







引言:企业级AI Agent的核心价值在于通过自主决策、任务拆解与持续学习能力,提升业务效率,而DeepSeek-R1开源生态定位为生产级Agent开发框架,提供从模型微调到工具链集成的全栈支持,其典型企业级应用场景覆盖客户服务(智能工单处理)、数据分析(实时库存预测)及自动化流程(财务报告生成),技术栈全景则整合五大关键模块:RAG增强领域知识检索、目标驱动的规划引擎、分层记忆管理、多工具动态集成以及TEE安全沙箱监控,形成闭环的企业级智能体解决方案。
模块一:企业知识引擎(核心RAG优化)

技术案例:金融合规文档实时问答系统
1.系统核心逻辑:像开发“智能搜索引擎+文档解析器”
核心目标:让AI实时回答金融政策问题(如“跨境转账额度限制是多少?”),并确保答案严格来自最新合规文件(而非模型臆想)。
技术流程开发场景:
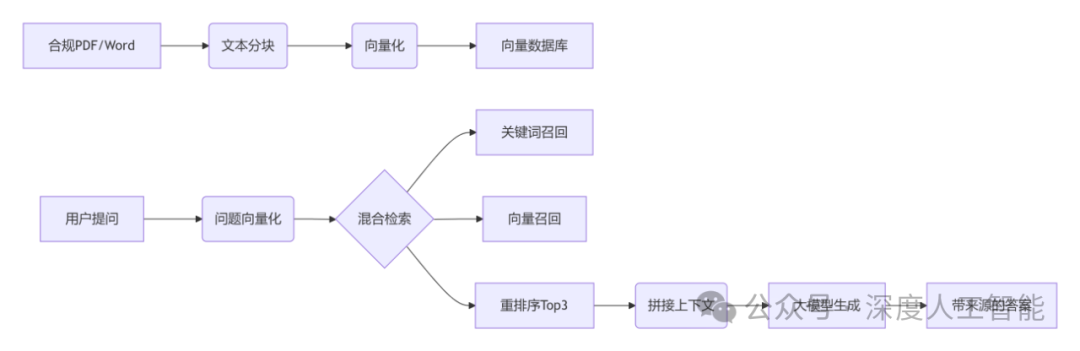
(1)文档预处理 → 相当于建数据库索引
将PDF/Word等非结构化文档,拆解为带语义的“知识碎片”(文本分块)
为每个碎片生成向量指纹(文本向量化)
存入向量数据库(如PgVector/FAISS)
Python# 示例:文档分块与向量化(LangChain实现)from langchain_text_splitters importRecursiveCharacterTextSplitterfrom langchain_community.embeddings import HuggingFaceEmbeddings# 1. 文档分块(保留5%重叠防语义断裂)splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=26)chunks = splitter.split_documents("反洗钱政策.pdf")# 2. 生成向量(中文优化模型)embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")vector_db = FAISS.from_documents(chunks, embeddings) # 存入向量库
(2)用户提问 → 触发精准检索
当用户提问时(如“跨境转账额度限制是多少?”),首先将问题转化为向量,通过向量数据库(如FAISS)快速检索最相关的文本片段(TOP-K召回)。

