



原文地址:https://databuff.com/resourceDetail/blog102
一、从一家馒头公司说起
2020年10月12日,中饮巴比食品股份有限公司在上海证券交易所敲钟上市,作为“中国包子第一股”登陆A股主板,这就是大街小巷随处可见的巴比馒头公司。截止目前,巴比馒头全国门店达到5600家,一年卖出18亿个馒头,日均生产500万个馒头,而全国只有5个集中工厂。

小编写到这,并不是眼馋巴比公司赚了多少米,而是困惑:5个大工厂一天如何加工500万个馒头。尤其是其中一个环节如何解决 —— 洗菜。
青菜、白菜、胡萝卜、香菇、荠菜……品类繁多,规模庞大。新鲜蔬菜从田间地头到工厂,面临最大的一个难题就是清洗。蔬菜表面残留泥沙、农药,夹杂烂叶、虫卵,按照传统的老奶奶 “纯手搓洗菜法”,一天的产能可能需要5万个老奶奶,这些老奶奶的衣食住行、眼药水。。。不敢想象

如果全靠人工处理,不仅效率低下,而且难以保证每家门店的蔬菜都能达到统一的安全标准。更棘手的是,不同蔬菜的清洗方式还不一样:叶菜需要浸泡去农残,根茎类要用高压水枪冲洗,菌菇则需轻柔漂洗——手工操作根本无法应对如此复杂的标准化需求。
二、自动化洗菜流水线
带着这些疑惑,我们走进巴比馒头的中央厨房,会看到这样的场景:一筐筐蔬菜(原始数据)从田间运来,经过自动清洗机(数据清洗层)去除泥沙、烂叶和农药残留(脏数据),再由分拣流水线(转换层)按品类切分、称重、包装(结构化处理),最终变成标准化净菜(高质量数据),直供门店制作包子馅料(业务应用)。

三、“洗数据” 能不能像 “洗菜” 一样简单 ?
当前IT 团队需要面对数百万个容器或数千个微服务,而不再是数百个VM或几十个服务。云原生环境会产生大量机器数据,比传统基于 VM 的环境多 100 到 1000 倍。当日志量从GB增长到TB级,传统的手工排查(如SSH登录、grep日志)就像老奶奶洗菜一样力不从心。
因此我们在构思,在运维领域,能不能像巴比馒头的“洗菜流水线”一样,打造一套“洗数据流水线”,自动化采集、智能过滤、实时路由、可视化操作编排,让数据像清洗后的蔬菜一样“开箱即用”,支撑监控、告警、分析、可视化、巡检等核心业务场景。
