



 本文详细介绍了SQL的执行顺序,重点讲解了FROM到LIMIT的执行步骤,以及窗口函数在OLAP和BI中的应用,比较了聚合函数和窗口函数的差异,还涵盖了COUNT(*)、COUNT(列名)和COUNT(1)的区别以及MySQL索引的使用和联合索引的匹配原则。
本文详细介绍了SQL的执行顺序,重点讲解了FROM到LIMIT的执行步骤,以及窗口函数在OLAP和BI中的应用,比较了聚合函数和窗口函数的差异,还涵盖了COUNT(*)、COUNT(列名)和COUNT(1)的区别以及MySQL索引的使用和联合索引的匹配原则。
1)你知道SQL的执行顺序是什么吗?
书写顺序:
SELECT -> DISTINCT -> FROM -> JOIN -> ON -> WHERE -> GROUP BY -> HAVING -> ORDER BY -> LIMIT
执行顺序:
FROM -> JOIN -> ON -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ORDER BY -> LIMIT
执行顺序解释:
1.from 要做数据分析,得先有个表
2.join 一个表可能还不够,两个表甚至多个表都可以,关联条件啥也先不用,可以都来个笛卡儿积先
3.on 在诸多表左右连接后,设定两个表之间的关联键,把不符合条件的全部筛掉
4.where 上三步整合各表,形成一个统一大表;在此大表上,设置筛选条件
5.group by 把指定字段相同的行组合在一起,其余没有加入group by的字段,可以用聚合函数如max/min等合并
6.having 在group by了之后,再度指定筛选条件;注意where和having是不同的,主要在于对分组后的结果进行筛选,且筛选条件中可以用聚合/窗口函数
7.select 在行层面的处理暂告一段落,在列层面再来一波
8.distinct 指定字段去重
9.order by 指定字段排序,升降序
10.limit 指定哪些行
2)窗口函数
窗口函数是OLAP函数,是对数据库数据进行实时分析处理。每条记录都要在此窗口内执行函数。SQL窗口函数为在线分析处理(OLAP)和商业智能(BI)提供了复杂分析和报表统计的功能,例如产品的累计销售额统计、分类排名、同比/环比分析等。这些功能通常很难通过聚合函数和分组操作来实现,某些库中,窗口函数也被称为在线分析处理(OLAP)函数,或者分析函数。
窗口函数、聚合函数的相同点:对一组数据进行分析并返回结果,
不同点:聚合函数将同一个分组内的多行数据汇总成单个结果,而窗口函数则保留了所有的原始数据,为每一行数据都返回一个结果。
如下图所示。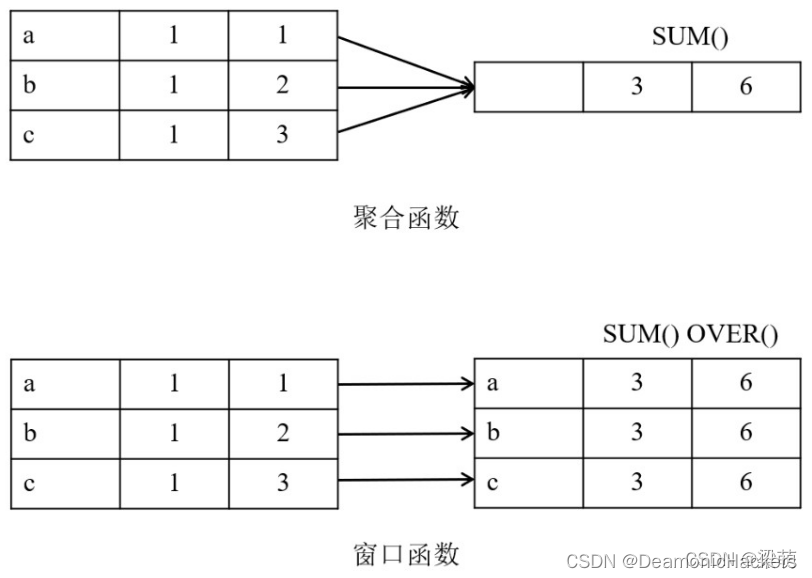
以下语句中的SUM()是一个窗口函数:
SELECT emp_name AS "员工姓名",
SUM(salary) OVER () AS "所有员工月薪总和"
FROM employee;SELECT emp_name AS "员工姓名",
SUM(salary) OVER () AS "所有员工月薪总和"
FROM employee;
其中,关键字OVER表明SUM()是一个窗口函数。括号内为空,表示将所有数据作为一个分组进行汇总。该查询返回的结果如下:
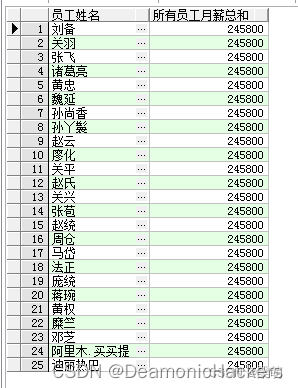
以上查询结果返回了所有的员工姓名,并且通过聚合函数SUM()为每个员工都返回了相同的汇总结果。
从以上示例中可以看出,窗口函数的语法与聚合函数的不同之处在于,它包含了一个OVER子句。OVER子句用于指定一个数据分析的窗口,完整的窗口函数定义如下:

其中window_function是窗口函数的名称,expression是可选的分析对象(字段名或者表达式),OVER子句包含分区(PARTITION BY)、排序(ORDER BY)以及窗口大小(frame_clause)3个选项。
3.指定窗口大小
窗口函数OVER子句中的frame_clause选项用于指定一个移动的分析窗口,窗口总是位于分区的范围之内,是分区的一个子集。在指定了分析窗口之后,窗口函数不再基于分区进行分析,而是基于窗口内的数据进行分析。
窗口选项可以用于实现各种复杂的分析功能,例如计算累计到当前日期为止的销售额总和,每个月及其前后各N个月的平均销售额等。
指定窗口大小的具体选项如下:![]()
其中,ROWS表示以数据行为单位计算窗口的偏移量,RANGE表示以数值(例如10天、5km等)为单位计算窗口的偏移量。
frame_start选项用于定义窗口的起始位置,可以指定以下内容之一:
●UNBOUNDED PRECEDING——表示窗口从分区的第一行开始。
●N PRECEDING——表示窗口从当前行之前的第N行开始。
●CURRENT ROW——表示窗口从当前行开始。
frame_end选项用于定义窗口的结束位置,可以指定以下内容之一:
●CURRENT ROW——表示窗口到当前行结束。
●M FOLLOWING——表示窗口到当前行之后的第M行结束。
●UNBOUNDED FOLLOWING——表示窗口到分区的最后一行结束。
下图说明了这些窗口大小选项的含义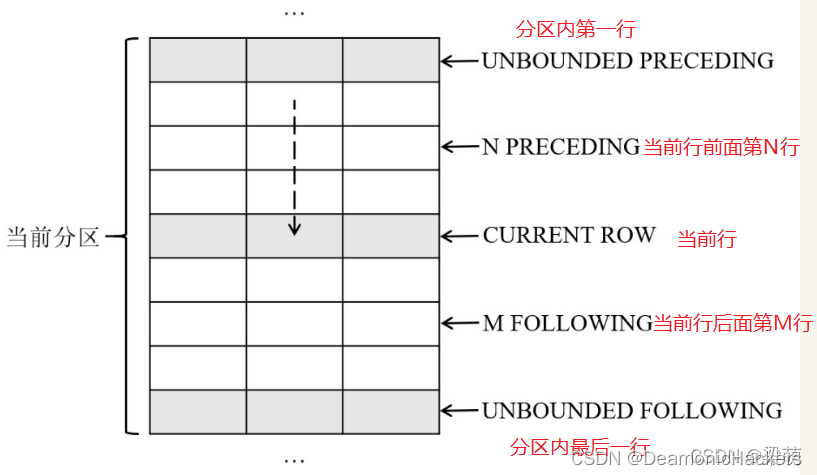
下面语句表示分析窗口从当前分区的第一行开始,直到当前行结束,即对应到图中前面5行记录。ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
3)你主要用过哪些窗口函数
聚合、跨行取值、排名窗口函数
1.聚合窗口函数
许多常见的聚合函数也可以作为窗口函数使用,包括AVG()、SUM()、COUNT()、MAX()以及MIN()等函数。
PS:对于聚合窗口函数,如果没有ORDER BY选项,默认窗口大小就是整个分区。
如果指定了ORDER BY选项,默认的窗口大小就是分区的第一行到当前行。
因此,以上示例语句中的ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW选项可以省略。省略后的语句和结果:

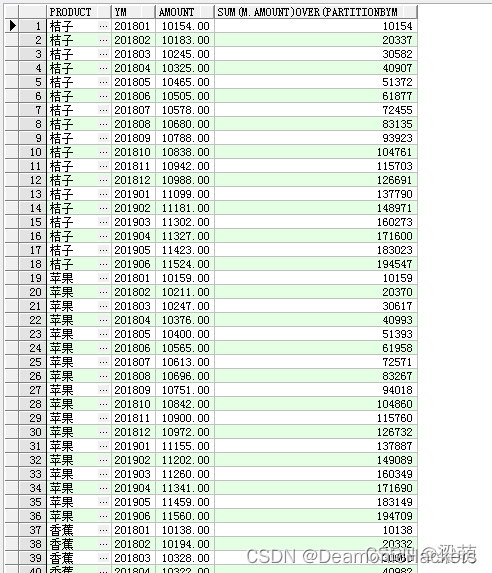
如果去掉ORDER BY选项,查询的窗口大小就是整个分区,如下图所示:
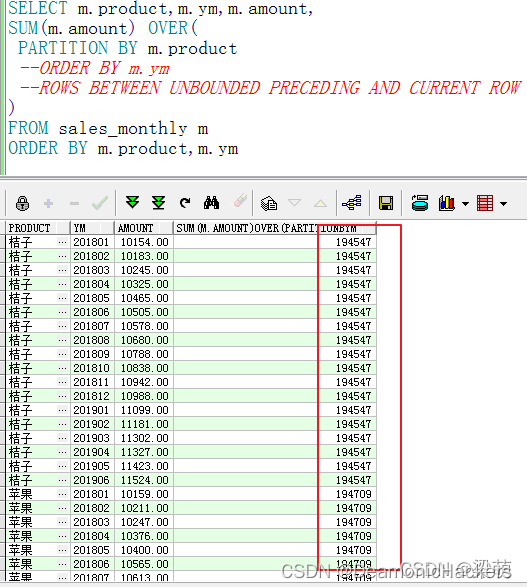
这时,合计值就变成了分区内所有记录的合计。
2.排名窗口函数
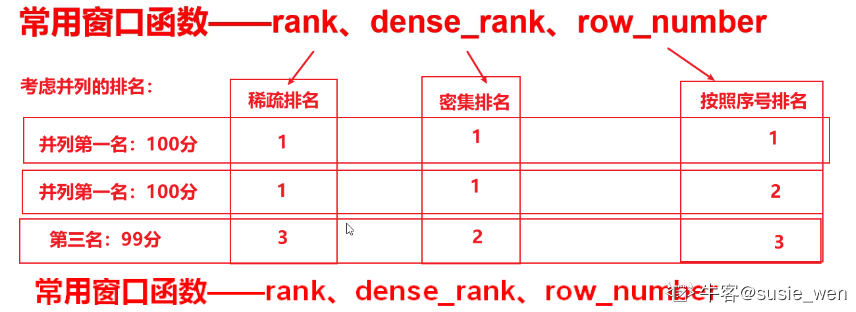
排名窗口函数用于对数据进行分组排名,包括ROW_NUMBER()、RANK()、DENSE_RANK()、PERCENT_RANK()、CUME_DIST()以及NTILE()等函数。
①ROW_NUMBER函数可以为分区中的每行数据分配一个序列号,序列号从1开始。
②RANK函数返回当前行在分区中的名次。如果存在名次相同的数据,后续的排名将会产生跳跃。
③DENSE_RANK函数返回当前行在分区中的名次。即使存在名次相同的数据,后续的排名也是连续值。
④PERCENT_RANK函数以百分比的形式返回当前行在分区中的名次。如果存在名次相同的数据,后续的排名将会产生跳跃。
