







前言
在上一章【课程总结】day25:大模型应用之Prompt的初步了解的学习中,我们了解了大模型上层开发中Prompt的基本流程。本章,我们将对Prompt进行扩展学习,包括:piplineprompt、MessagePlaceholder消息占位符、CommaSeparatedListOutputParser输出解析器、DatetimeOutputParser日期输出解析器、EnumOutputParser枚举输出解析器、StructuredOutputParser结构化输出解析器、PydanticOutputParserPydantic输出解析器等。
LangChain框架构成
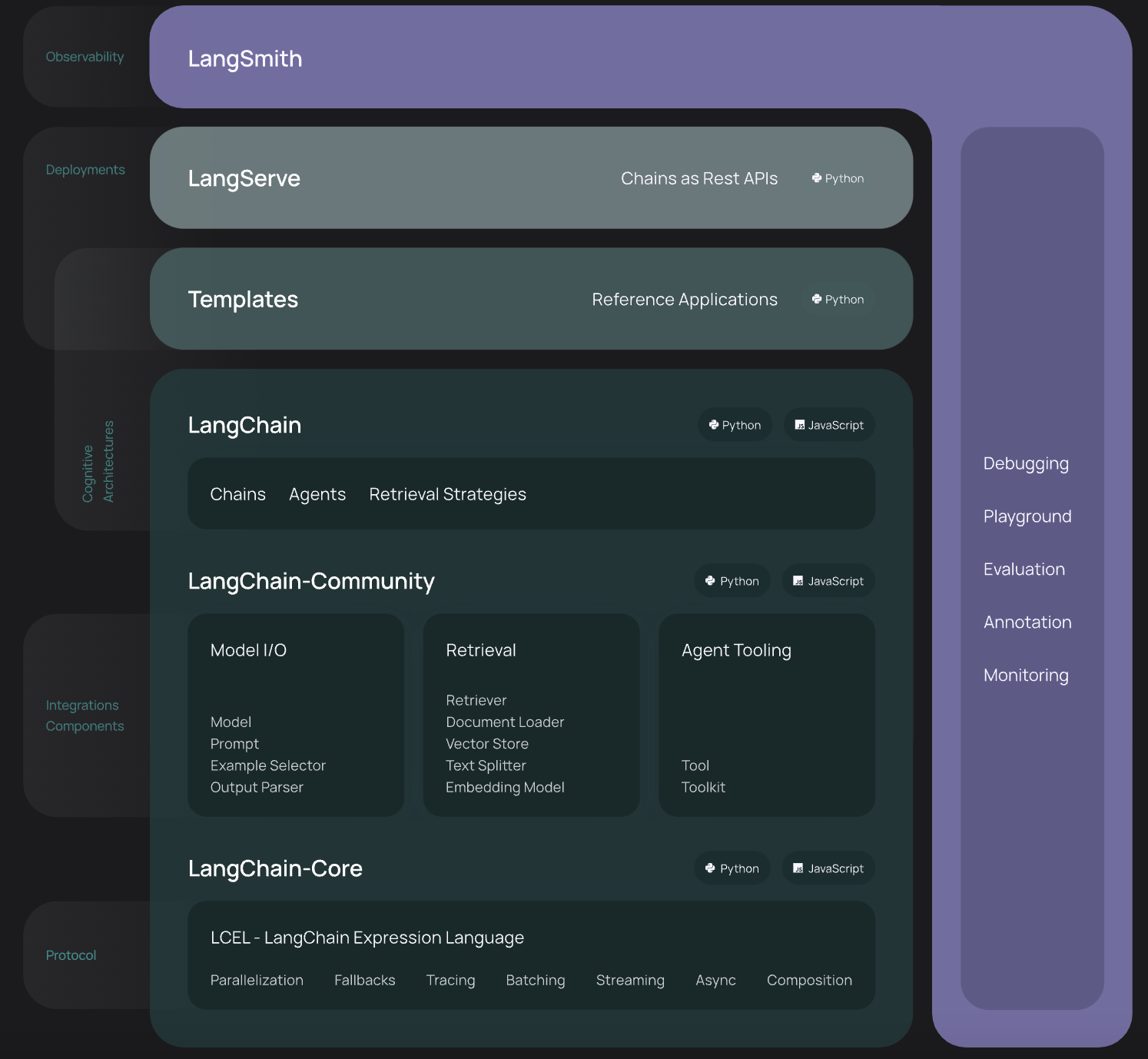
LangChain的架构图一直在更新,上述为 v1.0 的架构图
地址:https://python.langchain.com/v0.1/docs/get_started/introduction/
LangChain 的整体架构主要由以下几个组件构成:LangSmith、LangServe、Templates、LangChain-Community 和 LangChain-Core。
-
LangChain-Core
简介:LangChain-Core是LangChain的核心库,提供了基本的功能和模块,支持构建和管理链式应用程序。
组件:包括用于处理文本、数据、模型调用等的基本工具和接口。
作用:通过LangChain-Core,开发者可以轻松集成不同的语言模型以创建对话系统。 -
LangChain-Community
简介:LangChain-Community是一个社区驱动的部分,包含来自开发者和用户的贡献和扩展。
组件:包含来自开发者和用户的社区贡献模块、插件库、讨论论坛等一套生态系统。
作用:通过使用LangChain-community中的 插件库(例如:Tongyi),可以快速连接对应的大模型(例如:阿里的通义千问大模型)。 -
Templates
