




摘要:本文通过分析王者荣耀账号交易数据,构建并优化了多个机器学习模型,特别是引入了先进的知识增强网络(KAN)模型,以提高账号价格预测的准确性。同时,开发了基于PyQt5的界面,使得预测过程更加直观和便捷。通过本文你可以学习到,如何搭建一个回归模型,预测、保存模型、结果分析。

1 数据清洗
1.1 数据读取与信息查看
导入所需要的模块
import pandas as pd
from sklearn import datasets
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import metrics
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 显示负号
import warnings
import joblib # 用来保存模型
warnings.filterwarnings("ignore") # 忽略警告
读取数据
data=pd.read_csv("data.csv")
data.describe()
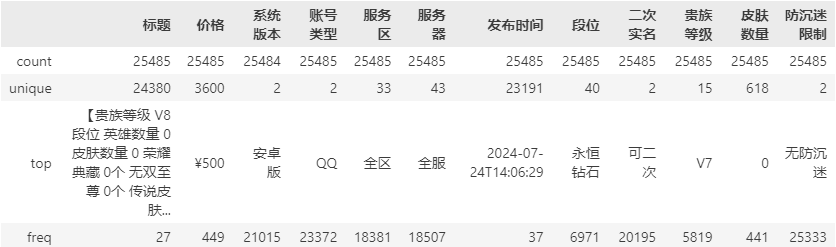
信息介绍:
标题:用户所填写的标题内容
价格:账号价格,也是我们搭建回归模型要进行预测的内容。
系统版本:安卓版、苹果版
账号类型:QQ、微信
服务器、服务区:全区全服、或者指定区
发布时间:用户所发布账号的时间
段位:无、青铜、铂金…、王者等等
二次实名:是否可以二次实名
贵族等级:V0-V10
皮肤数量:皮肤个数
防成迷限制:是否有防成迷限制
删除没有用的信息,其中标题、发布时间显然没有用,标题为其内容的整合,并无重要作用,发布时间也感觉大概率没有用。
data=data.drop("标题",axis=1)
data=data.drop("发布时间",axis=1)
data
1.2 数据映射
由于模型所接受的输入为数字,因此我们需要将文本映射为对应的数字。
将价格贵族等级、皮肤数量进行映射
data['价格'] = data['价格'].str.replace('¥', '').astype(float)
data['贵族等级'] = data['贵族等级'].str.replace('V', '')
data['贵族等级'] = pd.to_numeric(data['贵族等级'], errors='coerce')
data['贵族等级'].fillna(0, inplace=True)
data['皮肤数量'] = pd.to_numeric(data['皮肤数量'], errors='coerce')
data['皮肤数量'].fillna(0, inplace=True)
对文本进行映射,使用map函数和lambda表达式进行映射
data['系统版本'] = data['系统版本'].map({
'安卓版': 1, '苹果版': 0})
data['账号类型'] = data['账号类型'].map({
'QQ': 1, '微信': 0})
data['二次实名'] = data['二次实名'].map({
'可二次': 1, '不可二次': 0})
data['防沉迷限制'] = data['防沉迷限制'].map({
'无防沉迷': 1, '有防沉迷': 0})
data['服务区'] = data['服务区'].apply(lambda x: 1 if x == '全区' else 0)
data['服务器'] = data['服务器'].apply(lambda x: 1 if x == '全服' else 0)
data
采用同样的方式对段位进行映射,构建映射字典
rank_map={
"未知":0,"暂无段位":0,"无":0,'看商品描述':0,
"倔强青铜":1,
"秩序白银":2,"白银":2,
"荣耀黄金I":3,"荣耀黄金II":3,"荣耀黄金III":3,"荣耀黄金IV":3,"黄金":3,"荣耀黄金":3,
"尊贵铂金I":4,"尊贵铂金II":4,"尊贵铂金III":4,"尊贵铂金IV":4,"铂金":4,"尊贵铂金":4,
"永恒钻石":5,"永恒钻石I":5,"永恒钻石III":5,"永恒钻石II":5,"永恒钻石V":5,"永恒钻石IV":5,"钻石":5,
"至尊星耀":6,"至尊星耀V":6,"至尊星耀IV":6,"至尊星耀I":6,"至尊星耀III":6,"至尊星耀II":6,"星耀":6,
"最强王者":7,"至圣王者":8,"无双王者":9,"非凡王者":10,"绝世王者":11, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















 到【灌水乐园】发言
到【灌水乐园】发言