在运维领域,我们将这种洗数据的技术,称之为“Telemetry Pipeline” 遥测管道技术。

四、市场在召唤 telemetry pipeline 工具,让监控真正实现统一
客户的生产现场从来不是一无所有,他们的现状可能是这样的:
-
**现场已经有大量数据。**客户的生产系统已经运行多年,产生了大量的机器数据,这些数据分散在各地。
-
**现场已经有各式样的工具。**为保障系统的运行,客户已经投入建设了不少工具,这些工具各司其职,根据相互独立的数据构建自有的场景能力。每家公司使用的工具各式各样。
-
**客户已经形成了习惯体系。**长时间的工具使用与磨合,一线人员已经形成了一套工作习惯,不希望推翻重来、打破既有的工作习惯。
-
**可观测为云而生,但不只为云服务。**可观测技术是随着云原生而来,但可观测工具在现场投产后、并不只是用来为云原生业务服务,客户希望它覆盖一切机器数据,覆盖多云、非云环境。
-
**AIOps 止步不前。**没有好的蔬菜、做不出好的包子;没有好的数据、出不了好的AIOps落地效果。

因此,市场亟需一套接纳用户现有环境、包容用户现有建设的数据清洗解决方案,这就是telemetry pipeline的诞生背景。通过telemetry pipeline 不仅仅是对用户现有运维习惯的继承与分析能力的拓展,也要出于成本考虑、不用推倒重建。
遥测数据管道是一种解决方案,提供统一且全面的机制,用于管理从数据源到目标位置的机器数据(遥测)的收集、摄取、丰富化、转换和路由
——Gartner《Hype Cycle for Monitoring and Observability, 2024》
随着可观测需求的广泛发生,可观测的市场在迫切的召唤telemetry pipeline 工具。除了传统的可观测巨头(dynatrace、datadog、splunk等等)开发了自己的pipeline工具之外,催生了一批该业务领域的创业公司与产品出现:Chronosphere(Calyptia)、Cribl、Edge Delta、Mezmo、observIQ、Onum,并获得了大量投资。

