




前言
在上一篇课程《【课程总结】Day7:深度学习概述》中,我们了解到:
- 模型训练过程→本质上是固定w和b参数的过程;
- 让模型更好→本质上就是让模型的损失值loss变小;
- 让loss变小→本质上就是求loss函数的最小值;
本篇文章,我们将继续深入了解深度学习的项目流程,包括:批量化打包数据、模型定义、损失函数、优化器以及训练模型等内容。
求函数最小值回顾
以 y = 2 x 2 y=2x^2 y=2x2,我们回顾使用pytorch框架求函数最小值,其过程大致如下:
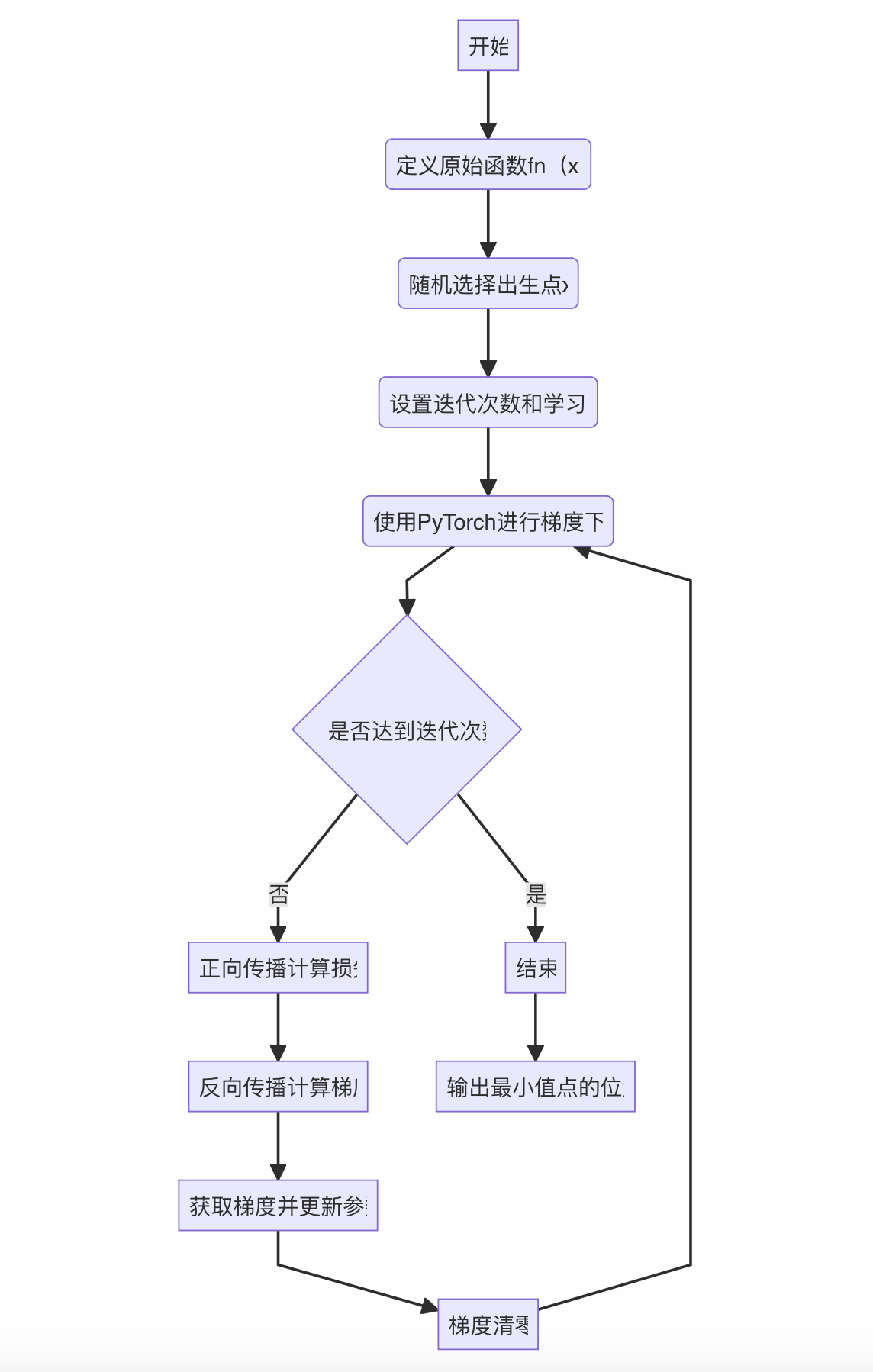
备注:代码不再重复赘述,回顾代码请见使用pytorch求函数最小值
深度学习基本流程
由于训练的本质:求loss函数的最小值;所以,我们类比求 y = 2 x 2 y=2x^2 y=2x2最小值的过程,来看一下线性回归训练(也就是求loss最小值)的过程,其流程如下:
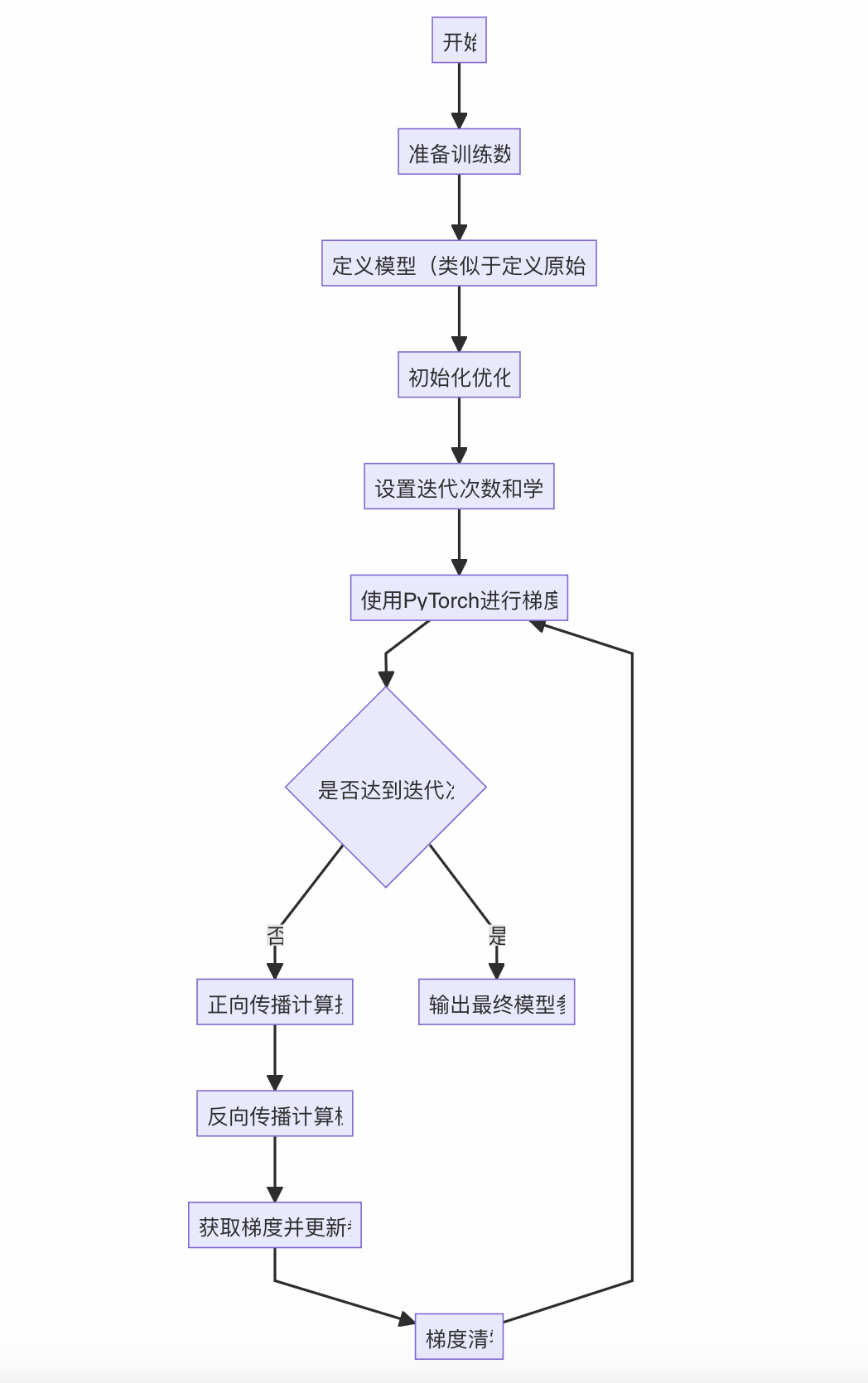
相比于求 y = 2 x 2 y=2x^2 y=2x2最小值的过程,我们有如下调整:
- 替换:随机选择出生点→准备训练数据(本例中训练数据先模拟生成)
- 替换:定义原始函数→定义模型
- 增加:初始化优化器(训练时要定义损失函数,我们常用MSE)
- 替换:输出最小值位置→输出训练后的模型权重和偏置
具体代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
# 生成模拟数据
torch.manual_seed(42)
x_train = torch.randn(100, 13) # 100个样本,每个样本有13个特征
y_train = torch.randn(100, 1) # 每个样本对应一个输出值
# 定义模型
model = nn.Linear(13, 1) # 输入特征数为13,输出特征数为1
# 初始化优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器
# 迭代次数和学习率
epochs = 1000
learning_rate = 1e-2
# 使用 PyTorch 进行梯度下降
for _ in range(epochs):
optimizer.zero_grad() # 梯度清零
outputs = model(x_train) # 正向传播
loss = criterion(outputs, y_train) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 输出最终模型参数
print("线性回归模型的权重:", model.weight)
