 乘云数字参编运维智能体能力要求标准发布
乘云数字参编运维智能体能力要求标准发布




摘要:2025年7月23日,由中国通信标准化协会主办的 “2025可信云大会” 在京举行,《运维智能体(SRE AGENT)能力要求》标准正式发布,杭州乘云数字作为运维智能体及可观测领域领导者,重点参与了本次报告的编写。

2025年12月23日,由中国通信标准化协会主办、中国信通院承办的 “2025可信云大会-软件工程智能化分论坛” 在北京中关村国家自主创新示范区会议中心举行,《运维智能体(SRE AGENT)能力要求》正式发布。杭州乘云数字作为可观测性领域领导者,重点参与了本次报告的编写。该标准参与编写单位包括:中国信息通信研究院、移动云、华为云、蚂蚁、农业银行、杭州乘云数字、小米、神州灵云、农商银行、中电普华、百度、恒为科技、福建移动、宜通衡睿、银信、长三角数链。本标准文件由云计算开源产业联盟提出并归口。

01 报告介绍
随着AI技术、运维自动化能力的不断发展,基于智能体的运维能力作为一种高效、自主的新型运维工具,能够实现更智能的资源调度、自动化运维和精准的故障预测,从而降低运营成本并提高系统稳定性。
本标准规范了在开展运维智能体建设或度量时,如何指导运维场景应用、协同能力构建、智能体能力建设和基智能体底座建设。

本标准同时适用于服务商提供的运维智能体服务和运维智能体软件产品,即面向公共用户提供的运维智能体服务和私有环境下的软件产品或解决方案;依据交付形式的差异,本标准针对不同的使用场景其技术指标要求略有不同。
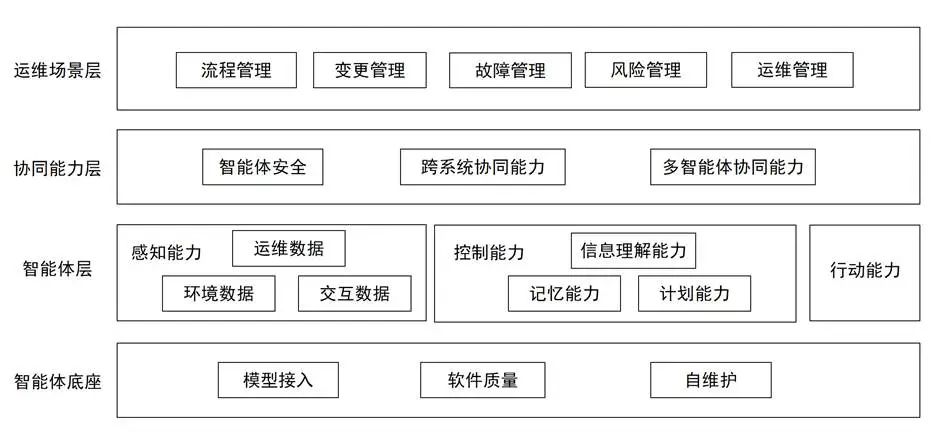
该架构以场景需求为牵引,通过协同层打通系统壁垒,以智能体层的感知-决策-行动闭环为核心能力载体,最终由底座提供工程化支撑。四层能力环环相扣,既明确了技术能力边界,又强调实际落地场景的适配性,为企业构建智能运维体系提供清晰的模块化建设路径。
1. 运维场景层(顶层)
覆盖智能体服务的核心业务场景,包含:
● 流程管理:自动化运维流程执行
● 变更管理:系统变更的智能化控制
● 故障管理:异常检测、根因定位与自愈
● 风险管理:预判性监控与容错控制
● 运维管理:资源调度与配置优化
定位:直接对接企业实际运维需求,定义智能体价值出口。
2. 协同能力层(承上启下)
支撑智能体在复杂环境中的协作能力:
● 多智能体协同:集群任务分配与联动作业
● 跨系统协同:对接CMDB、监控系统等第三方平台
● 智能体安全:数据加密、权限控制与行为审计
定位:破除系统孤岛,确保人-机-系统安全交互。
3. 智能体层(核心技术层,横向三模块)
● 感知能力:
- 运维数据(指标/日志/链路)
- 环境数据(硬件状态/网络拓扑)
- 交互数据(用户指令/反馈)
(注:多源数据融合感知)
●控制能力:
- 信息理解:数据语义解析与特征提取
- 记忆能力:知识图谱构建与经验存储
- 计划能力:任务拆解与决策路径生成
● 行动能力:
- 自动执行修复、扩缩容等物理操作
- 支持工单生成、告警通知等人机协同
4. 智能体底座(基础设施)
● 模型接入:兼容AI大模型与专业算法引擎
● 软件质量:高可用架构与性能保障
● 自维护:智能体自监控、自升级与故障隔离
作为国内首个聚焦SRE Agent的专项能力标准,该报告具有三大核心价值:
● 统一规则: 为产品开发与评估提供清晰依据,规范市场秩序。
● 赋能企业: 指导企业高效选型和建设SRE Agent能力,提升运维智能化水平。
● 引领发展: 树立行业技术标杆,加速智能运维技术成熟与应用创新。
02 篇章预览
5.3.2故障定位
描述:故障定位是指故障发生以后能够采取多种手段找到问题原因。一般故障定位能力分为现象定位、对象定位、原因定位三种。智能体应该与企业当前故障定位能力结合,在故障处理过程中通过大模型能力快速判断、整合,从而提升故障定位效率。
1级:
应具备故障现象定位能力,通过现象关联分析,实现故障初步定位及影响范围识别。
2级:
a) 智能体应具备故障对象定位能力。以及部分故障原因定位能力。
b) 智能体应具备结合多源数据进行多维度根因分析的能力。
3级:
智能体应具备精准分析故障原因与趋势,输出处置预测报告的能力
03 乘云数字运维智能体介绍
乘云数字,作为数字化可观测性领域的领军企业,持续专注于可观测性、现代AIOps、数字化经营等先进产品与技术的研究与应用,深入自主研发,聚焦解决国内企业全面上云带来的数字化运维、数字化经营的全新挑战。
凭借在领域的技术创新与行业领跑实力,乘云数字被评选为 “国家高新技术企业”、“浙江省专精特新企业”、“浙江省科技型企业”,并连续获得多轮融资。
乘云数字运维智能体引擎,结合预测性、因果关系和生成式 AI,能够实现分钟级的根因定位,利用大模型生成精准的处建建议,并可在问题对客户造成影响之前进行预测。

预测AI :融合机器学习与多模态数据分析,实时处理指标、日志、追踪等运维数据,构建动态基线,提前预警潜在故障(如资源瓶颈、性能衰退),并定位根因、提供修复建议。通过仿真推演与智能决策,优化资源规划与发布策略,降低故障率,推动运维从“被动响应”迈向“主动预防”的价值驱动模式。
因果AI :分析指标、日志、追踪等数据间的因果关系,精准定位故障根因(如配置错误、依赖故障),区分直接与间接诱因,减少误报。通过回溯故障传播路径、量化影响并推荐修复方案,助力运维从“经验猜测”转向“因果可解释”的精准决策,提升故障处理效率与系统稳定性。
生成式AI :结合大语言模型(LLM)与知识图谱,实现基于自然语言的查询分析、报告生成、数据可视化等能力。通过沉淀历史经验和专家知识,推动运维自动化与知识高效复用,提升故障处理与系统优化效率。
具体实现效果可参考阅读以下内容:

















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