简介:Templates提供了一系列预定义的模板和示例,帮助开发者快速构建常见的应用场景。
组件:示例模板库、用例指南、快速启动工具。
作用:通过使用Templates,开发者可以轻松创建FAQ系统,而无需从头开始编写代码。 -
LangServe
简介:LangServe是一个服务框架,用于将LangChain应用部署为可访问的 API。
组件:API 构建工具、部署管理模块、请求处理接口。
用途:通过使用LangServe,用户可以将聊天机器人应用快速部署为可访问的 API,方便其他系统集成。 -
LangSmith
功能:LangSmith是一个工具,旨在帮助开发者在构建和调试LangChain应用时进行更好的管理和监控。
组件:可视化监控界面、调试工具、性能分析仪。
功能:通过使用LangSmith,开发者可以实时监控应用的运行状态,快速识别并解决问题。
LangChain 的整体架构可以视为一个模块化的系统,各个组件相互协作,形成了一个强大的链式应用开发平台。通过 LangChain-Core 提供的基础功能,结合 LangSmith 的管理工具、LangServe 的部署能力、Templates 的快速开发支持以及 LangChain-Community 的丰富资源,开发者能够高效地构建和发布基于语言模型的应用。
在LangChain的官网,可以找到对应API文档连接,其中详细介绍了各个模块的API使用说明。
地址:https://api.python.langchain.com/en/latest/langchain_api_reference.html
LangChain-Community
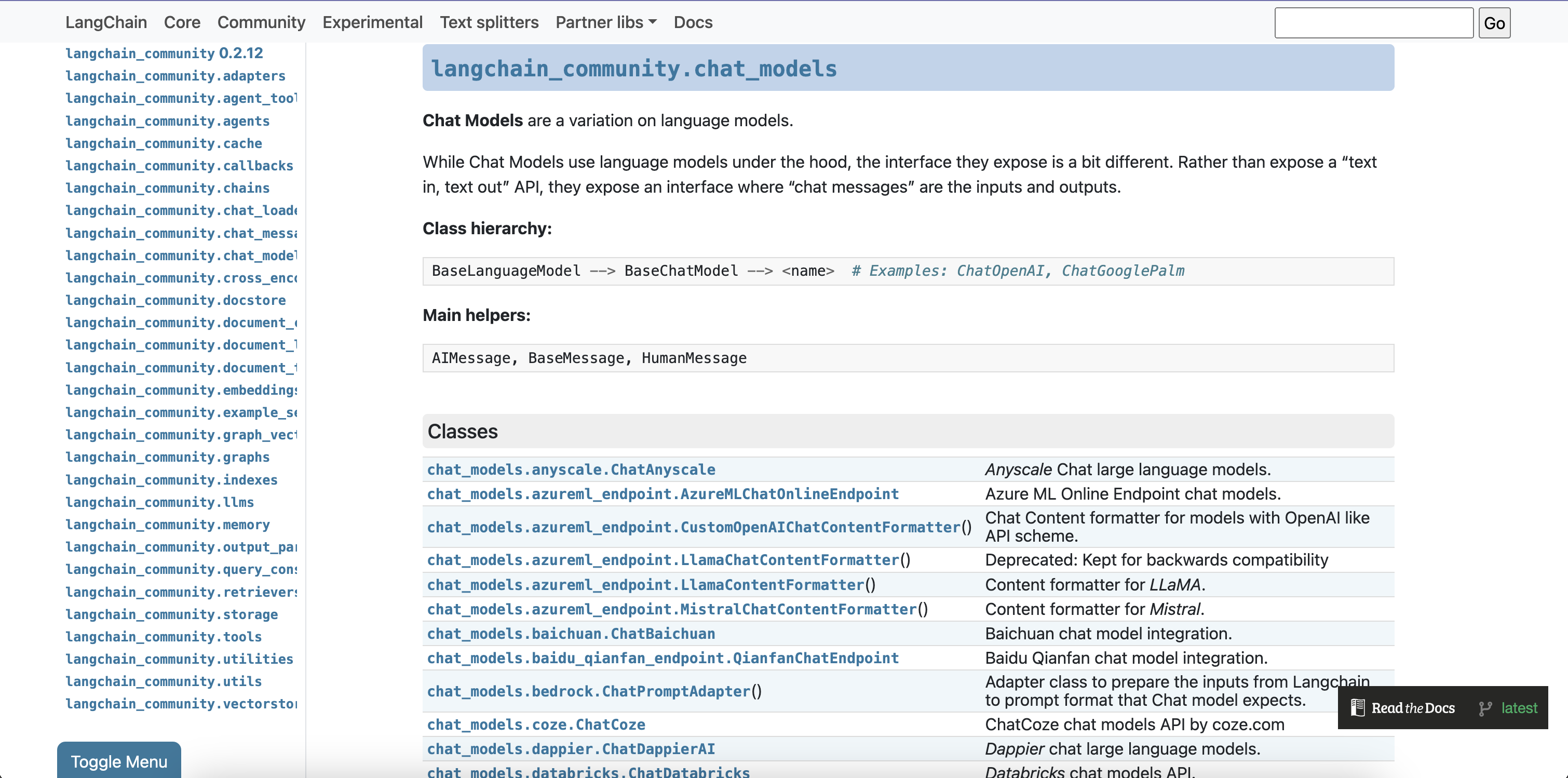
在LangChain-Community中,提供了大量的第三方大模型连接方法,例如:
chat_models.azureml_endpoint.CustomOpenAIChatContentFormatter:OpenAI API 格式化器,用于处理与 OpenAI 类似的聊天模型内容。chat_models.baichuan.ChatBaichuan:百川大模型的整合包,可以连接百川大模型。chat_models.baidu_qianfan_endpoint.QianfanChatEndpoint:百度 Qianfan 聊天模型的整合包,可以接入百度的聊天服务。chat_models.google_palm.ChatGooglePalm:Google PaLM 聊天模型的 API,可以访问 Google 提供的聊天服务。chat_models.hunyuan.ChatHunyuan:腾讯 Hunyuan 聊天模型的 API,可以接入腾讯的聊天服务。chat_models.ollama.ChatOllama:Ollama 本地运行的大语言模型,可以在本地进行聊天。chat_models.pai_eas_endpoint.PaiEasChatEndpoint:阿里云 PAI-EAS 聊天模型的 API,可以接入阿里云的聊天服务。chat_models.tongyi.ChatTongyi:阿里巴巴 Tongyi Qwen 聊天模型的整合包,可以接入阿里巴巴的聊天服务。
务。chat_models.zhipuai.ChatZhipuAI:ZhipuAI 聊天模型的整合包,可以接入 ZhipuAI 提供的聊天服务。
连接第三方大模型
在【课程总结】day25:大模型应用之Prompt的初步了解,我们已尝试连接过阿里云的通义千问大模型。本次,我们尝试连接百度的文心一言大模型。
第一步:访问百度千帆大模型官网注册/登录账号,
第二步:在应用接入->创建应用->输入应用名称和应用描述->点击创建应用

第三步:在计费管理->选择开通付费->完成个人认证->开通免费服务(千帆有一些服务是免费的,试用期间可以选择这些免费服务)
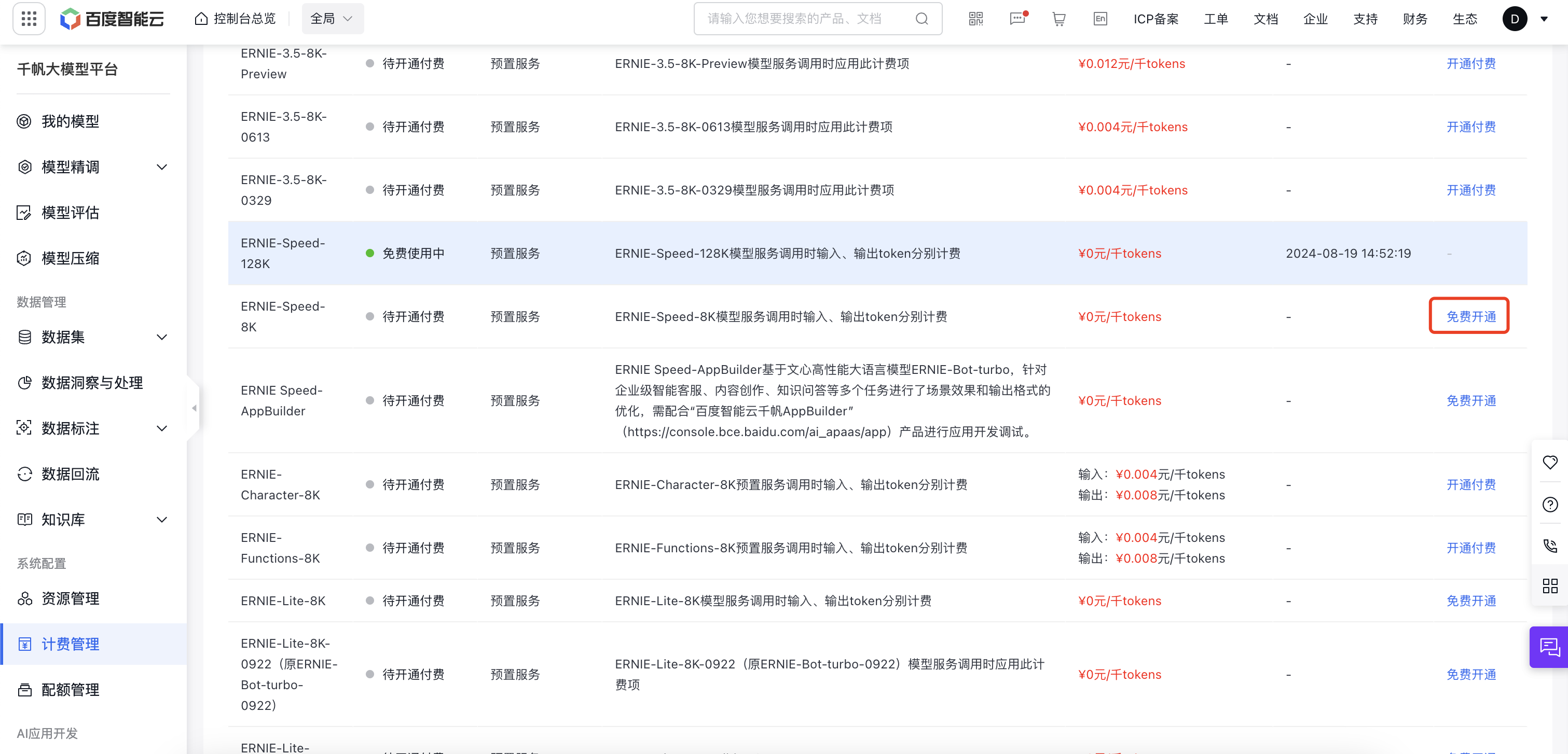
第四步:复制应用的API KEY 和 Secret KEY内容,保存到文件.ernie中,文件格式为:
QIANFAN_AK="zbxxxx"
QIANFAN_SK="cSRxxxx"
关于API KEY的格式,在Baidu Qianfa API文档中有说明。
