



 文章详细阐述了SQL中的计数函数count(*)、count(1)和count(列名)的执行效果和效率差异,以及在不同场景下的选择。同时,讨论了SQL查询的执行顺序、聚合函数的使用规则,特别是GROUPBY和HAVING子句的差异。此外,还介绍了Oracle数据库中的窗口函数row_number、lead和lag的用法,以及它们在数据分析和查询中的作用。
文章详细阐述了SQL中的计数函数count(*)、count(1)和count(列名)的执行效果和效率差异,以及在不同场景下的选择。同时,讨论了SQL查询的执行顺序、聚合函数的使用规则,特别是GROUPBY和HAVING子句的差异。此外,还介绍了Oracle数据库中的窗口函数row_number、lead和lag的用法,以及它们在数据分析和查询中的作用。
count(*) 和 count(1)和count(列名)区别
执行效果上 :
count(*)包括了所有的列,相当于行数,在统计结果的时候, 不会忽略列值为NULL
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候, 不会忽略列值为NULL
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数, 即某个字段值为NULL时,不统计。
执行效率上:
列名为主键,count(列名)会比count(1)快
列名不为主键,count(1)会比count(列名)快
如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
如果有主键,则 select count(主键)的执行效率是最优的
如果表只有一个字段,则 select count(*)最优。
oracle执行顺序
from——>where——>group by——>having——>select——>order by——>limit...
聚合函数
有聚合函数count()、sum()、avg()、max()等一定要有group by
2.用了group by ,select不一定非要有聚合函数。用了group by后相当于对group by后面的字段进行去重。例如group by id,date后,只能查询到对id,date去重后的每组的第一行数据(但是可以统计分组后的聚合数据),也就是分组之后之前的单条数据只能用到每组的第一条了
3.group by role(非主键)的时候,select只能包含聚合函数和role(group by的字段),否则报错
例:按小组号分组后,可以查询小组的组号,整个小组所有个人的聚合信息如总分、平均分最高分等。但是不能对个人的分数和个人信息等就不能算是小组的信息了,不能放在select里查询
where 和 having
where 先执行,只能筛选表里有的东西,如若想对聚合后的结果进行筛选则必须用having
开窗函数row_number()和group by的区别