**observIQ** :较早推出Bindplane ,目标是降低数据处理成本,简化大规模管理。目前获取EdisonPartners,eLab等众多投资机构投资。
**Cribl :**2024年8月份获得了3.19亿美元的E轮融资,其年度收入突破2亿美元。Cribl为2017年成立,主要目的为提供与供应商无关的解决方案,使 IT 和安全团队能够灵活地转变数据策略,从任何来源或目的地收集、处理、路由和分析遥测数据。
**Edge Delta:**2022 年 5 月 获得获得 6300 万美元的 B 轮融资。 Edge Delta 是一家领先的可观测性平台,使用分布式流处理和联合机器学习分析和提取数据见解。
Vector: 2021年被Datadog收购。是市场知名的开源pipeline项目。
五、乘云为什么还要造一个新的telemetry pipeline轮子
5.1 常见 Pipeline 工具存在的问题
-
LogStash: 资源消耗大,自定义配置学习成本高,不易编排,只处理Log,是一份通用的日志处理工具、非运维场景专用。
-
Opentelemetry Collector:无法自定义编排,缺少灵活性,使用门槛高,主要在国外社区维护、国内缺乏维护公司。
-
Datadog Vector:产品编排存在局限性,拓扑结构固定,复杂处理流程支持有限,无可视化界面、上手难。
5.2 Datahub 能否解决上面这些问题?它的核心设计目标是什么?
基于上述的困扰,乘云要推出一款适合国人的telemetry pipeline专用工具——DataHub “数据路由器”,datahub 致力于成为可观测方案体系中的数据路由,让用数据像用水一样方便,企业通过DataHub这样的“数据流水线”,将原始信息的“泥沙俱下”,转化为决策洞察的“清流”。
-