为提高命中率,采用混合检索策略:关键词检索(如BM25)确保基础术语的精准匹配(如“额度限制”),向量检索则捕捉语义相似性(如“转账限额”与“跨境支付额度”的关联),两者结合既覆盖字面匹配又扩展语义联想,显著提升召回质量。
python# 混合检索示例(关键词+向量)from langchain.retrievers import BM25Retriever, EnsembleRetriever# 关键词检索器bm25_retriever = BM25Retriever.from_documents(chunks)# 向量检索器faiss_retriever = vector_db.as_retriever(search_kwargs={"k": 5})# 组合检索(权重可调)ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever],weights=[0.3, 0.7])relevant_docs = ensemble_retriever.invoke("跨境转账的额度限制?")
(3)生成答案 → AI“参考文档”写回答
将检索到的文本片段 + 用户问题 → 输入大模型(如DeepSeek)
Python# 提示词工程示例prompt_template = """你是一名金融合规专家,请严格根据以下知识片段回答问题:---{context}---问题:{question}要求:1. 答案必须来自上述片段2. 引用来源文件名+页码(例:《反洗钱指引[](@replace=10001)》第12页)3. 若片段未提及,回答“暂无相关条款”"""
2.金融场景专属优化技巧
痛点1:政策频繁更新 → 增量索引
方案:监听文档库变更,自动触发增量更新
Python# 文件监听+增量更新(伪代码)from watchdog.observers import Observerclass PolicyFileHandler(FileSystemEventHandler):def on_modified(self, event):if event.is_directory: returnupdate_vector_index(event.src_path) # 仅更新修改文件的向量observer = Observer()observer.schedule(PolicyFileHandler(), path="/policy_docs",recursive=True)observer.start()
痛点2:专业术语难理解 → 领域微调
方案:用金融语料微调Embedding模型
Python# 领域适配微调(LoRA高效微调)from peft import LoraConfig, get_peft_model# 加载基础模型model = AutoModel.from_pretrained("BAAI/bge-large-zh-v1.5")# 注入LoRA适配器(仅更新0.2%参数)lora_config = LoraConfig(r=8, target_modules=["query", "value"])tuned_model = get_peft_model(model, lora_config)tuned_model.train_on_domain_data("financial_corpus.jsonl") #金融语料训练
痛点3:避免“幻觉” → 答案可验证
方案:输出时强制关联原文位置

用户问:企业年报提交截止日是?
AI答:根据《上市公司信息披露管理办法》第24条(来源:policy_2024.pdf, P36),年报需在会计年度结束4个月内提交。
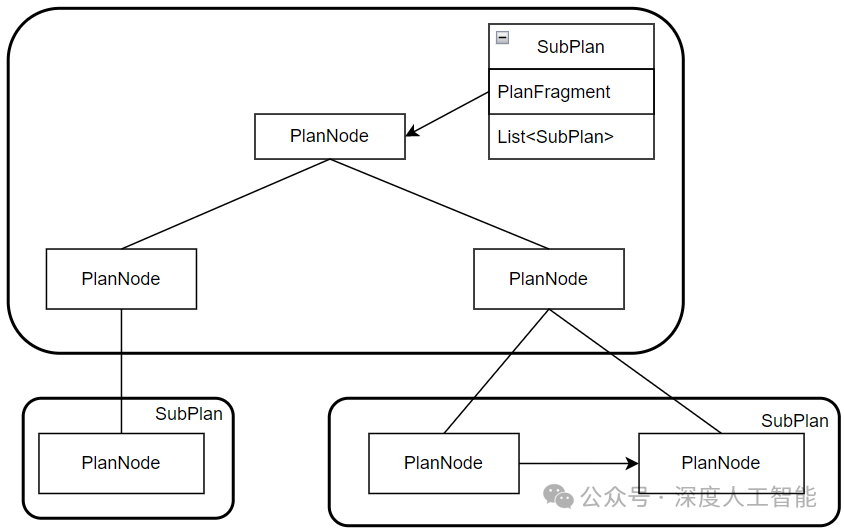
3.程序员理解架构图
问题:
1.当业务文档持续更新时,如何设计增量索引策略?
2.如何处理RAG中“拒答”与“幻觉”的平衡?
解答:
1.增量索引策略设计
当业务文档持续更新时,可采用主索引+增量索引的混合模式:主索引存储历史静态数据,增量索引仅处理新增或变更的文档,通过监听文件修改时间或数据库触发器捕获变更。
例如,金融合规场景中,通过文件系统监听器(如Python的watchdog)实时触发增量索引构建,并定期(如每周)将增量索引合并到主索引,确保数据时效性。对于数据库场景,可通过时间戳字段或变更日志表(如sph_counter)追踪增量数据,结合并行构建技术提升效率。

