




 本文探讨了层归一化(Layer Normalization)在循环神经网络(RNN)中的作用及其与批量归一化(Batch Normalization)的区别。层归一化通过依赖当前时间步中输入到层的总和进行归一化,并在整个时间步骤中共享一组增益(g)和偏置(b)参数。此外,还讨论了协变量偏移的概念及其在机器学习实践中的重要性。
本文探讨了层归一化(Layer Normalization)在循环神经网络(RNN)中的作用及其与批量归一化(Batch Normalization)的区别。层归一化通过依赖当前时间步中输入到层的总和进行归一化,并在整个时间步骤中共享一组增益(g)和偏置(b)参数。此外,还讨论了协变量偏移的概念及其在机器学习实践中的重要性。
- Encoder structure
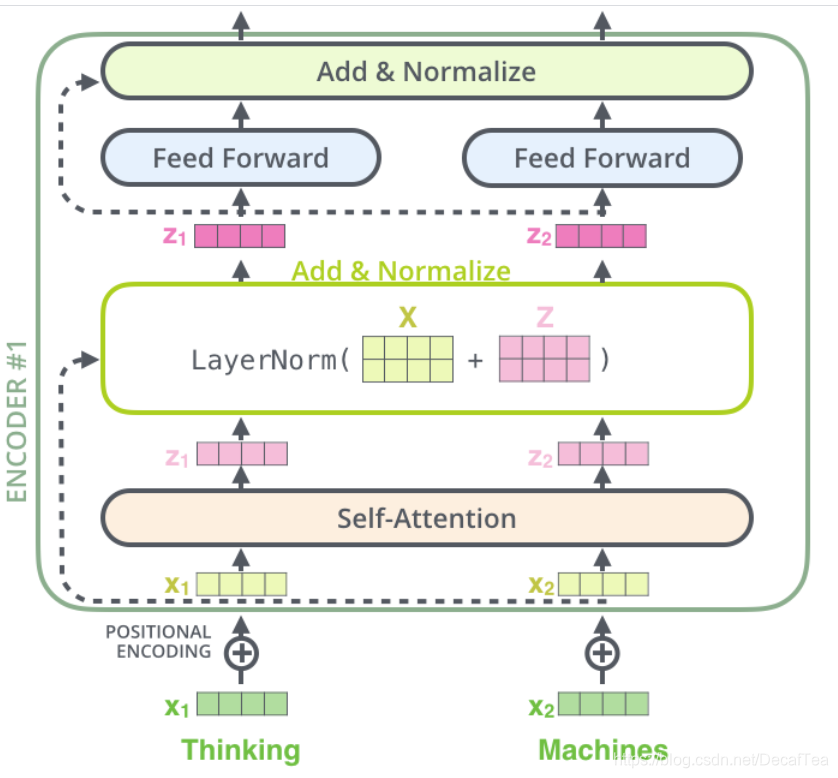
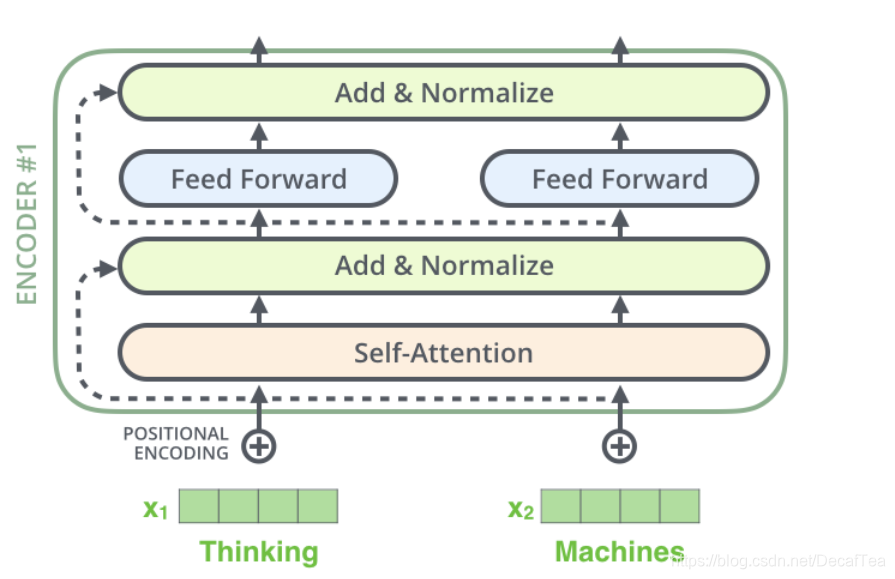
2. layer normalization:
-
什么是covariate shift?
Covariate shift is the change in the distribution of the covariates specifically, that is, the independent variables.