性能优越开销小:DataHub使用Go语言技术栈开发,对资源消耗较小,即使在2核1G的资源情况下,也可以处理10000 tps的Skywalking Trace数据接入,并支持多集群多节点横向扩容,满足各种高性能场景。
-
可视化编排:DataHub提供一套容易编排的拓扑结构,并根据各种场景沉淀出不同模版,用户可以根据模版直接创建Pipeline,使用托拉拽的方式,编排流程。可以实现多流关联,合并,聚合,等复杂操作。
-
上手简单:DataHub提供多个单一功能算子,可以根据处理场景,自定义组装流程,学习成本低,使用简易。
-
**统一处理:**Datahub支持日志,指标,调用链,事件等常见数据类型,不只是单一类型的数据处理,并支持Sky walking,Opentelemetry ,Prometheus,Zipkin ,Jaeger,Fluentd等不同协议的数据源直接对接。
DataHub的技术核心在于“可视化编排+自动化处理”:用户可通过拖拉拽的界面设计数据流转路径(如从Zabbix接入指标数据,经过归一化处理后转发至DataBuff平台),系统自动完成元数据清洗、衍生指标计算、数据模型统一等操作,无需手动编写复杂脚本,大幅降低多源数据整合的技术门槛。

六、Datahub 介绍
6.1 产品功能架构:
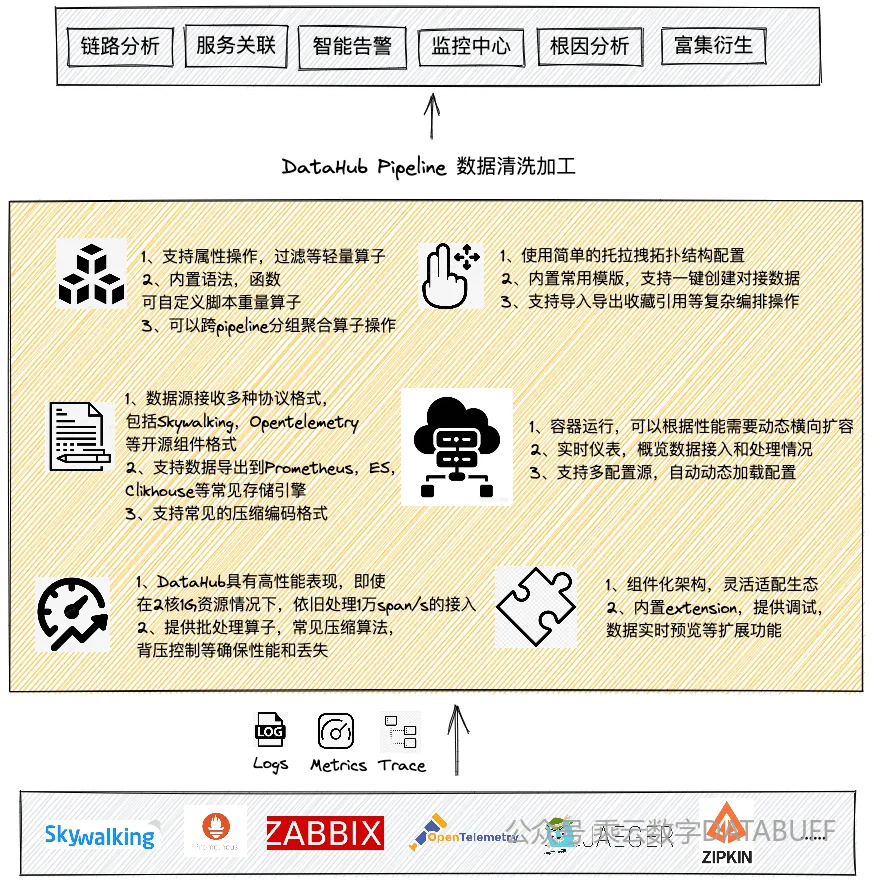
-
拓扑编排:DataHub在DataBuff平台提供了可以拖拉的拓扑编排,使用者可以轻松的构建数据处理 Pipeline,拓扑结构更加清晰的展示数据处理流向和处理细节。
-
内置模版:针对于常见的Skywalking,Opentelemetry,Zabbix等开源组件的日志、指标、调用链数据,提供内置模版,可以直接根据模版一键创建Pipeline,启动后直接对接数据。
-
功能算子:
-
提供重命名,hash,过滤,映射等轻量算子,可以自定义组合处理数据。
-
提供转换算子,根据语法和内置函数编写复杂处理流程。内置上百种函数,满足文本,数字,数组,日期等多种操作。
-