第五步:安装qianfan组件
pip install qianfan
第六步:实现聊天模型的代码
from dotenv import load_dotenv
# LLM 大语言模型(单轮对话版)
from langchain_community.llms import QianfanLLMEndpoint
# Chat 聊天版大模型(支持多轮对话)
from langchain_community.chat_models import QianfanChatEndpoint
# Embeddings 嵌入模型
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
# 加载千帆大模型的APK-KEY
load_dotenv(dotenv_path=".ernie")
# 连接大模型
llm = QianfanLLMEndpoint(model="ERNIE-Bot-turbo",
temperature=0.1,
top_p=0.2)
chat = QianfanChatEndpoint(model='ERNIE-Lite-8K', top_p=0.2, temperature=0.1)
embed = QianfanEmbeddingsEndpoint(model='bge-large-zh')
llm.invoke("你是谁?")
chat.invoke("你是谁?")
result = embed.embed_query("你好")
注意:
- 如果导入langchain_community失败,请记得
pip install langchain-community。- 如果连接失败提示error code: 17,请检查对应model id在计费管理中是否已开通服务。
至此,使用LangChain-Community连接百度千帆大模型已成功连接。接下来,我们熟悉LangChain的另外一个模块LangChain-Core。
LangChain-Core
Prompt基础用法回顾