中“拒答”与“幻觉”的平衡
通过分层判断机制实现平衡:先基于检索结果的相关性分数(如BM25/向量相似度)设定阈值,低于阈值则直接拒答;对于可回答的问题,在生成阶段添加指令约束(如“仅引用来源”),并引入自修正逻辑(Self-RAG)检测生成内容与上下文的冲突。
例如,医疗问答中,若召回片段置信度不足,系统返回“暂无明确依据”;若生成答案与片段矛盾,则触发回溯重新生成或补充提示。

模块二:动态任务规划器(DAG工作流引擎)
技术案例:供应链预测自动化Agent
1.业务场景:像开发“智能流水线调度系统”
核心目标:自动完成供应链预测(如库存需求预测),将复杂任务拆解为并行子任务,动态调度资源并聚合结果。
传统流程vs DAG动态工作流
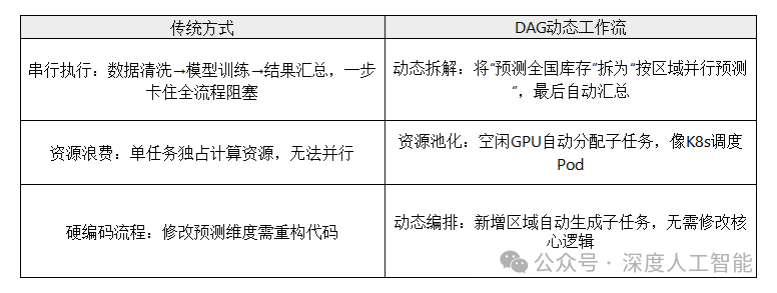
动态DAG工作流引擎的核心机制
(1)任务动态拆分(Fan-out)
触发条件:前序任务(如scan_data)输出待处理的数据分片(例:["华北", "华东", "华南"])
动态生成子任务:为每个分片启动独立预测任务(如predict-华北, predict-华东)
Python# 伪代码:Argo Workflows动态DAG示例- name: scan_datascript: |# 扫描OSS存储,返回区域列表echo '["north", "east", "south"]' > regions.json- name: predict# 根据scan_data输出动态生成子任务withParam: "{{tasks.scan_data.outputs.parameters.regions}}"
(2)并行执行与依赖控制
在并行执行与依赖控制中,拓扑排序通过分析任务间的有向无环图(DAG)依赖关系,自动识别无依赖任务(如“predict-华北”和“predict-华东”可并行执行),并确保依赖任务按拓扑序串行化。
同时结合资源池调度动态分配空闲GPU(如基于优先队列的负载均衡),避免资源争抢,并通过并发控制技术(如乐观锁或多版本控制)处理共享数据冲突,最终实现高吞吐与低延迟的并行计算。
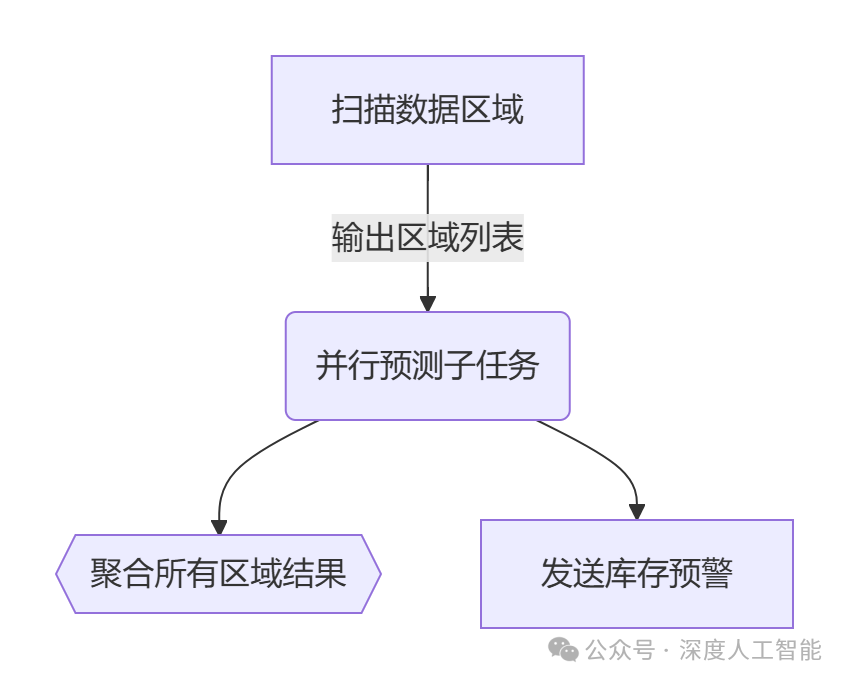
3)结果聚合(Fan-in)与异常处理
结果聚合:所有子任务完成后自动触发结果合并(如merge_results)
容错机制:子任务失败自动重试,重试超时则触发告警
Python# 伪代码:子任务状态监控if task.predict.status == "Failed":retry(task.predict, max_attempts=3)else:publish(task.predict.output)
3.技术案例:供应链预测自动化Agent的工作流
假设某电商需预测未来7天各区域仓库的库存需求:

动态拆分:
任务scan_warehouses扫描数据库,返回需预测的仓库ID列表(如["wh1", "wh2", "wh3"])
引擎自动为每个仓库生成预测子任务predict_wh1, predict_wh2...
Step2 并行预测:
每个predict_whX任务执行:
拉取该仓库历史销售数据→ 调用预测模型API → 输出需求量
所有子任务并行运行,占用不同GPU资源
Step3 聚合与决策:
任务merge_results汇总所有仓库预测值,计算总库存缺口
若缺口超过阈值,触发alert_task发送补货预警邮件
性能对比:

20个仓库需20分钟(1分钟/个)
DAG并行(10并发):仅需2分钟
4.解决的核心痛点
弹性伸缩:
当新增仓库时,scan_warehouses输出新ID列表,引擎自动扩容子任务,无需修改代码。
局部故障隔离:
predict_wh2任务失败时,仅重试该任务,不影响其他仓库预测。
资源利用率最大化:
空闲GPU自动分配任务,像K8s调度器动态分配Pod。
问题:
1.如何确保异常中断的任务状态可回溯?
2.循环依赖场景下如何防止死锁?
解答:
1.异常中断任务状态回溯方案
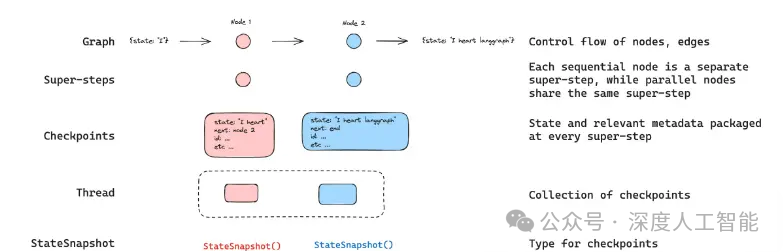
通过检查点(Checkpoint)机制和日志持久化实现状态回溯:检查点机制定期将任务处理进度(如数据偏移量、中间结果)保存到可靠存储(如HDFS、S3),支持从最近检查点恢复。例如,流处理系统Flink通过Barrier机制确保分布式快照一致性,故障时从快照重启。
日志持久化则记录关键操作(如事务ID、输入数据位置)到WAL(Write-Ahead Log),结合事件溯源(Event Sourcing)还原中断前的完整上下文。例如,Kafka消费者将消费偏移量提交到集群,中断后可重新定位。
2.循环依赖死锁预防策略