提供批处理,分组等性能算子,对于输出可以根据需要进行攒批发送操作,可以使用内置压缩算法进一步对数据进行压缩。
-
-
性能扩容:DataHub可以划分集群,每个集群下多节点运行,内置自监控,上报服务自监控指标到DataBuff平台,实时提供服务性能,处理数据,异常丢弃等指标。
-
调试和数据预览:通过Extension扩展机制,针对于Receiver提供实时数据预览,截取服务接收到的数据样例,并允许对数据和指定算子进行调试。
-
多种格式:支持Open telemetry,Prometheus,Kafka,Zipkin ,Jaeger,Fluentd等多种开源组件通过Http/GRPC 方式推送数据。对于接收和发送数据,DataHub也同时支持多种数据压缩格式(gzip,zstd,snappy,deflate等)。
6.2 技术架构:

DataHub Pipeline使用工厂模式 + 接口抽象 实现高度可扩展的架构,支持自定义组件接入,核心是 “基于接口的插件化体系”。
-
Factory:对于Pipeline中常见的Receiver,processor,Exporter有对应Factory工厂进行实例化,并对声明的Extension进行实例化。
-
**Parser:**DataHub内置语法和函数,这些语法函数使用对应的Parser builder进行构建,语法会解析成简单的语法树,函数会解析成一个代理函数对象。
-
**Graph:**根据构建好的receiver,processor 还有exporter这些组件,根据边和点的关系,使用Graph builder构建一个拓扑图,构建过程中同时会对拓扑结构是否有环进行校验。
-
**Event Notice:**事件通知,DataHub内置全局事件通知,整理管理Pipeline以及Extension的生命周期,当遇到配置变更,资源受限,服务异常等情况,会通过事件通知,合理安全的关闭Pipeline所持有的一些资源,并允许exporter发送完已经处理完成的数据。
-