⑤CUME_DIST函数计算当前行在分区内的累积分布。
⑥NTILE函数将分区内的数据分为N等份,并返回当前行所在的分片位置。
3.取值窗口函数
取值窗口函数用于返回指定位置上的数据行,包括FIRST_VALUE()、LAST_VALUE()、LAG()、LEAD()、NTH_VALUE()等函数。
示例表和脚本
4)rank、row_number、dense_rank三者的区别?
5)count(*)和count(列名)和count(1)的区别?
执行效果上:
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略为NULL的值。
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略为NULL的值。
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是指空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上:
- 列名为主键,count(列名)会比count(1)快
- 列名不为主键,count(1)会比count(列名)快
- 如果表多个列并且没有主键,则 count(1 的执行效率优于 count(*)
- 如果有主键,则 select count(主键)的执行效率是最优的
- 如果表只有一个字段,则 select count(*)最优。
6)你有使用过mysql索引吗?
7)mysql如何查看索引?
查看表的索引:
show index from table_name(表名)
8)写了一个sql,如何查看是否有命中索引?
MySQL提供了EXPLAIN语句来查看查询的执行计划,通过执行计划我们可以判断索引是否被命中。EXPLAIN语句可以使用以下方式执行:
explain select * from table_name where column_name='value';
执行上述语句后,MySQL会返回一张表,其中包含执行计划的相关信息。我们可以通过查看表中的一些字段来判断索引是否被命中。
根据返回的执行计划,我们可以采用以下几种方法来判断索引是否命中:
- 检查type字段:如果type字段的值是index或range,表示索引被命中;如果type字段的值是ALL,则表示索引未被命中。
- 检查possible_keys字段和key字段:如果possible_keys字段和key字段都不为空,且其值相同,表示索引被命中;如果possible_keys字段和key字段都为空,表示索引未被命中。
- 检查Explain Extra字段:如果Extra字段中包含Using index或Using where,表示索引被命中;如果Extra字段中包含Using temporary或Using filesort,表示索引未被命中。
9)联合索引你知道吗?联合索引的匹配原则是什么?
联合索引(Compound Index)是一个包含多个列的索引。联合索引可以在多个列上同时进行查询优化,有助于提高多列查询的性能。在创建联合索引时,需要考虑列的顺序,因为索引的使用受到最左前缀原则的限制。
对于索引中的字段,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。


















 5246
5246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