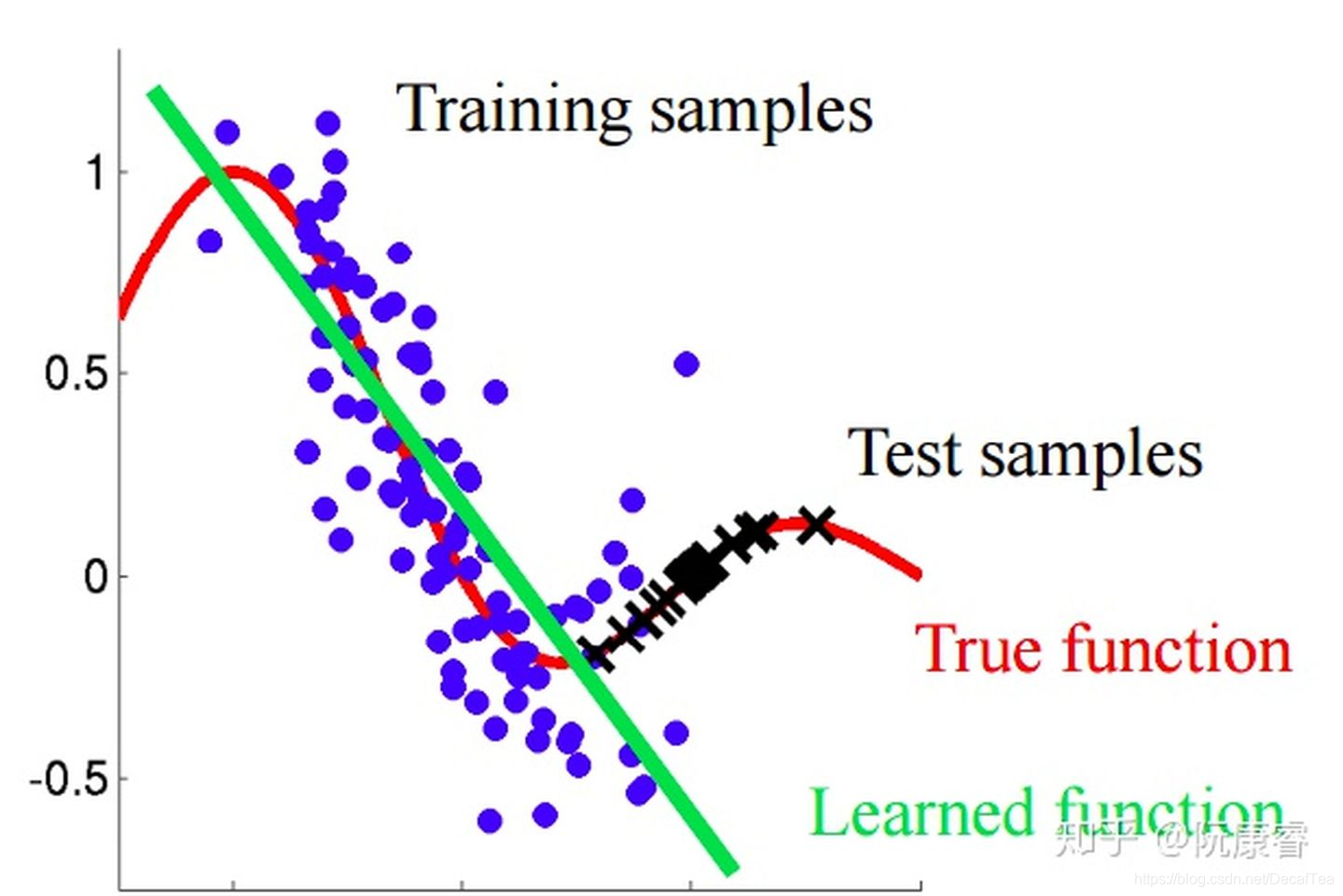
在机器学习实践中,我们一定要注意训练数据集和实际情况产生的数据分布不同而带来的影响。 -
batch norm vs layer norm
BN:

LN:

- Layer normalized recurrent neural networks

its normalization terms dependonly on the summed inputs to a layer at the current time-step. It also has only one set of gain (g) and bias (b) parameters shared over all time-steps.


















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