**Pipeline:**处理流程运行的对象,会注册自己运行过程中产生的自监控指标给DataHub service,监听事件通知,允许Extension扩展功能,合理关闭每个processor,receiver,exporter组件。
-
Service :DataHub Service 会初始化配置加载,自监控和事件通知渠道,管理服务生命周期。Service保持高度的抽象,确保了DataHub 的高扩展性和分层解偶。
七、经典使用场景
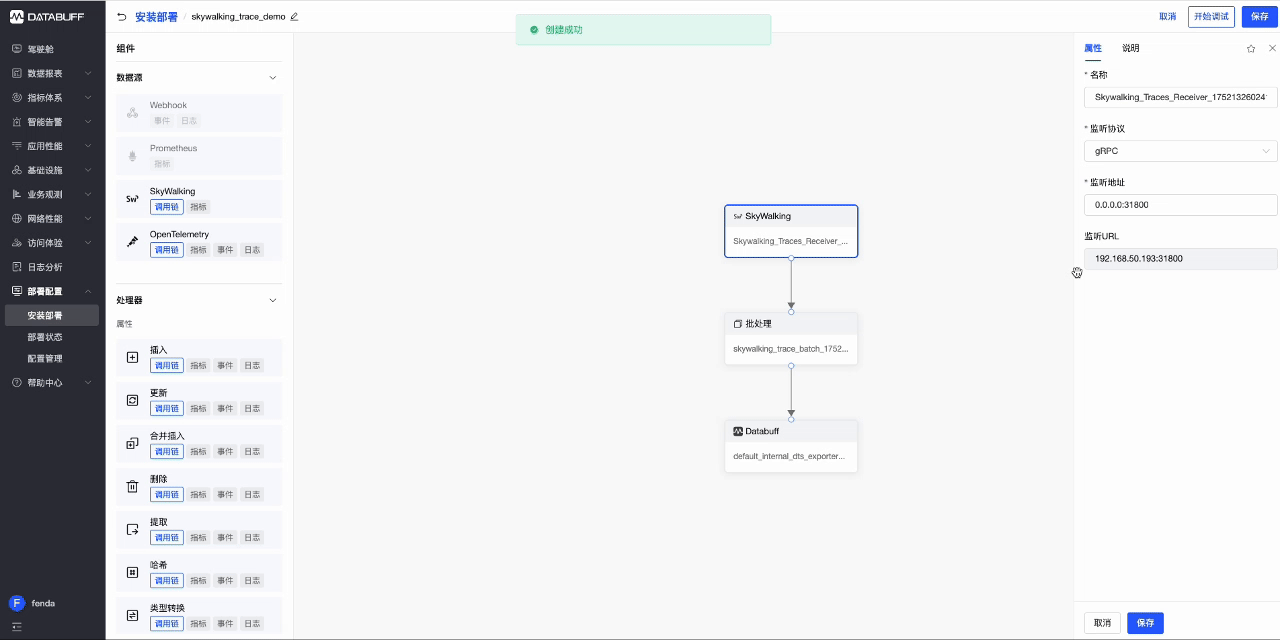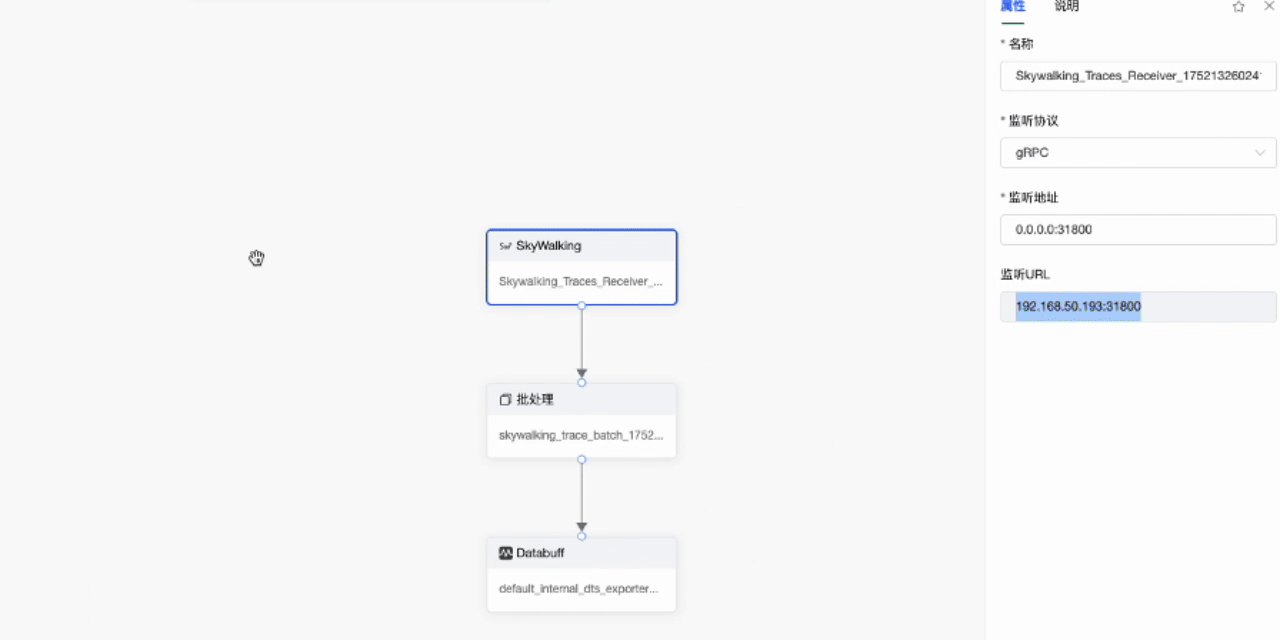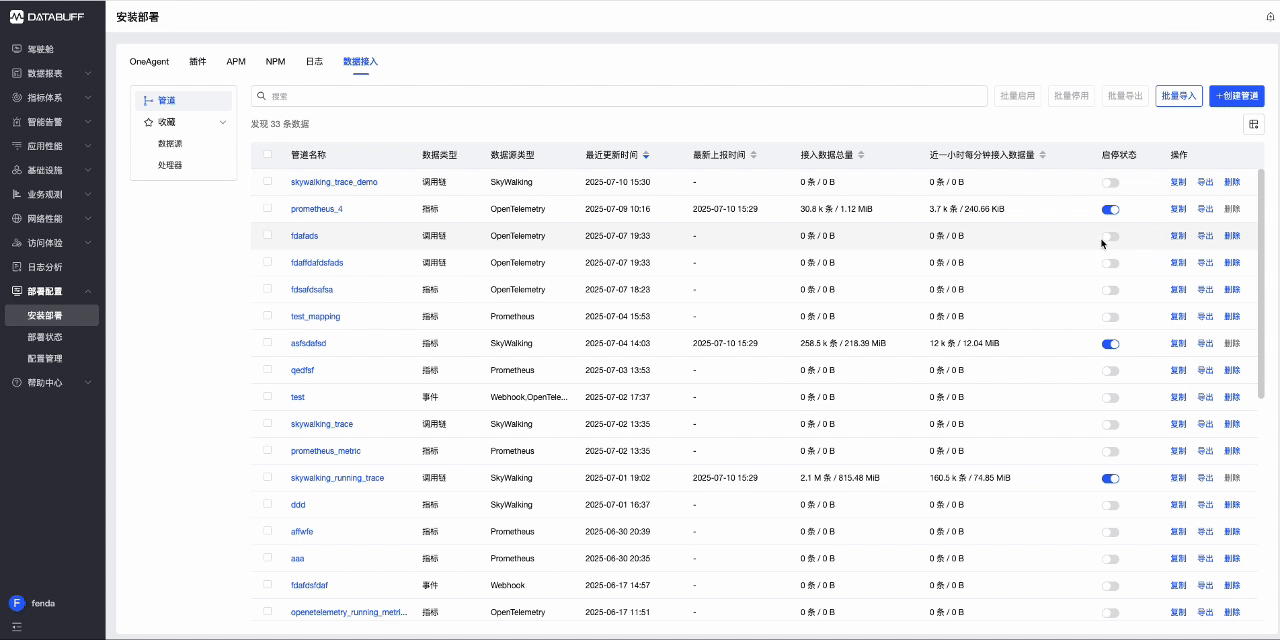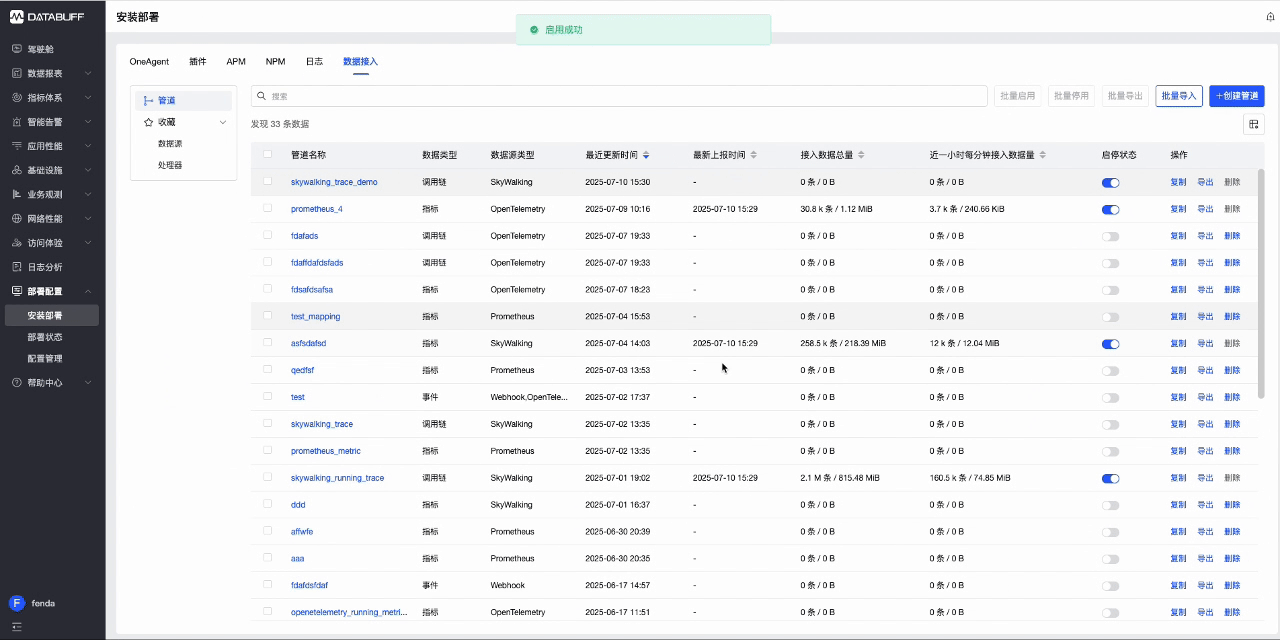
7.1 场景1:一键接入skywalking链路数据
7.1.1 数据接入
- 首先创建管道,选择要接入的数据类型-调用链,使用内置的Skywalking接入模版。
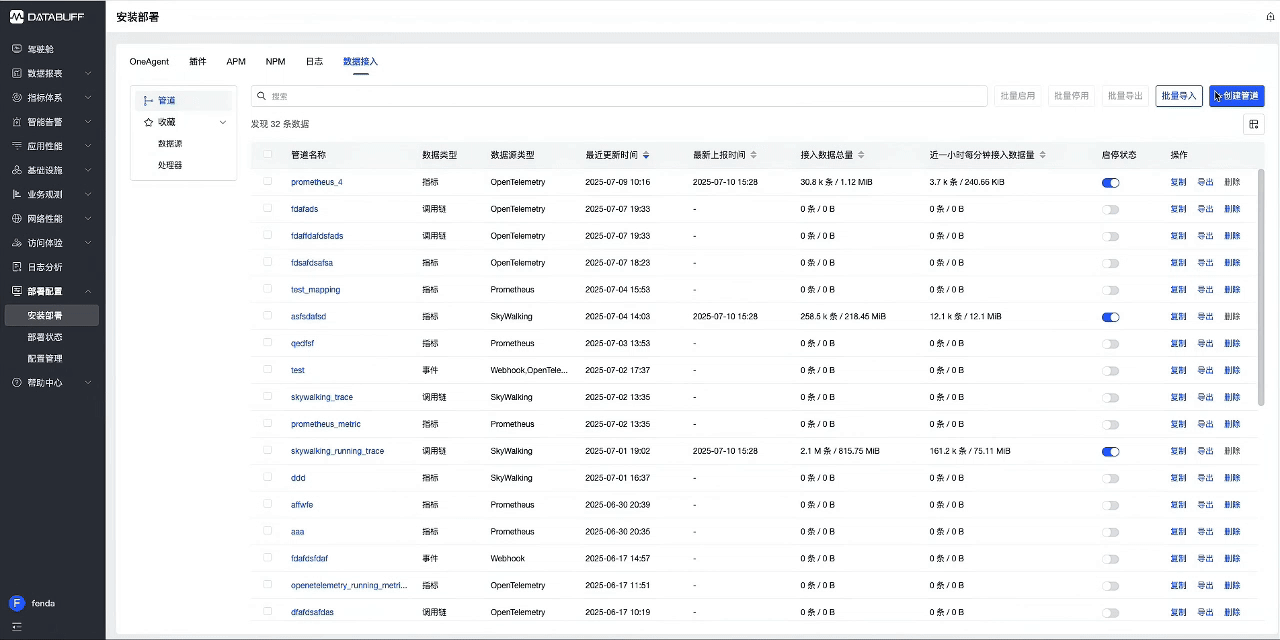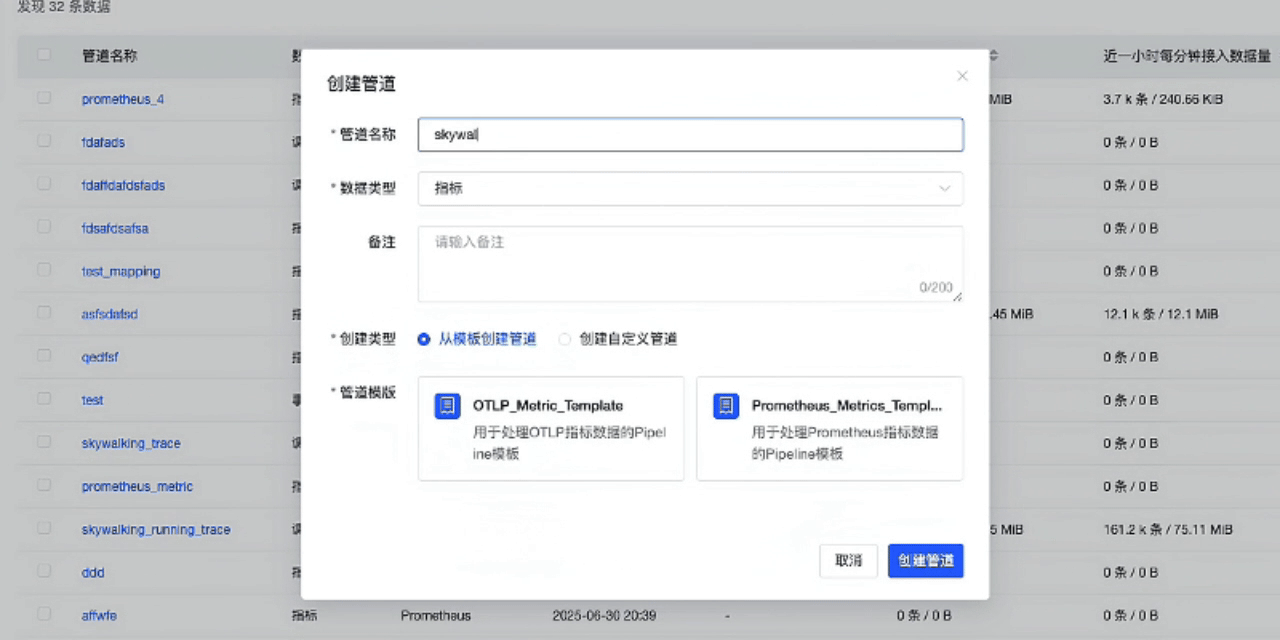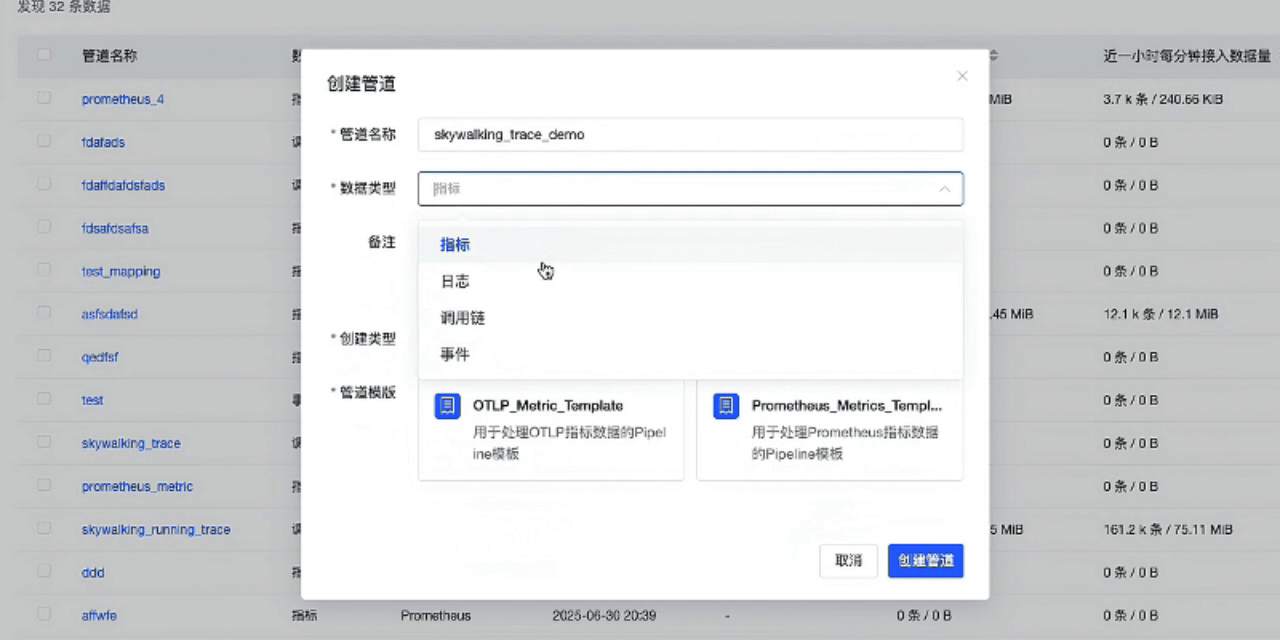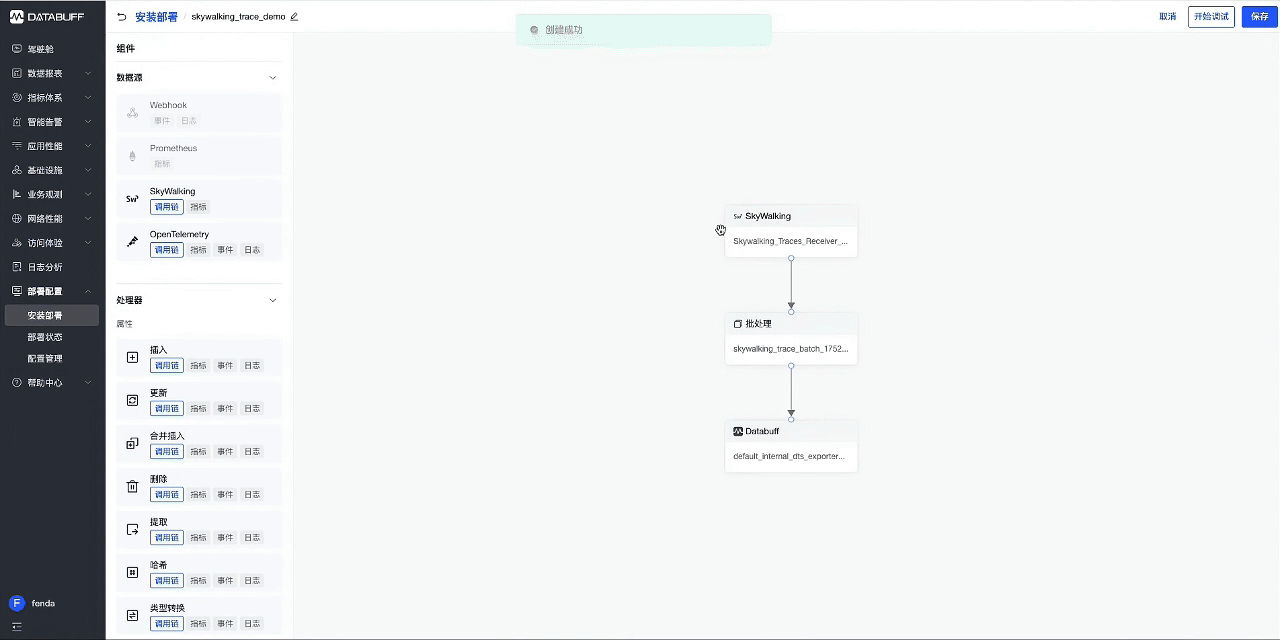
- 创建完成后,复制监听URL(该地址为SkywalkingAgent推送数据的地址),然后回到列表中启用这个管道。
- 切换到要监控的Demo服务后台命令行,使用Skywalking Agent采集Trace数据,配置SkywalkingAgent 中collector.backend_service

- 使用SkywalkingAgent采集服务链路,并命名服务名称:SKRPCCONSUMER,然后启动demo
