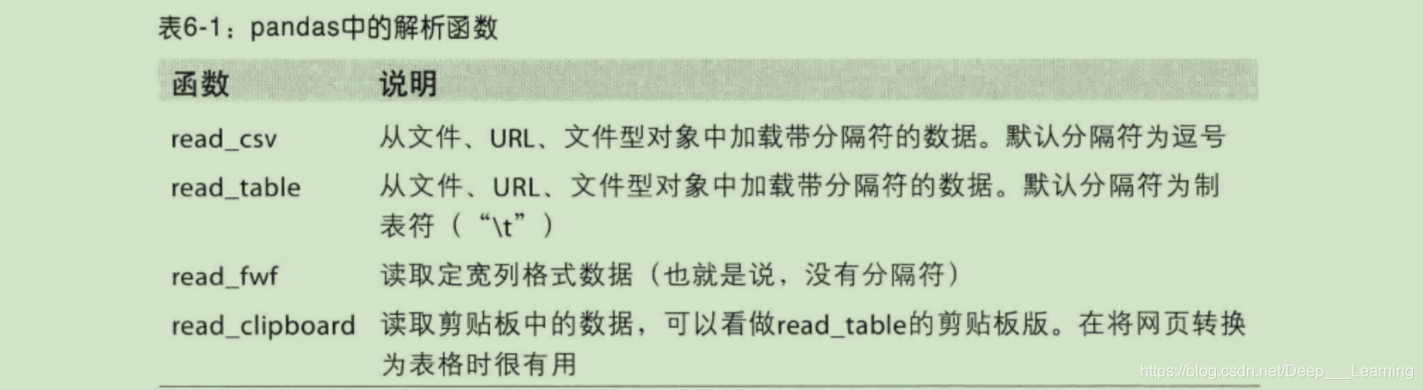



Python内置CSV模块读文件
import csv
f = open('test.csv')
reader = csv.reader(f)
for line in reader:
print(line)

JSON数据

import json
# 将json字符串转换成Python形式
result = json.loads(obj)
# 将Python对象转换成json格式
json_obj = json.dumps(result)
二进制数据格式
实现数据的二进制格式存储最简单的办法之一是使用Python内置的pickle序列化。为了使用方便,pandas对象都有一个用于将数据以pickle形式保存到磁盘上的save方法。
import pandas as pd
frame = pd.read_csv('test.csv')
# 数据保存
frame.save('frame_pickle')
# 数据读取
frame = pd.load('frame_pickle')
使用数据库
在许多应用中,数据很少取自文本文件,因为用这种方式存储大量数据很低效。基于SQL的关系型数据库使用非常广泛,此外有一些非SQL型数据库也变得非常流行。数据库的选择通常取决于性能、数据完整性以及应用程序的伸缩性需求。
import pandas.io.sql as sql
sql.read_frame('select * from test', con)
import pymongo
con = pymongo.Connection('localhost', port=27017)
tweets = con.db.tweets
# 保存数据
tweets.save(data)
# 查找数据
cursor = tweets.find({'from_user': 'zhangsan'})
tweet_fields = ['create_at','from_user','id','text']
result = DataFrame(list(cursor), columns=tweet_fields)


















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