print("线性回归模型的偏置:", model.bias)
运行结果:

至此,我们完成了线性回归模型的训练。接下来,我们参照上面代码,再深入理解一下相关的基础理论。
模型 model
-
前向传播的定义:把特征 X 带入模型 model ,得到预测结果 y_pred
-
训练时:自动在底层构建计算图(把正向传播的流程记录下来,方便进行后续的分布求导/链式求导。
例如:在导数中,对于一个复合函数h( g( f(x))),我们需要进行链式求导,即h( g( f(x))) = f’ * g’ * h’
-
推理时:直接调用正向传播即可,不需要构建计算图
-
-
反向传播的定义:本质是计算每个参数的梯度,是通过损失函数发起的
-
模型的作用:只负责前向传播 forward,不负责后向传播 backward
训练流程
- 从训练集中,取一批
batch样本(x, y) - 把样本特征
X送入模型model,得到预测结果y_pred - 计算损失函数
loss = f(y_pred, y),计算当前的误差loss - 通过
loss, 反向传播,计算每个参数(w, b)的梯度 - 利用优化器
optimizer,通过梯度下降法,更新参数 - 利用优化器
optimizer清空参数的梯度 - 重复
1-6直至迭代结束(各项指标满足要求或是误差很小)
预测流程
- 拿到待测样本
X(推理时,没有标签,只有特征) - 把样本特征
X送入模型model,得到预测结果y_pred - 根据
y_pred解析并返回预测结果即可
深度学习项目流程
通过上述内容梳理,我们已经了解深度学习的一个基本流程,包括:定义模型、训练、预测。
但是在实际工程使用中,由于训练数据比较庞大,所以我们还需要一些额外的步骤,例如:增加批量化打包流程。
为了更好地理解深度学习的整体流程,我们仍然使用机器学习中使用的《波士顿房价预测》案例,来看一下深度学习下应该如何实现。
批量化打包数据
背景
在实际的工程中,由于深度学习是要进行大数据量的训练,所以我们需要基于以下原因进行批量化打包数据。
- 提高训练效率:通过批量化处理数据,可以充分利用GPU的并行计算能力,加快模型训练速度。
- 稳定模型训练:批量化处理可以降低训练过程中的方差,使模型更加稳定。
- 减少内存消耗:批量化处理可以减少在每个迭代中需要存储的数据量,节省内存消耗。
原理
-
使用生成器来打包数据
生成器记录了一个规则,每次调用生成器就会返回一个批次数据。
实现
- 先自定义
dataset - 再定义
dataloader
from torch.utils.data import DataLoader, TensorDataset
# 批量化打包数据示例代码
# 创建数据集和数据加载器
dataset = TensorDataset(x_tensor, y_tensor)