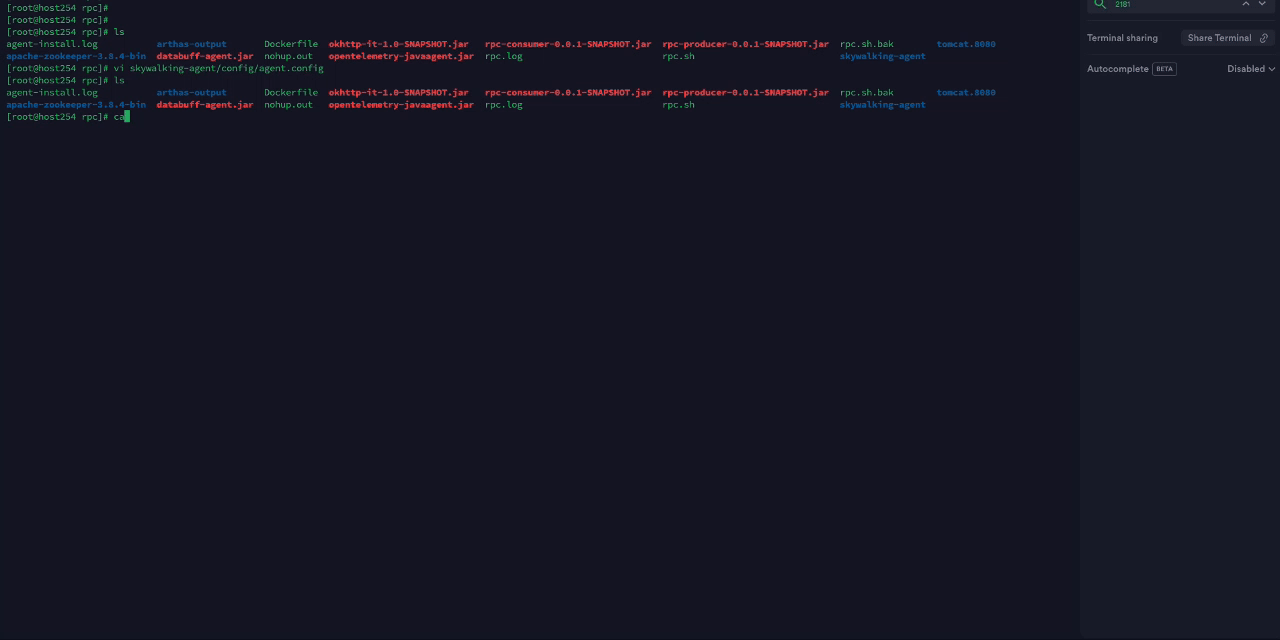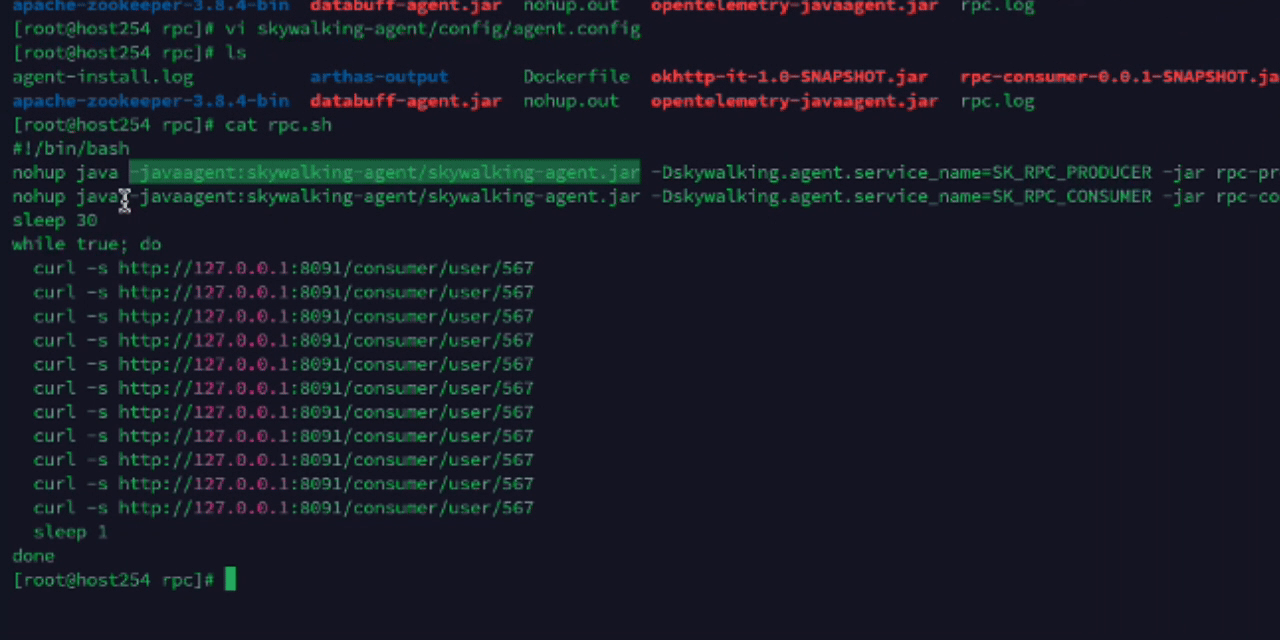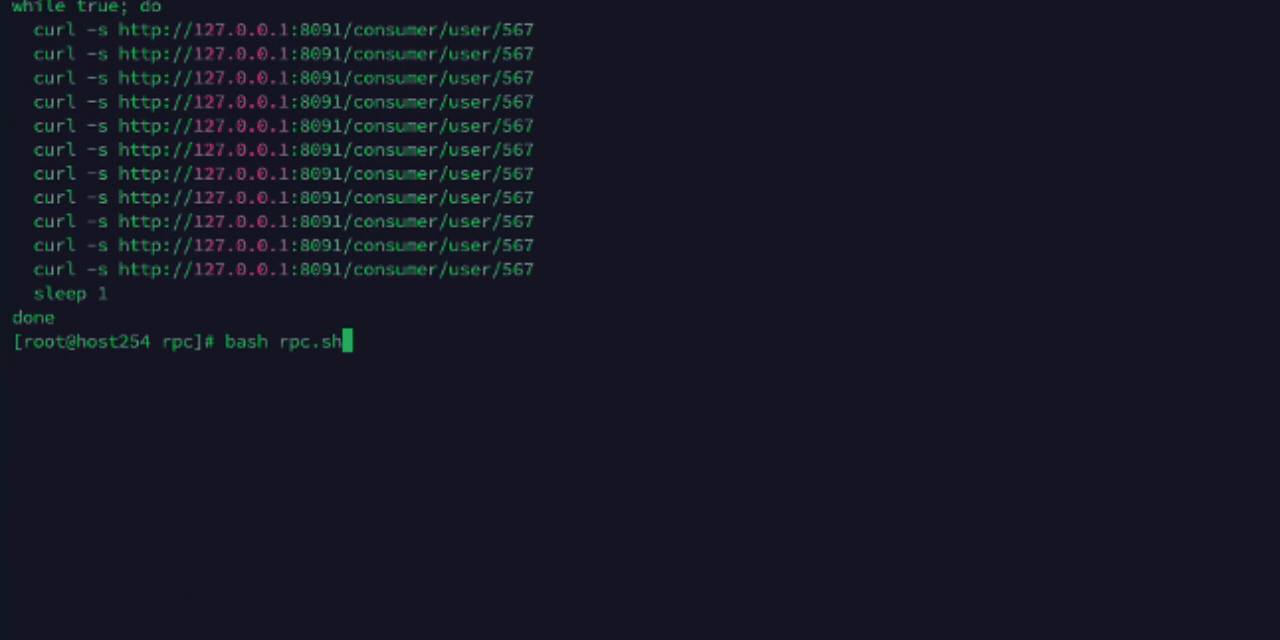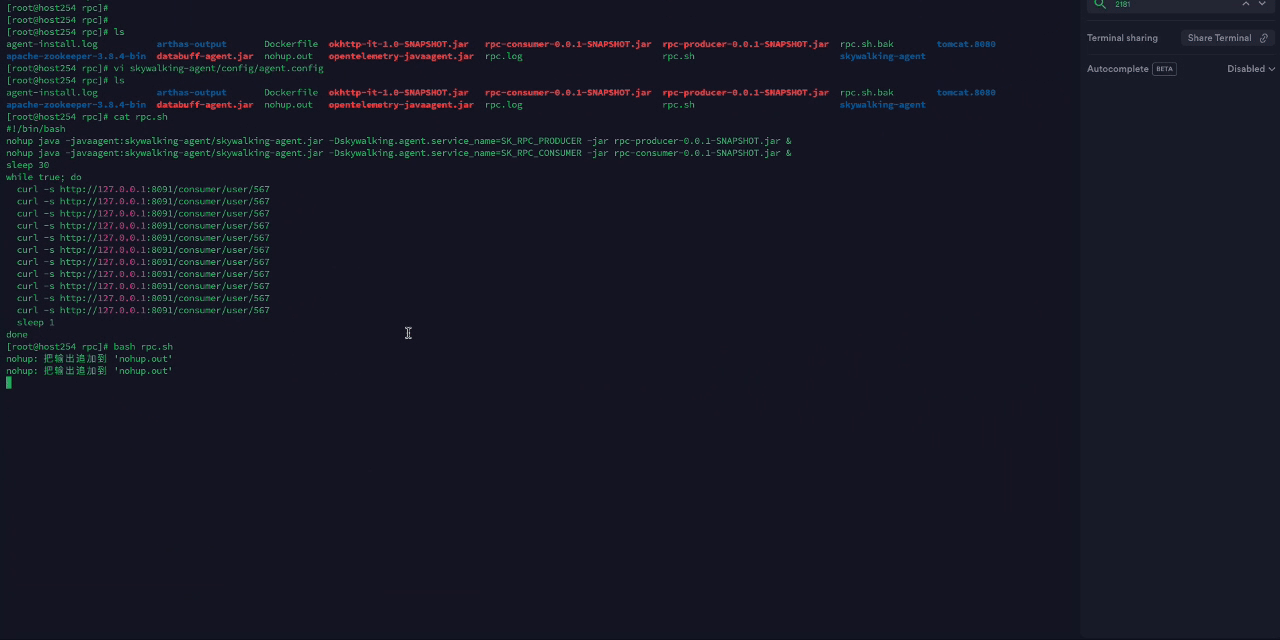
7.1.2 数据处理流程解析
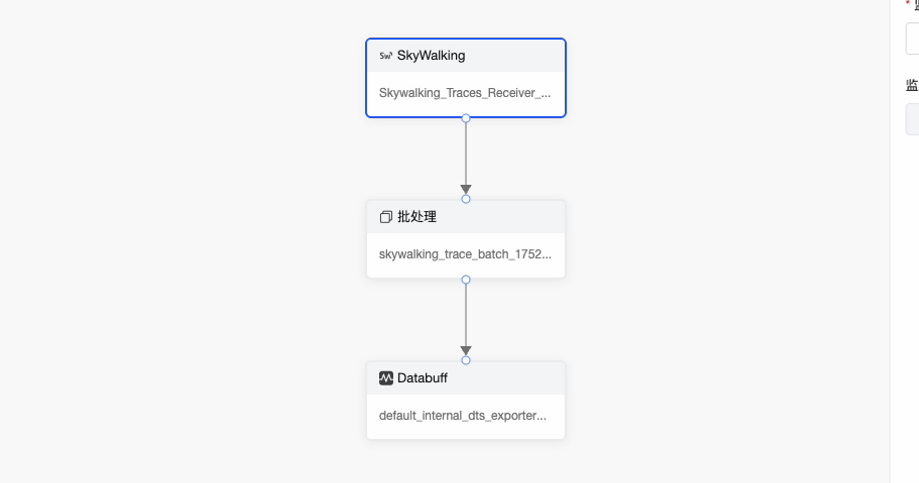
上面步骤中创建的管道使用了三个算子完成数据处理和标准化:
- 输入:Skywalking 算子
接收并解析Skywalking的Trace数据。
- 批处理 算子 //把这个处理的算子配置打开,看一下里面到底配的是什么,把配置截图贴出来解释解释 @白露(沈玉芬)\color{#0089FF}{@白露(沈玉芬)}@白露(沈玉芬)
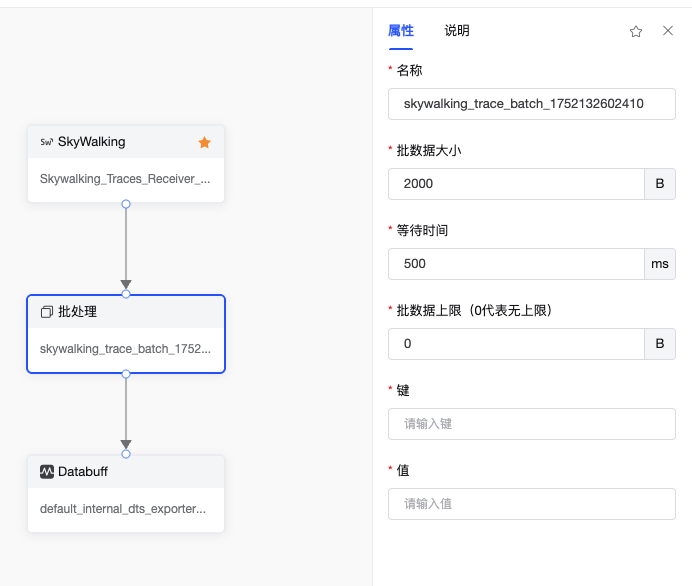
用于将传入的观测数据(跟踪、指标、日志)进行批量聚合和缓冲,减少数据处理的频率和资源消耗。其核心功能包括:
批量聚合:将单个数据项累积到指定数量或时间阈值后,以批量形式传递给下游组件(如导出器)。
缓冲控制:通过配置队列大小和超时时间,平衡内存占用与数据传输延迟。
兼容性:支持跟踪(Traces)、指标(Metrics)、日志(Logs)三种信号类型,可与任意上游接收器(如 OTLP Receiver)和下游导出器组合使用。
- 输出:DataBuff 算子
将数据统一转换为DataBuff平台数据格式(包括Trace以及Metric)
7.1.3 数据展示效果
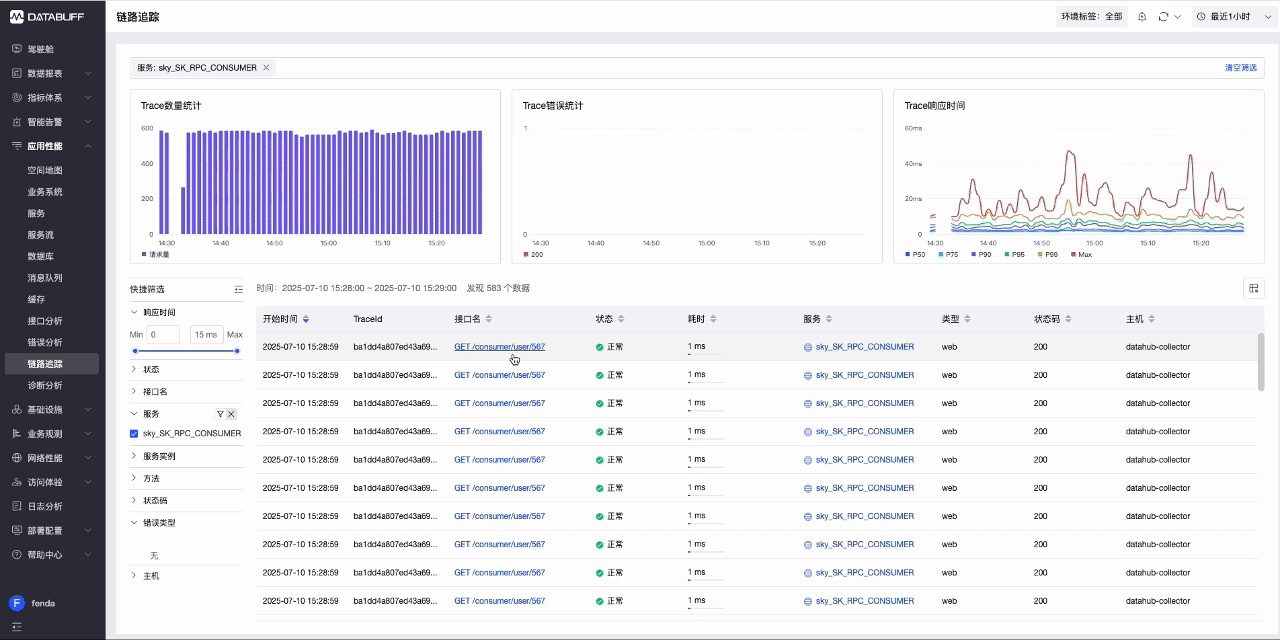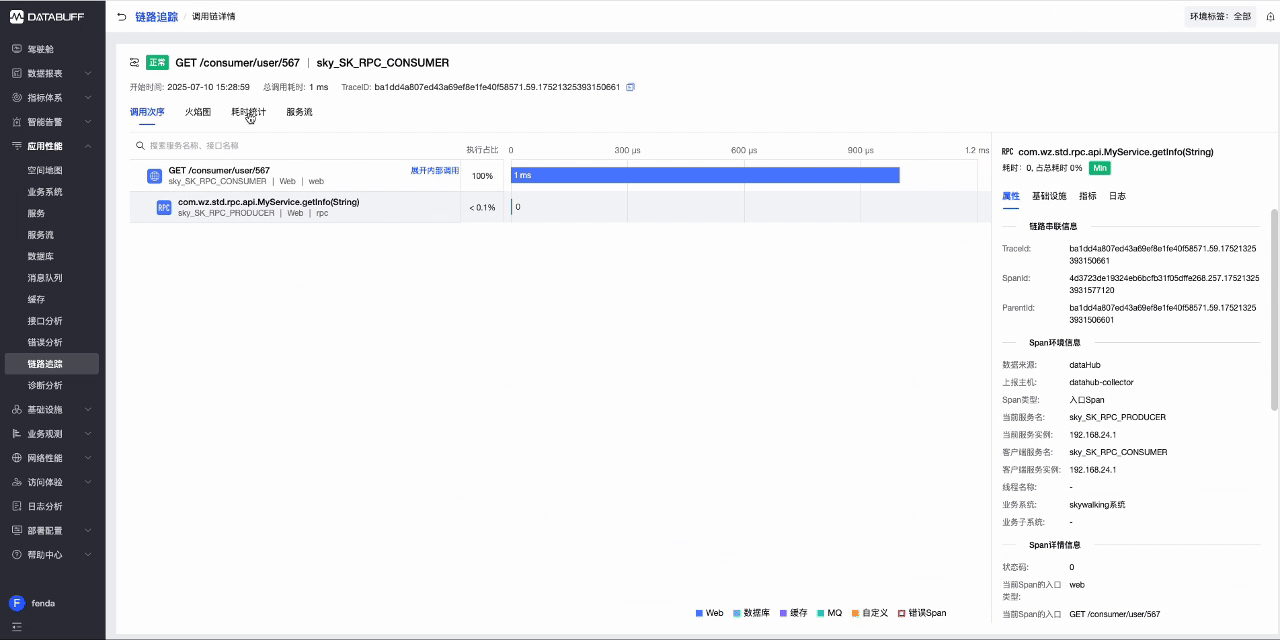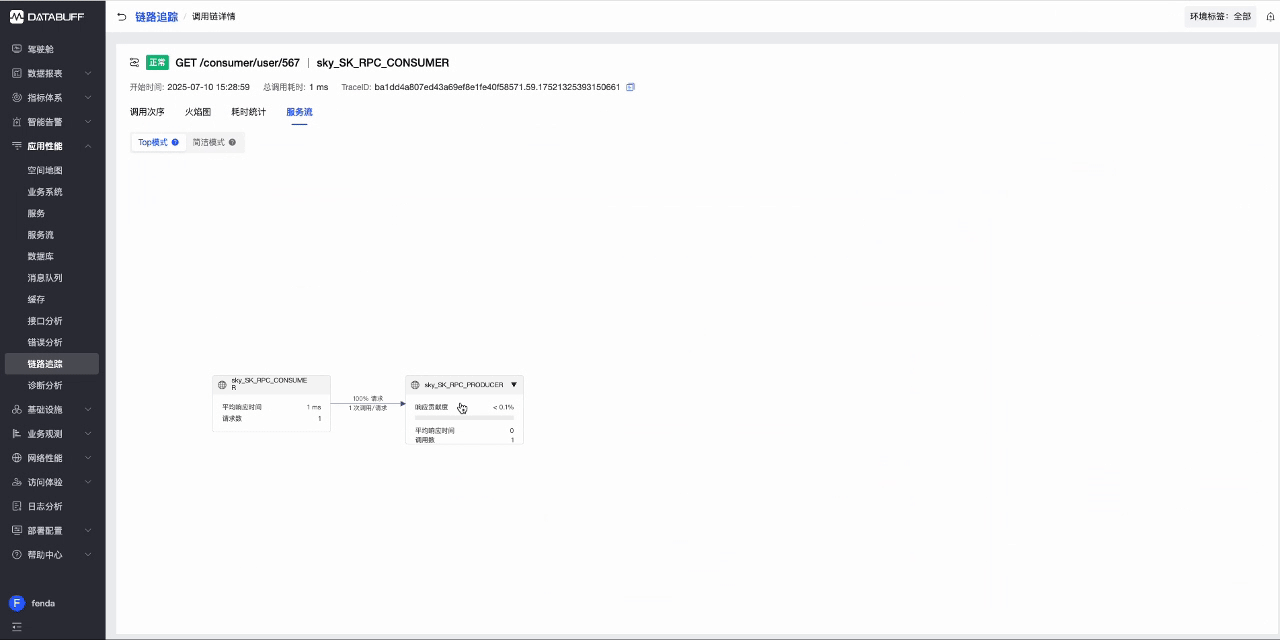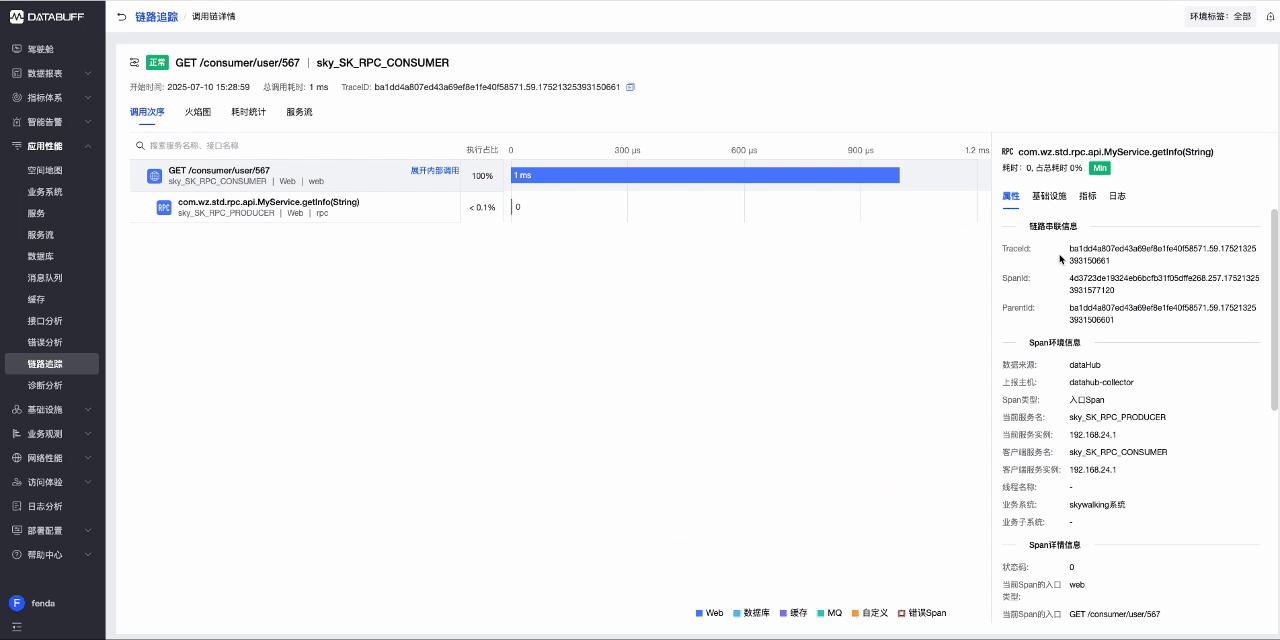
- 回到DataBuff平台,访问应用性能->链路追踪,查看上报的Trace数据