采用全局锁排序和超时熔断避免循环等待:全局锁排序强制所有任务按固定顺序获取资源(如统一按字母序锁定表A→B→C),破坏循环依赖条件。
例如,分布式事务中按主键哈希值排序锁定数据行。超时熔断为锁设置TTL(如Redis锁默认30秒过期),超时自动释放并触发补偿逻辑(如事务回滚)。结合心跳检测(如ZooKeeper临时节点)可区分网络延迟与真实死锁。
模块三:长期记忆管理(SQL+向量双引擎)
技术案例:个性化客户服务助手
1.双引擎如何分工:SQL记“硬数据”,向量存“软语义”
核心目标:让客服助手既能记住用户订单、资料等硬数据(SQL引擎),又能理解对话中的模糊语义(向量引擎)。
(1)SQL引擎(结构化记忆):
像关系型数据库一样存储用户资料、订单记录、服务工单等固定字段数据(如用户ID、订单号、时间戳)。
优势:支持精准查询(如SELECT * FROM orders WHERE user_id=123),确保订单状态、联系方式等硬信息100%准确。
(2)向量引擎(语义记忆):
将用户的历史提问、投诉描述等文本转换为向量(如512维数组),存入向量数据库。
作用:当用户说“上次那个物流问题”,即使没说订单号,也能通过向量相似度匹配历史对话(如“物流延迟”vs“快递没到”)。
2.协同工作流:一次用户请求的双引擎协作
假设用户询问“我上次反馈的快递问题解决了吗?”,系统会通过双引擎协同机制实现高效响应。

首先,向量引擎将问题文本转化为高维向量(如BERT嵌入),通过近似最近邻算法(如HNSW)在历史对话库中搜索语义相似的记录,例如匹配到30天前的工单“订单XX物流延迟,已补偿优惠券”并关联工单ID。
随后,SQL引擎基于工单ID执行结构化查询(如SELECT * FROM tickets WHERE ticket_id='XX'),从数据库精准提取订单号、处理人员、补偿金额等字段,确保数据完整性。最终,系统融合语义与结构化数据生成自然语言回复:“您2025-06-15反馈的订单XX物流问题已处理,补偿20元优惠券(有效期至2025-12-31)。”

向量索引技术(如量化压缩)可实现百万级对话库的毫秒级检索,而SQL引擎通过B+树索引避免全表扫描,响应时间控制在10ms以内。此外,高频工单结果缓存(如Redis)进一步减少重复计算,动态负载均衡则保障高并发场景下的稳定性。
这一流程不仅适用于快递查询,还可扩展至电商售后、金融工单等需结合语义理解与数据检索的场景。
3.解决哪些业务痛点
企业级AI Agent通过跨会话记忆技术(如向量引擎存储语义上下文)解决用户重复描述问题痛点,实现隔天对话仍能关联历史工单;同时采用双引擎协同机制——SQL引擎精准处理优惠券金额、有效期等结构化数据,向量引擎解析模糊表达(如“上次的物流问题”),兼顾准确性与灵活性。

动态更新能力,在生成新工单时自动完成SQL记录插入与对话文本向量化存储(增量索引),确保业务数据与语义记忆实时同步。
4.技术选型实例
SQL引擎:PostgreSQL(事务保障数据一致性)
向量引擎:
PostgreSQL + pgvector扩展(轻量级集成)
或 OceanBase(支持VECTOR数据类型,直接SQL操作向量)
Sql-- Ocean示例:建表时同时定义结构化字段和向量字段CREATE TABLE user_chat_logs (user_id INT PRIMARY KEY,order_id VARCHAR(20),issue_text VARCHAR(200),embedding VECTOR(512) -- 存储语义向量);
模块四:安全可控工具平台(Sandbox执行)
技术案例:Excel财务分析插件
1. 沙箱的核心作用:给插件套上“金鱼缸”

A,问题场景:财务分析插件需要执行复杂计算(如现金流预测、风险评估),但直接操作Excel可能:
误删关键数据:插件代码错误覆盖财务报表原始数据
执行恶意操作:第三方插件偷偷上传敏感数据到外部服务器
资源滥用:死循环计算耗尽系统内存
B.沙箱解决方案:
数据隔离:插件只能读写沙箱分配的虚拟表格,无法接触真实Excel文件
权限控制:禁止网络访问、文件删除等危险操作
资源限制:CPU/内存用量超阈值时自动终止进程
Python# 伪代码:沙箱执行流程def run_plugin_safely(plugin_code, excel_file):sandbox = create_sandbox() # 创建隔离环境sandbox.set_quota(cpu=50%, mem=1GB) # 限制资源用量virtual_sheet = sandbox.load_excel(excel_file) # 加载虚拟表格(非真实文件)try:result = sandbox.execute(plugin_code, virtual_sheet) # 在沙箱内运行插件return resultexcept RiskOperationError: # 拦截危险行为kill_process(sandbox) # 立即终止进程
2.安全控制的三重保险机制
A.操作权限白名单
沙箱仅开放必要的Excel API,其他操作一律禁止:

敏感行为实时监控
通过系统调用拦截技术动态检测风险操作:
尝试执行Shell命令 → 触发警报并终止
高频访问磁盘 → 冻结线程并记录日志
内存持续增长 → 强制垃圾回收
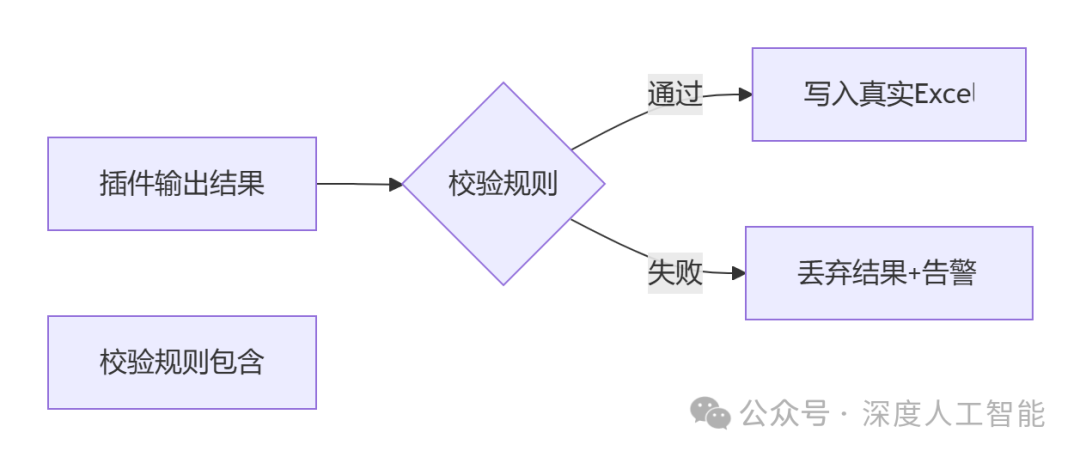
C.结果差分验证
插件输出结果需经过规则引擎校验才允许写入真实文件:
技术案例:现金流预测插件的工作流程
假设用户使用插件预测未来6个月现金流:

:环境初始化
沙箱加载真实Excel的只读副本,生成虚拟工作表
授予插件权限:读取历史流水表、写入预测结果区(其他区域只读)
Step2:安全执行
插件代码调用FORECAST()函数计算现金流
沙箱拦截了插件中os.system("rm -rf /")的恶意代码(记录到审计日志)
Step3:结果输出
校验发现预测值存在负现金流→ 自动添加高亮预警标记
仅允许修改预测结果区的单元格,原始数据保持只读
传统方式vs 沙箱模式对比

模块五:生产部署与监控(K8s+Dashboard)
技术案例:Prometheus监控看板
1.监控看板的核心角色:K8s的“健康仪表盘”
核心组件分工
(1)Prometheus:

定时抓取工厂设备(容器/Pod)的指标(如CPU使用率、内存占用),存储在时间序列数据库(TSDB)——相当于工厂的“运行日志库”。
主动拉取数据(Pull模式),通过scrape_config配置抓取目标(如K8s的API Server、Node Exporter)。
支持PromQL查询语言,可快速分析数据(如rate(http_requests_total[5m])计算请求速率)。
(2)Grafana:
Prometheus的“运行日志”转化为可视化的图表和仪表盘——像工厂监控室的实时数据大屏。
拖拽式配置图表(折线图、仪表盘、热力图等)。
预置模板快速导入(如K8s集群监控面板ID 13192)。
2.部署流程:三步搭建监控流水线
Step 1:部署数据采集层(Prometheus + 探针)
Bash# 创建监控专用命名空间kubectl create namespace monitoring# 部署Prometheus Operator(管理Prometheus的生命周期)kubectl apply -f prometheus-operator.yaml# 部署Node Exporter(采集主机指标)kubectl apply -f node-exporter.yaml
作用:
Node Exporter 收集每台主机(Node)的CPU、内存、磁盘等指标。
Kubelet 内置的 cAdvisor 自动收集容器资源使用情况。
Step 2:配置数据源与存储
Yaml# Prometheus配置文件片段(prometheus.yml)scrape_configs:- job_name: 'kubernetes-nodes'kubernetes_sd_configs: # 自动发现K8s节点- role: noderelabel_configs: # 重写标签便于查询- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100' # 将端口重定向到Node Exporter
动态发现K8s集群中的监控目标(如Pod、Node)。
数据存储在本地的TSDB中(可配置持久化卷避免重启丢失)。
Step 3:可视化展示(Grafana Dashboard)
连接数据源:在Grafana中添加Prometheus的URL(如http://prometheus:9090)。
导入监控模板:输入预置面板ID(如K8s监控面板),自动生成图表。
3.监控看板能解决哪些生产问题?
痛点1:故障定位慢

传统方式:日志翻查 + 手动拼接线索 → 耗时易漏。
Prometheus看板: 实时显示异常指标(如某Pod内存持续90%+),点击图表钻取关联日志(如Loki集成)。
示例:通过kube_pod_container_status_restarts_total快速定位频繁崩溃的容器。
痛点2:资源利用率不透明
:凭经验扩容缩容 → 资源浪费或瓶颈。
Prometheus看板: 图表展示集群CPU/内存水位,结合kube_pod_resource_request对比实际使用量→ 精准扩缩容。
示例:Grafana面板标记红色告警区(如Node磁盘使用率 > 85%)。
痛点3:缺乏历史性能基线

传统方式:临时抓取数据 → 难做趋势分析。
Prometheus看板: 存储所有历史指标,通过PromQL对比不同时段数据(如compare(http_requests_total, 1d))。
示例:发现每周一上午流量峰值 → 提前预扩容。
4.程序员如何快速上手?
关键配置技巧
指标抓取优化:
调整scrape_interval(如15s)平衡实时性与存储压力。
用metric_relabel_configs过滤无用指标(减少存储开销)。
告警集成:
在Prometheus中配置告警规则(如Pod持续重启 > 5次),推送至Alertmanager → 触发邮件/Slack通知。
持久化存储:
Yamlvolumes:- name: prometheus-datapersistentVolumeClaim:claimName: prometheus-pvc # 挂载云存储或本地卷
避坑指南
数据量爆炸:避免全量抓取,按需选择指标(如只监控业务关键Pod)。
网络隔离:生产集群配置RBAC,限制Prometheus仅访问监控命名空间。
版本兼容:确保Prometheus版本与K8s集群匹配(如v2.40+支持K8s 1.25)。
结语:
企业级AI Agent演进路线

企业级AI Agent的演进路线遵循从实验验证到生产落地的渐进路径:初期选择低风险场景(如客服、数据分析)进行试点,验证技术可行性后逐步扩展至核心业务(如供应链、财务),最终通过统一管理平台实现多Agent协同。
生产跨越的关键在于构建动态感知-决策闭环架构(如分层状态机设计),结合实时监控与反馈机制确保稳定性;持续学习设计需融合四维记忆网络(情景/语义/程序/情感记忆)与增量训练机制,通过强化学习优化策略迭代。
而DeepSeek开源生态通过“核心模型开源+垂直领域闭源”的分层策略(如7B参数开源、百亿级商用)降低行业门槛,依托开发者社区与硬件适配(如昇腾、英伟达)加速技术普惠,形成对抗闭源巨头的差异化优势。

官方服务号,专业的人工智能工程师考证平台,包括工信部教考中心的人工智能算法工程师,人社部的人工智能训练师,中国人工智能学会的计算机视觉工程师、自然语言处理工程师的课程培训,以及证书报名和考试服务。

















 2345
2345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