在【课程总结】day25:大模型应用之Prompt的初步了解中,我们以及了解Prompt的基础使用用法:
# 连接模型
chat = ChatTongyi(model='qwen-plus',
top_p=0.9,
temperature=0.9)
# 构建Prompt模板
sys_msg = SystemMessagePromptTemplate.from_template(template="这是一个创意文案生成专家。")
user_msg = HumanMessagePromptTemplate.from_template(template="""
用户将输入几个产品的关键字,请根据关键词生成一段适合老年市场的文案,要求:成熟,稳重,符合老年市场的风格。
用户输入为:{ad_words}。
营销文案为:
""")
messages = [sys_msg, user_msg]
prompt = ChatPromptTemplate.from_messages(messages=messages)
# 使用管道符 | 连接多个模型,构建chain链
chain = prompt | chat | StrOutputParser()
chain.invoke(input={
"ad_words": "助听器,清晰,方便,便宜,聆听世界。"})
- 第一步:创建
SystemMessagePromptTemplate的内容,例如:“这是一个创意文案生成专家。” - 第二步:创建
HumanMessagePromptTemplate的内容,例如:“用户将输入几个产品的关键字,请根据关键词生成一段适合老年市场的文案,要求:成熟,稳重,符合老年市场的风格。” - 第三步:使用
ChatPromptTemplate将系统消息和用户消息进行拼接,得到最终的P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2355
2355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