over partition by会把每个数据的明细都显现出来,聚合显示多条
group by 聚合只会显示一条
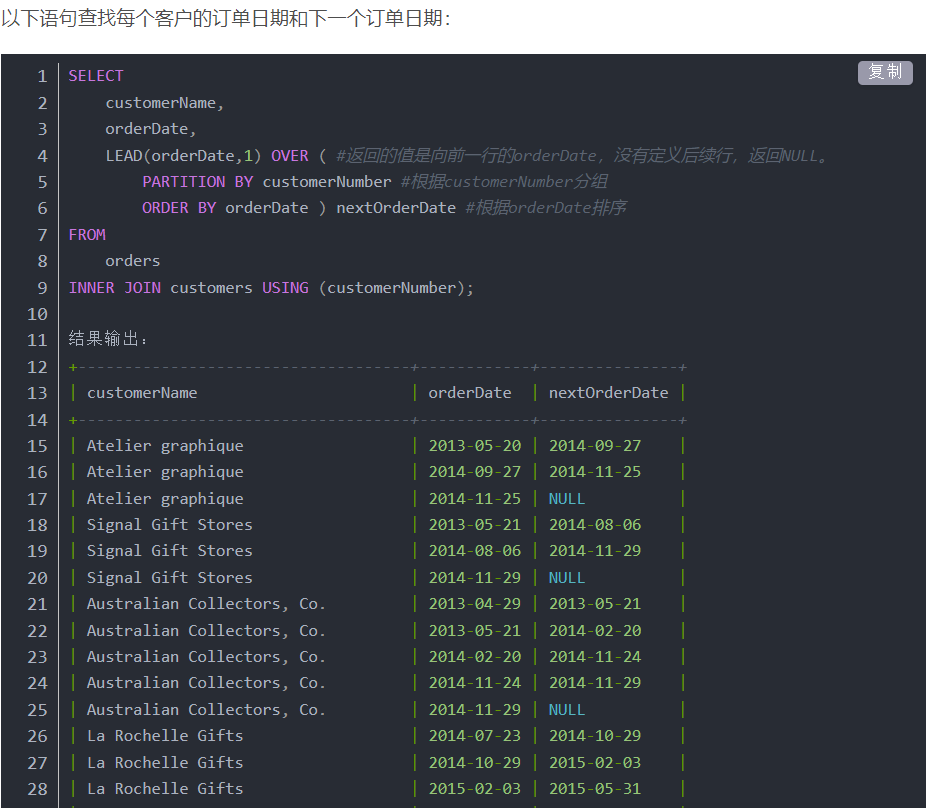
lead()和lag()函数:lag取当前行之前的数据,lead取当前行之后的数据
用法:num,lead(num,参数1,参数2) over(partition by id order by date) as nextnum
参数1规定隔几行取一次,为0时取num
参数2设定下一行没数时返回的默认值,参数2为空时默认为null
LAG语法:LAG(<expression>[,offset[, default_value]]) OVER ( PARTITION BY expr,... ORDER BY expr [ASC|DESC],... )
LEAD语法:LEAD(<expression>[,offset[, default_value]]) OVER ( PARTITION BY (expr) ORDER BY (expr))
expression:LEAD()函数返回的值expression从offset-th有序分区排。
offset:offset是从当前行向前行的行数,以获取值。offset必须是一个非负整数。如果offset为零,则LEAD()函数计算expression当前行的值。如果省略 offset,则LEAD()函数默认使用一个。
default_value:如果没有后续行,则LEAD()函数返回default_value。例如,如果offset是1,则最后一行的返回值为default_value。如果您未指定default_value,则函数返回 NULL 。
PARTITION BY子句:PARTITION BY子句将结果集中的行划分LEAD()为应用函数的分区。如果PARTITION BY未指定子句,则结果集中的所有行都将被视为单个分区。
ORDER BY子句:ORDER BY子句确定LEAD()应用函数之前分区中行的顺序。
例1:
排序函数:
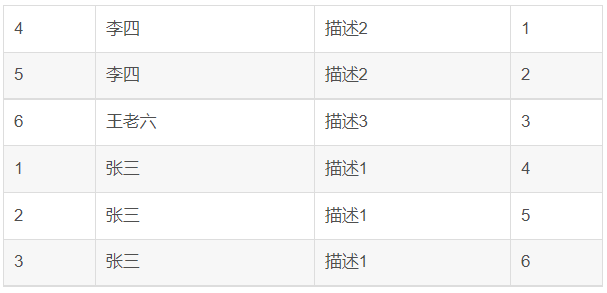
ROW_Number记录行号,可用于分页等情况
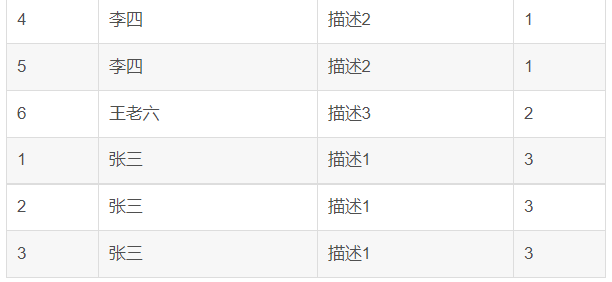
DENSE_RANKdense_rank函数出现相同排序时、排序号一致;dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续
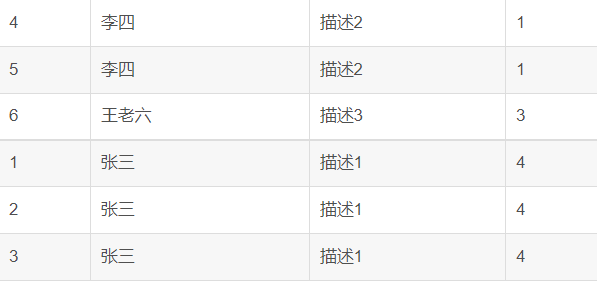
RANKrank函数出现相同排序时,排序号一致,rank函数生成的序号有可能不连续

















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