data_loader = DataLoader(dataset, batch_size=16, shuffle=True)
构建模型
定义
在深度学习中构建模型是指设计神经网络结构,确定网络的层数、每层的神经元数量、激活函数等参数,以实现特定的学习任务。
常见方式
- Sequential模型:Sequential模型是一种简单的线性堆叠模型,层按顺序依次堆叠在一起,适用于顺序处理的神经网络结构。
- Class子类化模型:通过继承框架提供的模型基类,用户可以自定义模型的结构和计算逻辑,实现更加灵活和定制化的模型构建。
除上述方式之外,还有迁移学习、模型组合、模型集成、自动机器学习(AutoML)、**超网络(Hypernetwork)**等方式,由于不是本章内容重点,暂不展开。
筹备训练
定义损失函数
- 目的:损失函数用于衡量模型预测结果与真实标签之间的差异,是优化算法的目标函数,帮助模型学习正确的参数。
常见损失函数
- 均方误差损失(Mean Squared Error, MSE)
- 交叉熵损失(Cross Entropy Loss)
定义优化器
- 目的:优化器用于更新模型参数,通过最小化损失函数来提高模型性能,调整模型参数使得损失函数达到最小值。
常见优化算法
- 随机梯度下降(SGD)
- Adam
- Adagrad等
定义训练次数(Epochs)
-
定义:训练次数指的是将整个训练数据集在模型上反复训练的次数,每次完整地遍历整个数据集称为一个训练周期(Epoch)。
-
作用:通过增加训练次数,模型可以更好地学习数据集中的模式和特征,提高模型的泛化能力,减少过拟合的风险。
定义学习率(Learning Rate)
- 定义:学习率是优化算法中的一个重要超参数,控制模型参数在每次迭代中更新的步长大小,即参数沿着梯度方向更新的幅度。
- 目的:学习率的选择影响模型训练的速度和性能,合适的学习率能够使模型更快地收敛到最优解,而过大或过小的学习率可能导致训练不稳定或陷入局部最优解。
训练模型
-
训练过程中需要监控模型指标,如:准确率、损失值等
-
训练过程中需要保存模型参数,方便后续推理
-
避免过拟合
推理模型
训练好模型之后,直接使用模型进行推理即可。
回归问题:深度学习实现房价预测案例
1. 数据预处理
1.1 数据读取
file_name = './housing.data'
# 原始数据读取
X = []
y = []
with open(file=file_name, mode='r', encoding='utf8') as f:
# f.readline()
for line in f:
line = line.strip()
if line:
sample = [float(ele) for ele in line.split(" ") if ele]
X.append(sample[:-1])
y.append(sample[-1])
1.2 数据切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=0)
1.3 数据预处理(规范化)
# 规范化
import numpy as np
# 转numpy数组
X_train = np.array(X_train)
X_test = np.array(X_test)
# 提取参数
_mean = X_train.mean(axis=0)
_std = X_train.std(axis=0) + 1e-9 # 为了避免除零,此处加上一个非常小的数
# 执行规范化处理
X_train = (X_train - _mean) / _std
X_test = (X_test - _mean) / _std
2. 批量化打包数据
通过定义一个继承Dataset的数据集类,方便数据的常见操作,如:len()、index()等。
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# 1. 继承Dataset 自定义一个数据集类
class HouseDataset(Dataset):
"""
自定义一个房价数据集
"""
def __init__(self, X, y):
"""
接受参数,定义静态属性
"""
self.X = X
self.y = y
def __len__(self):
"""
返回数据集样本的个数
"""
return len(self.X)
def __getitem__(self, idx):
"""
通过索引,读取第idx个样本
"""
x = self.X[idx]
y = self.y[idx]
# 转张量
x = torch.tensor(data=x, dtype=torch.float32)
y = torch.tensor(data=[y], dtype=torch.float32)
return x, y
此处__len__和__getitem__方法是Python的魔法方法,他们是回调(callback)函数,不需要用户自己调用而由系统调用。即:
- 告诉系统我定义的数据集在
取长度和按index取元素调用哪个方法;- 当系统触发这两种情况(
取长度<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6924
6924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