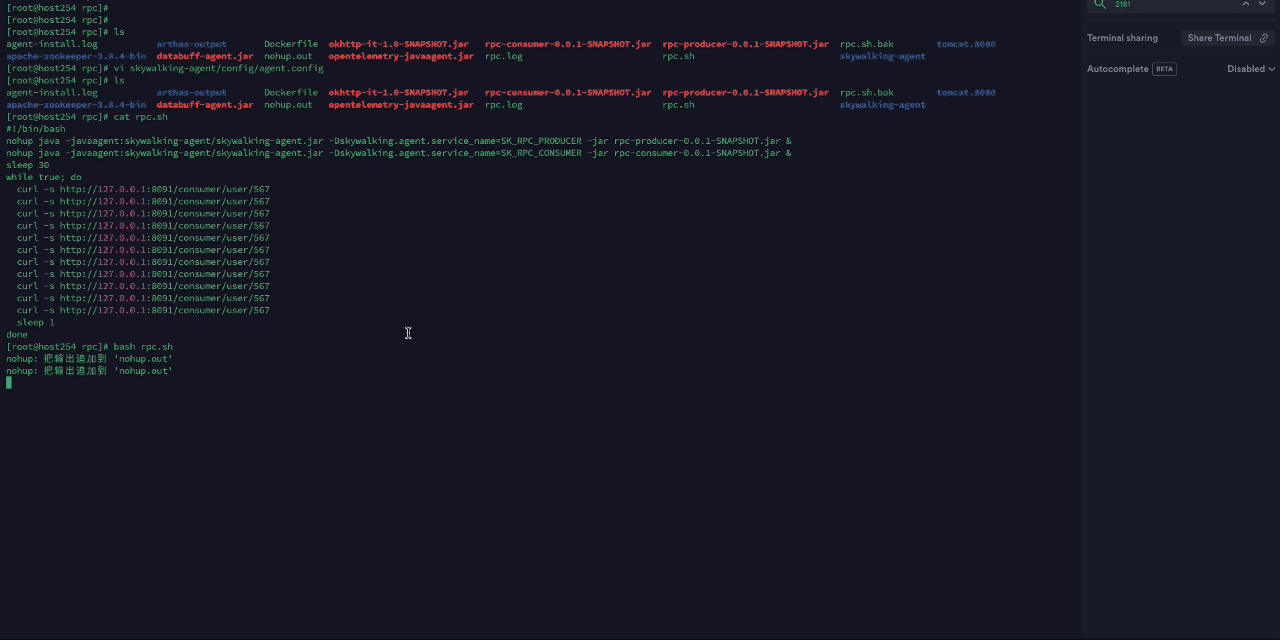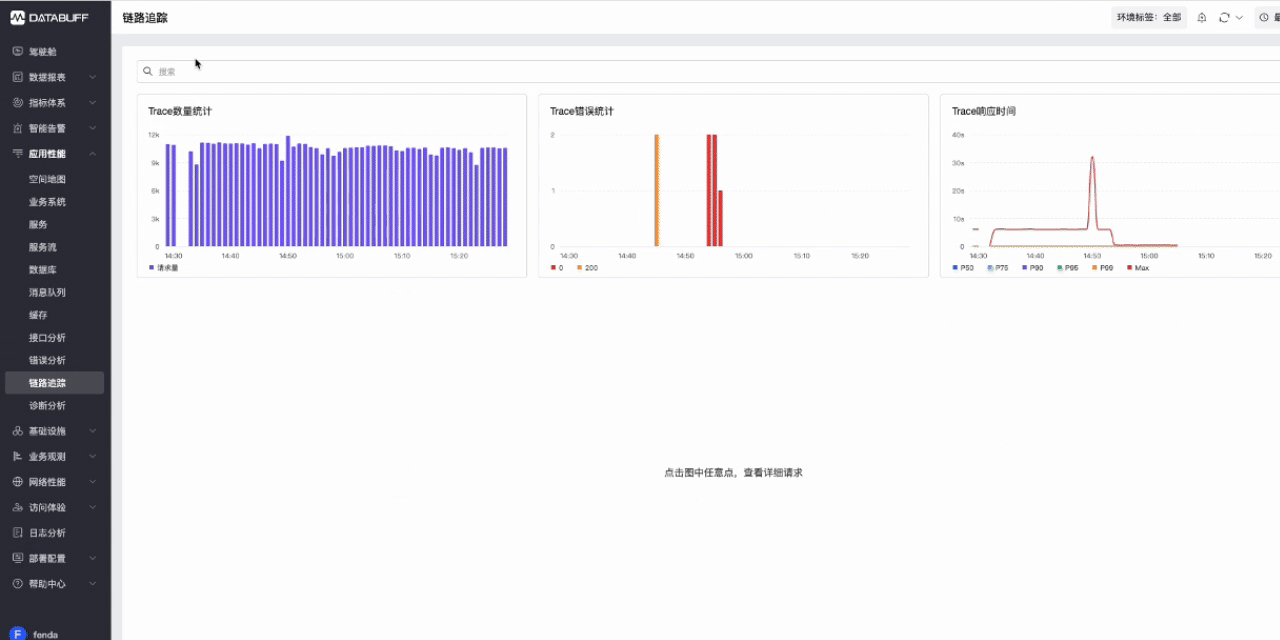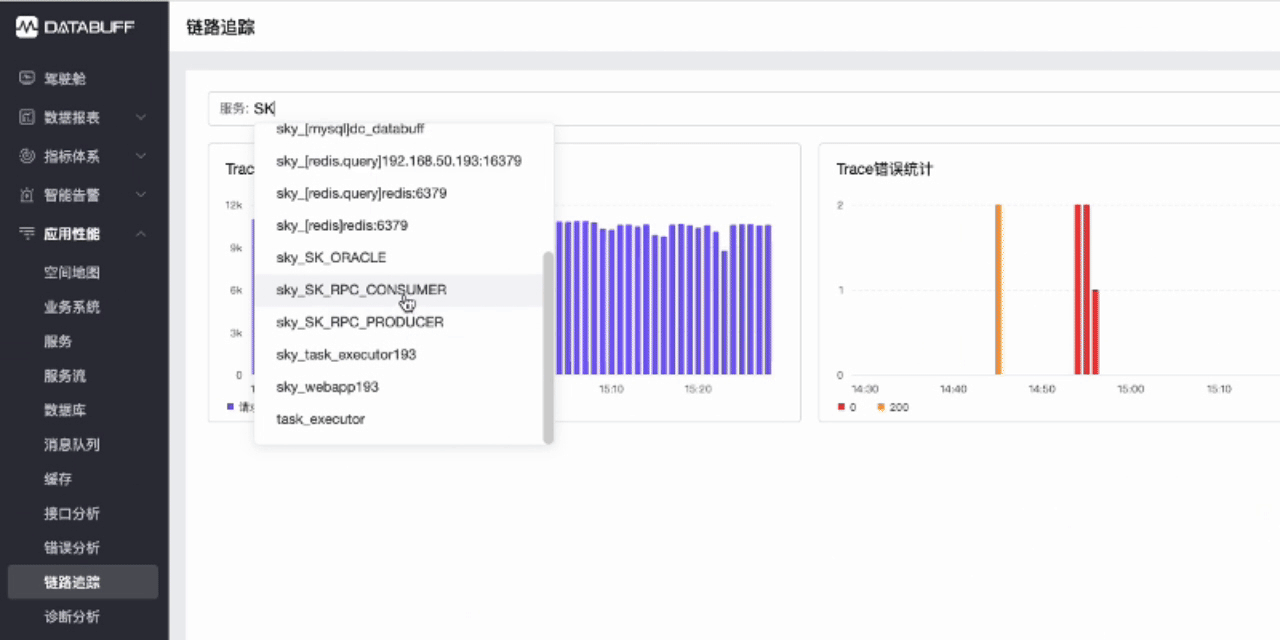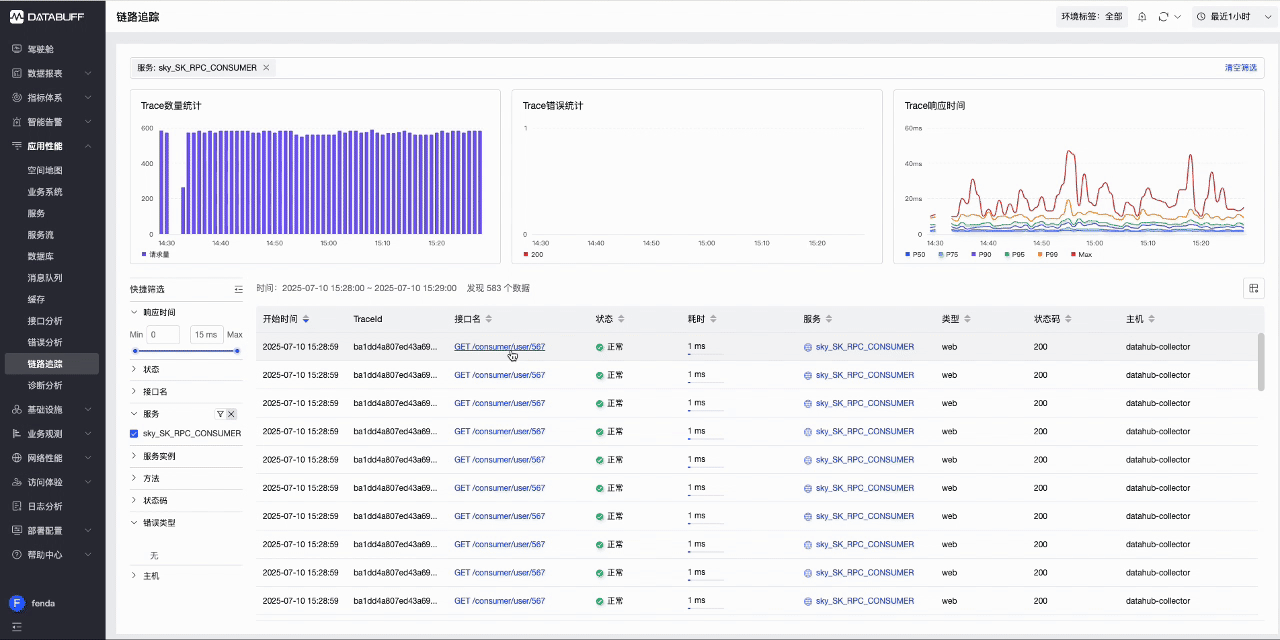
- 此时DataBuf平台已对Trace数据自动完成清洗,获取到了服务调用、请求耗时等信息.
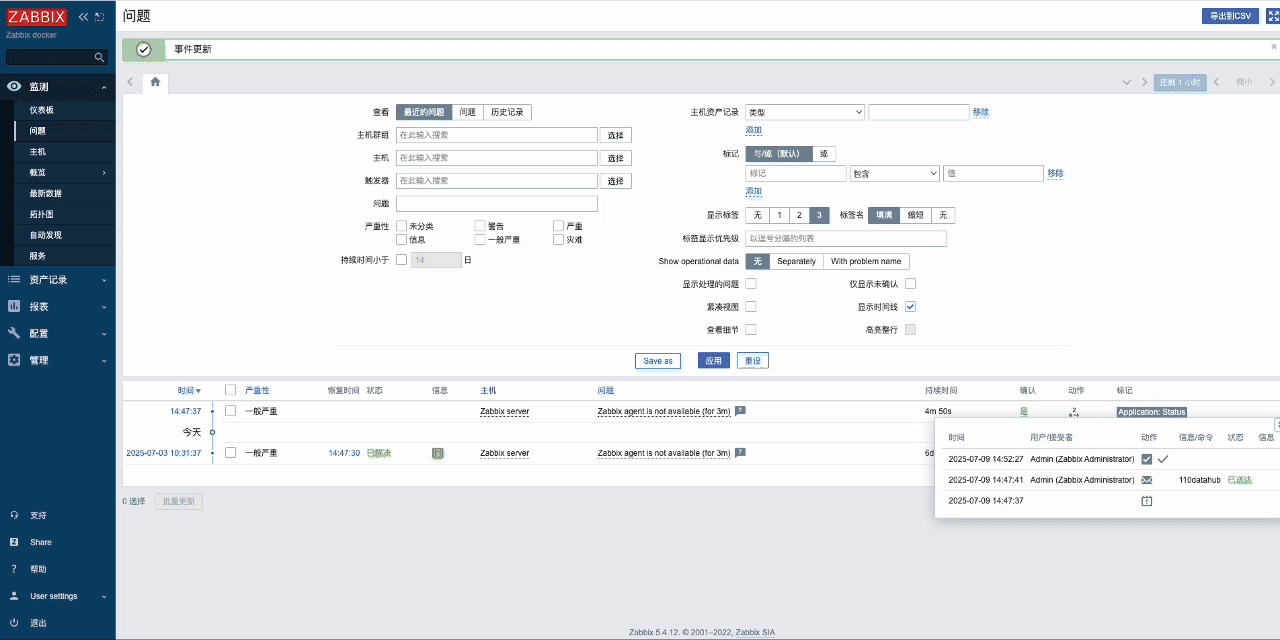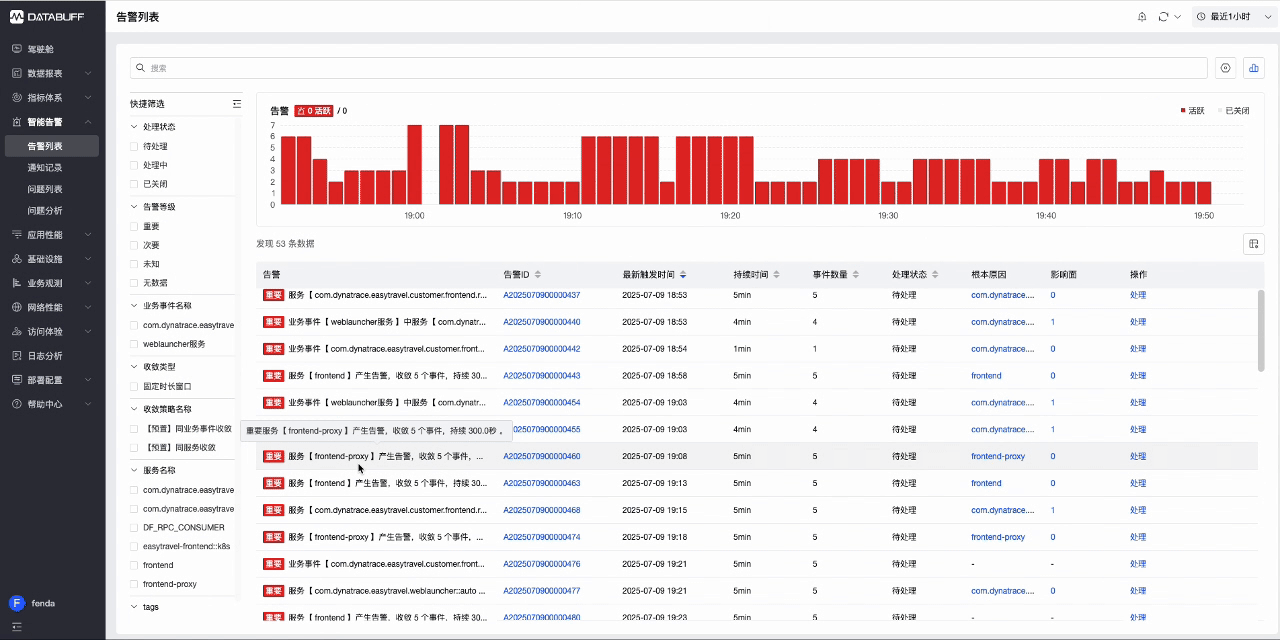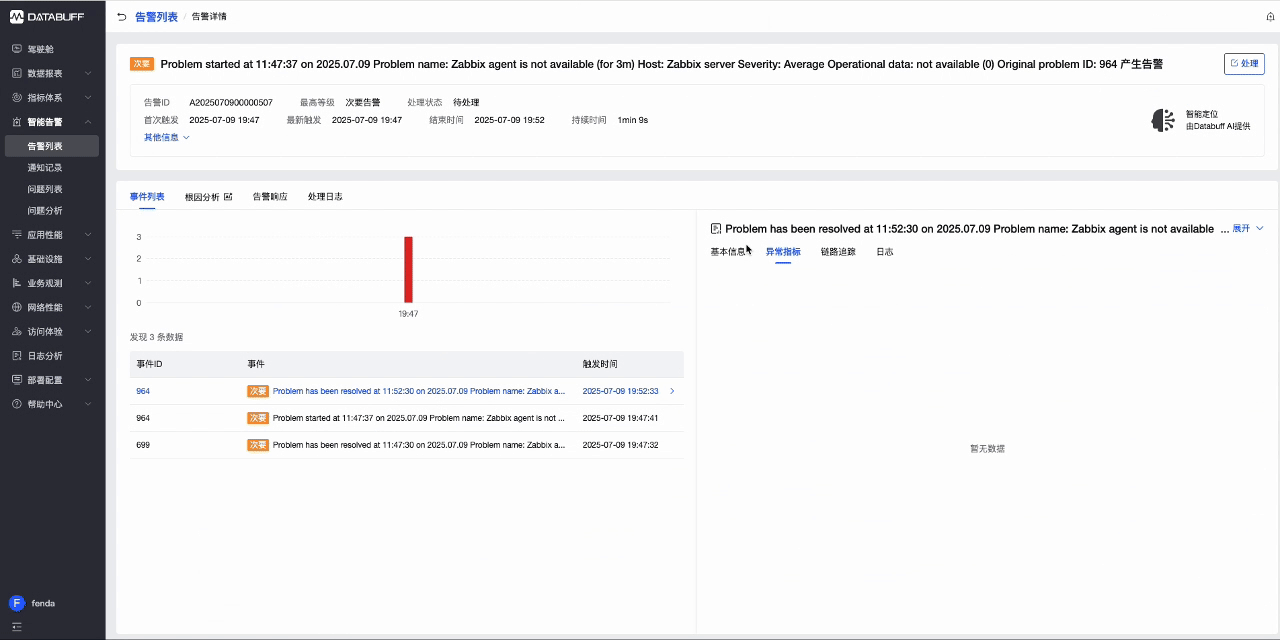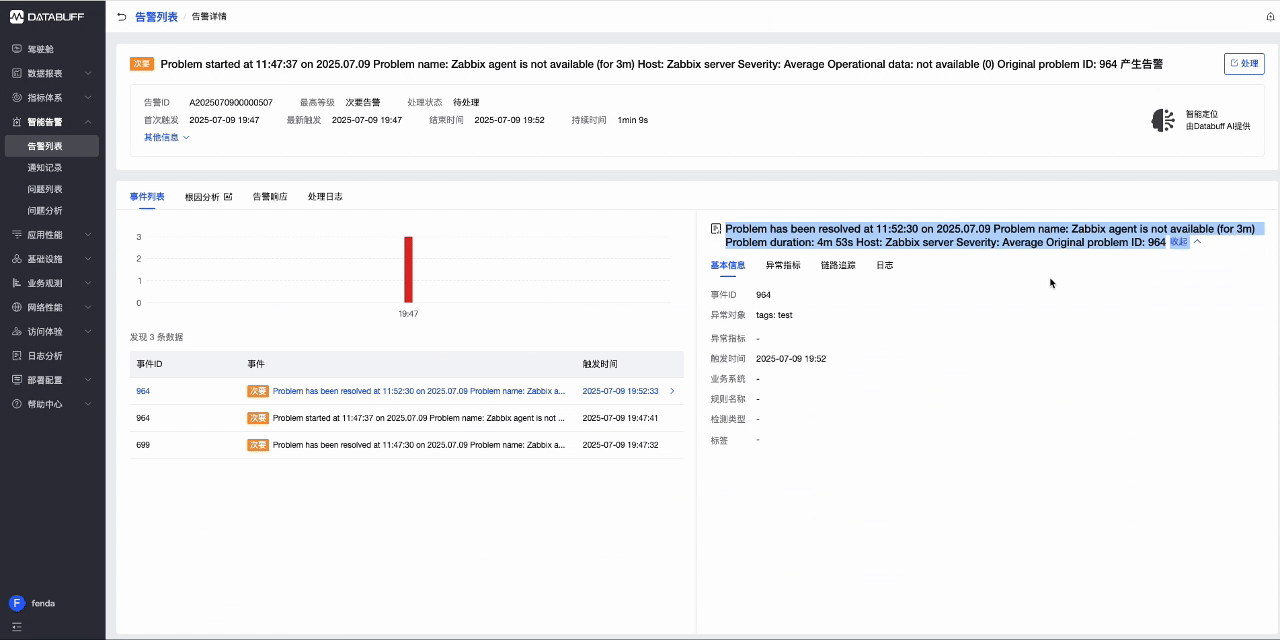
7.2 场景2:一键接入Zabbix事件数据
7.2.1 数据接入
- 首先同样是创建管道,选择Zabbix接入模版

- 复制监听URL,并启用该管道
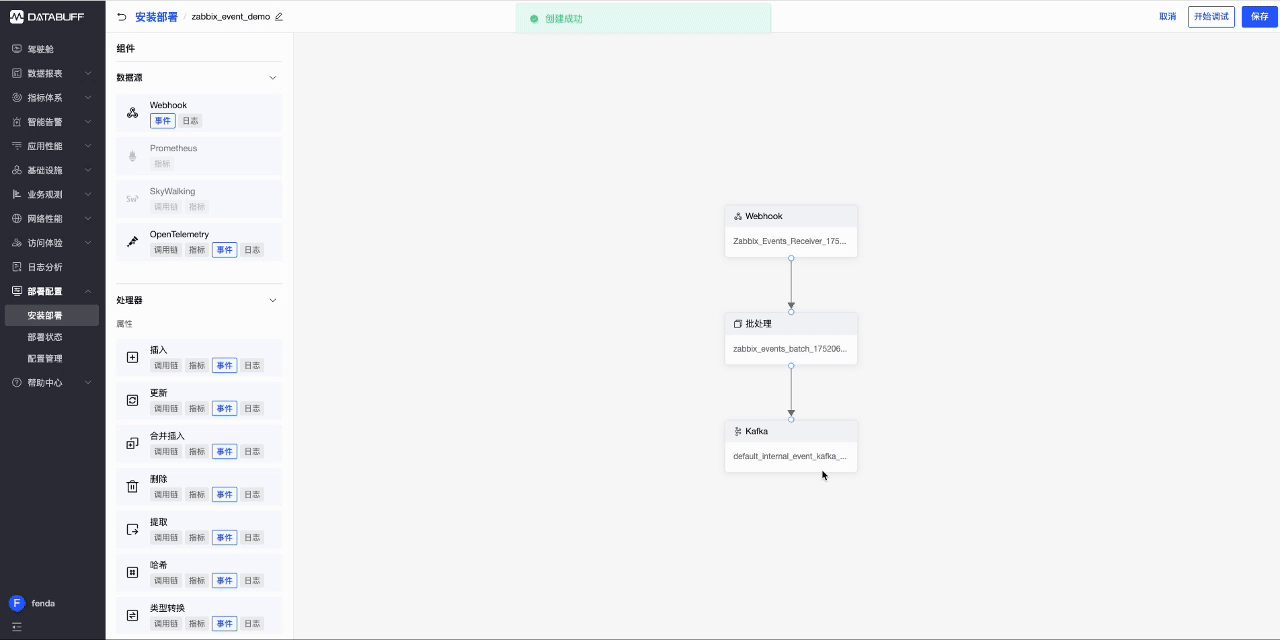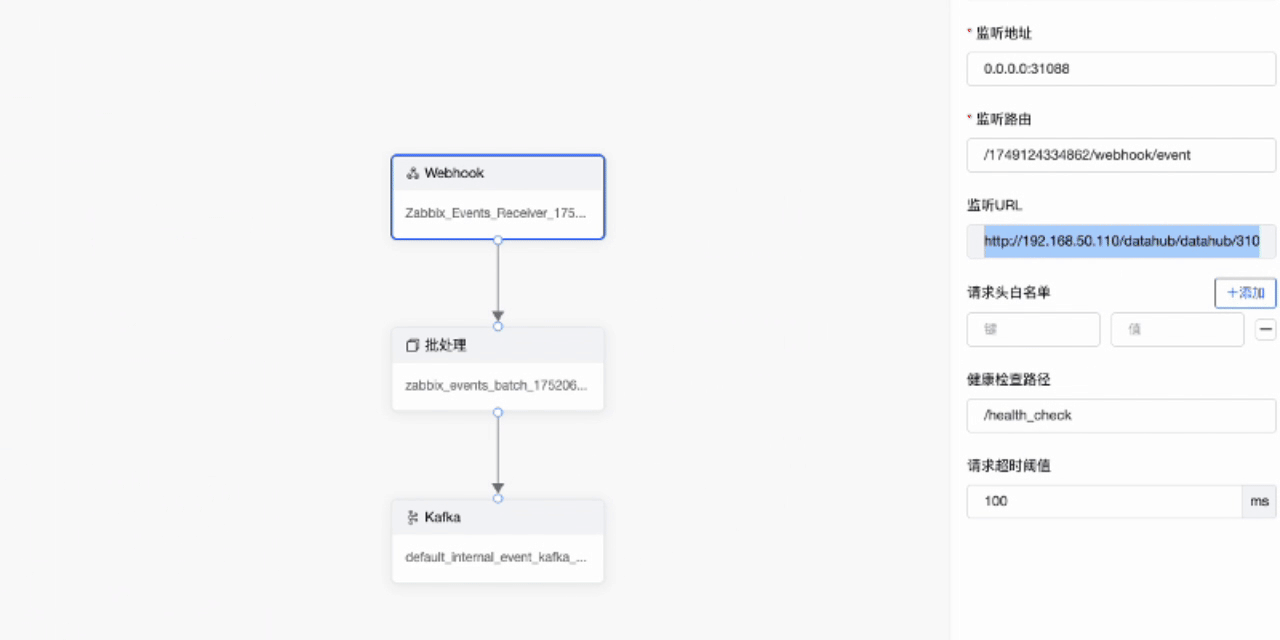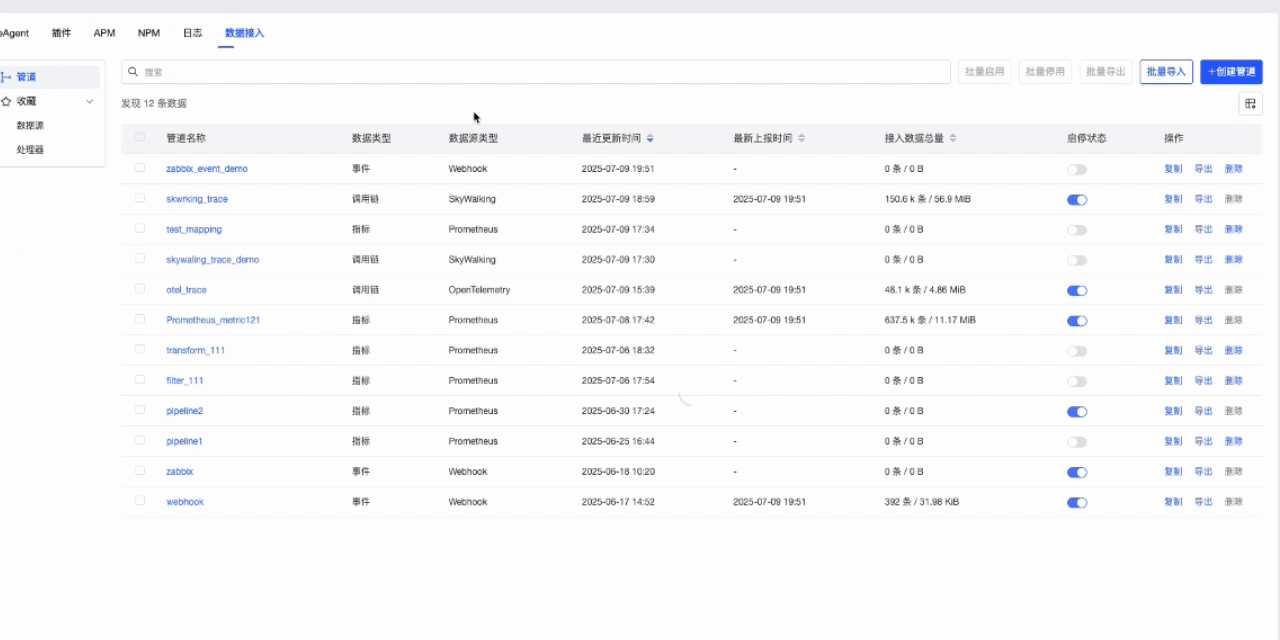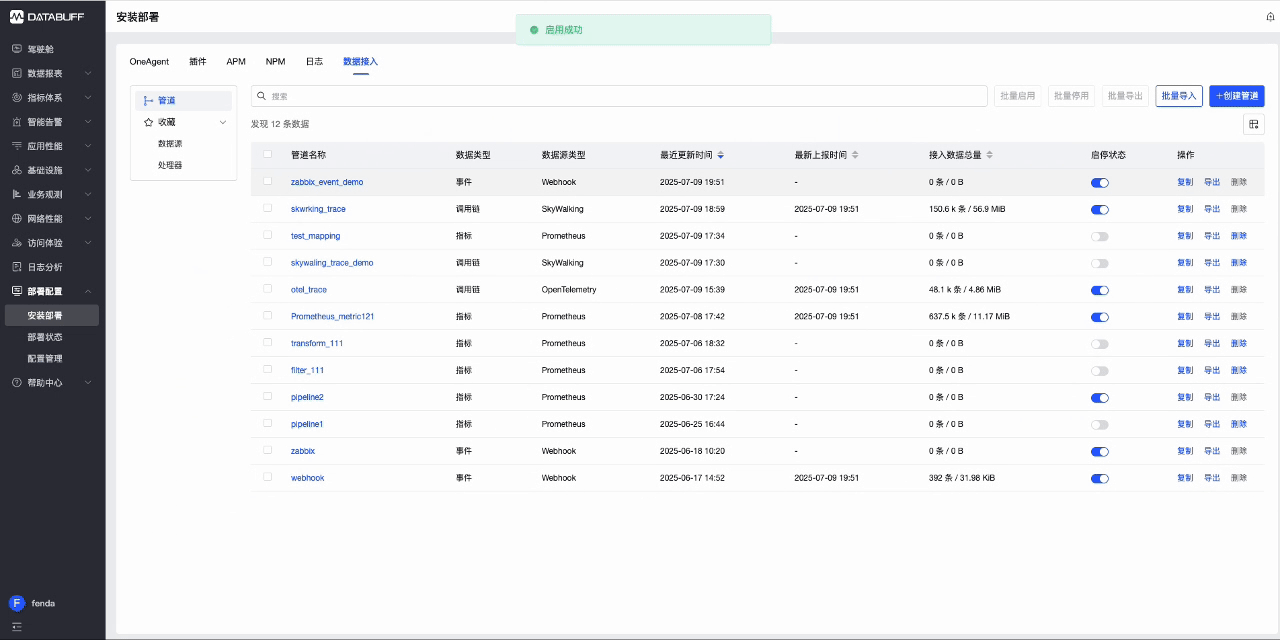
- 打开zabbix,并在报警媒介中找到datahub,粘贴刚才复制的监听URL并更新
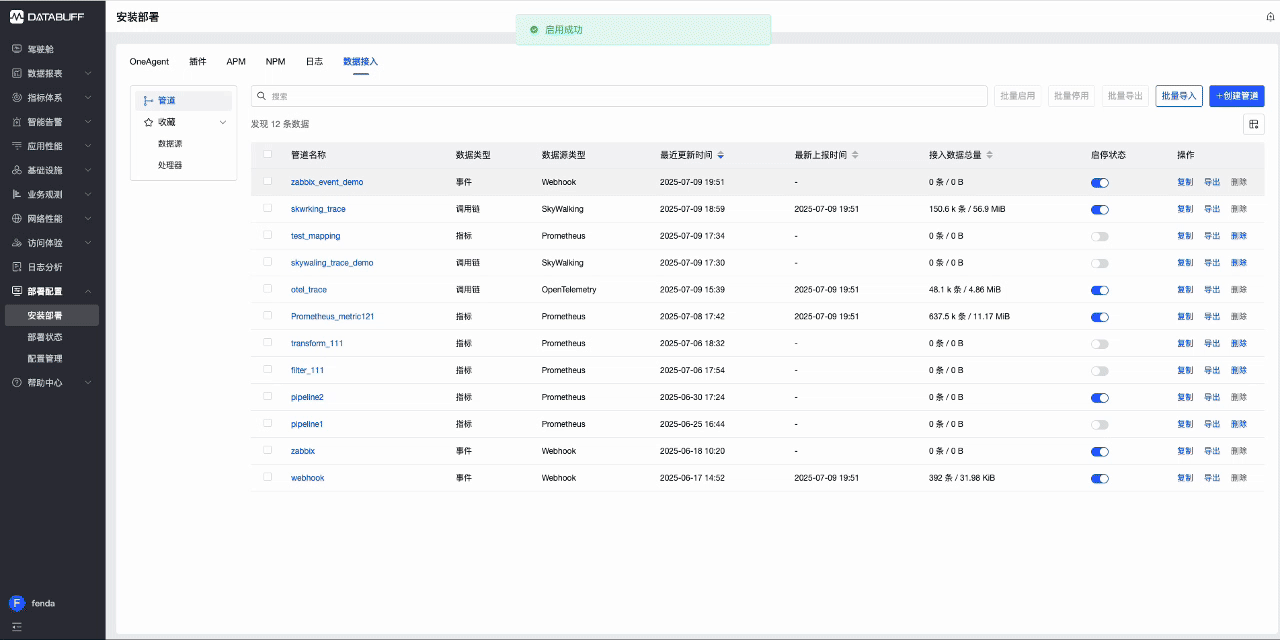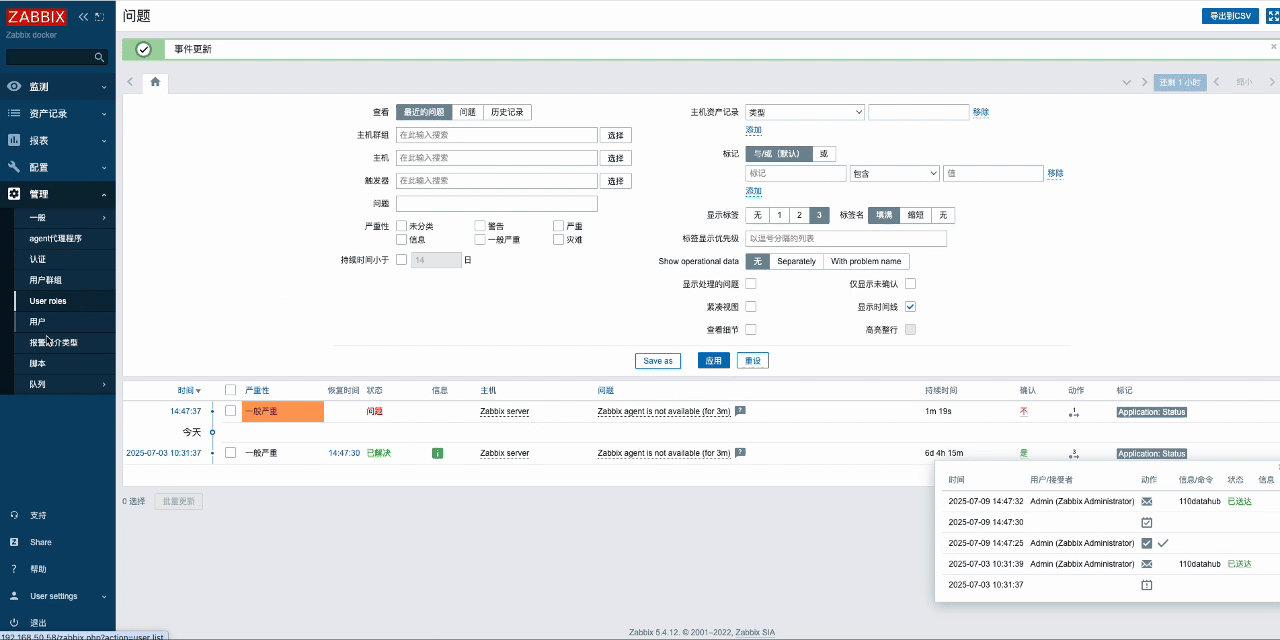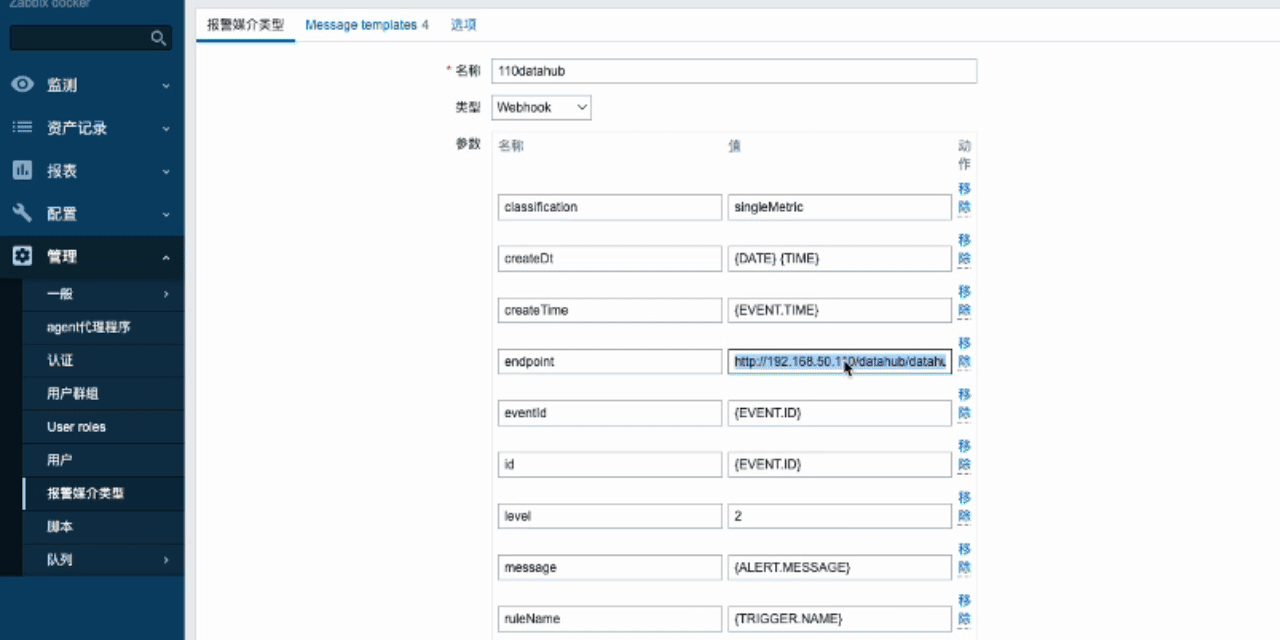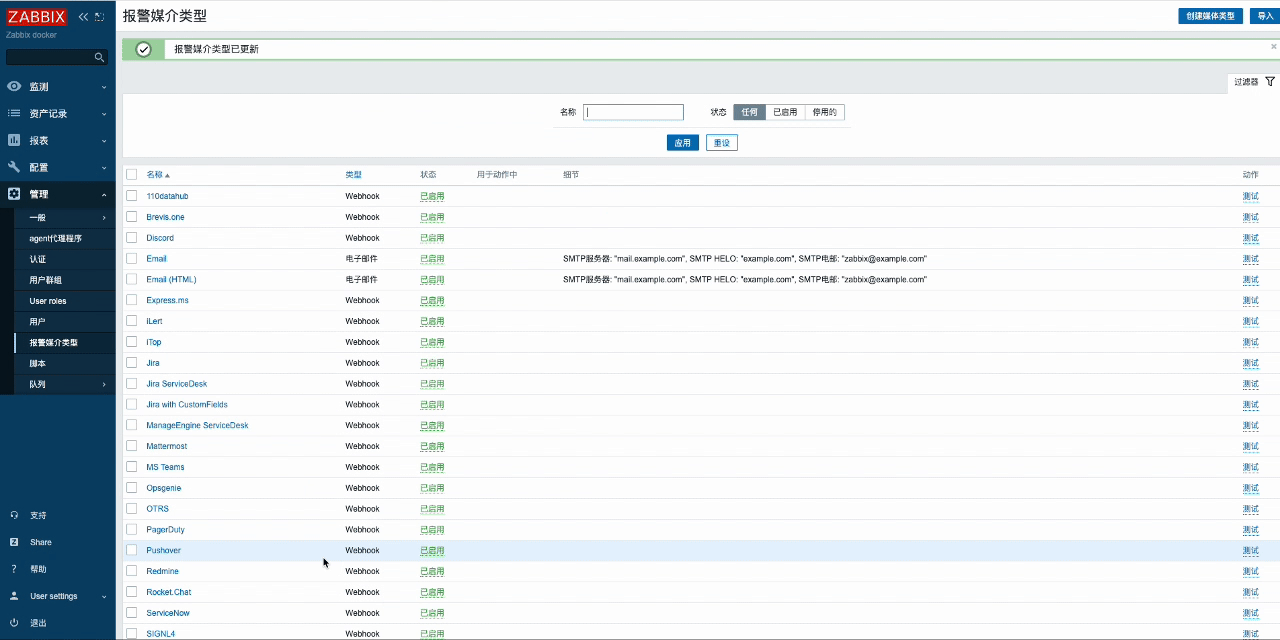
- 触发zabbix事件(这里以确认并关闭问题为例),然后等待Zabbix问题关闭并触发报警媒介,同时向DataHub发送事件。
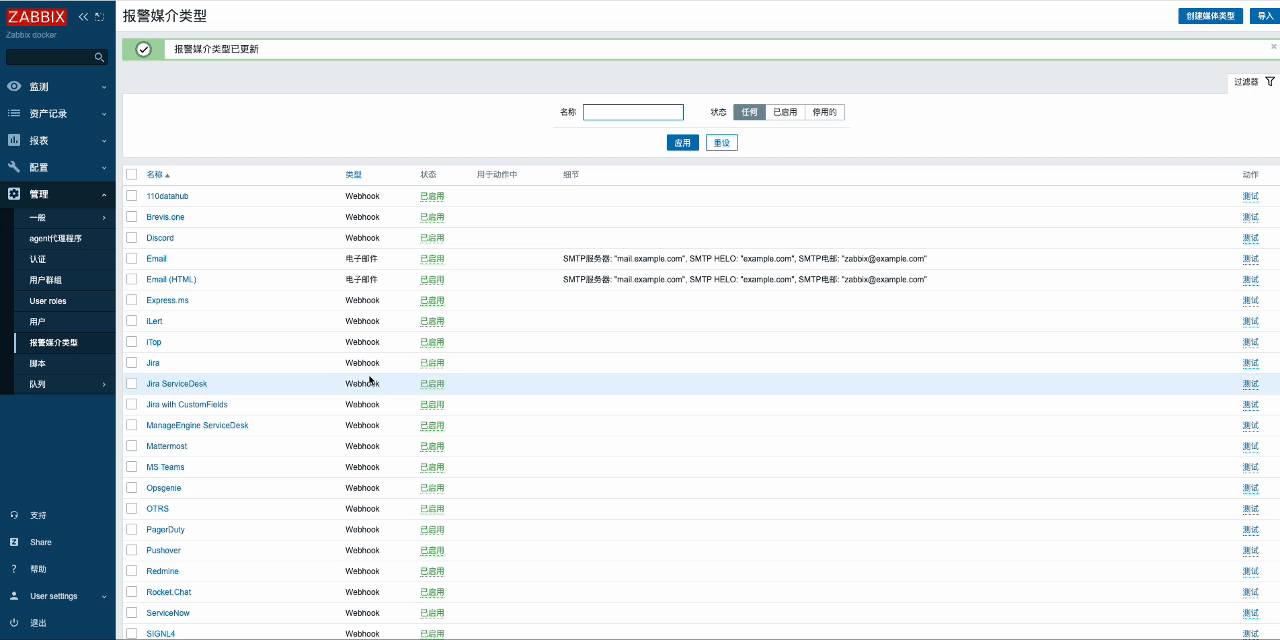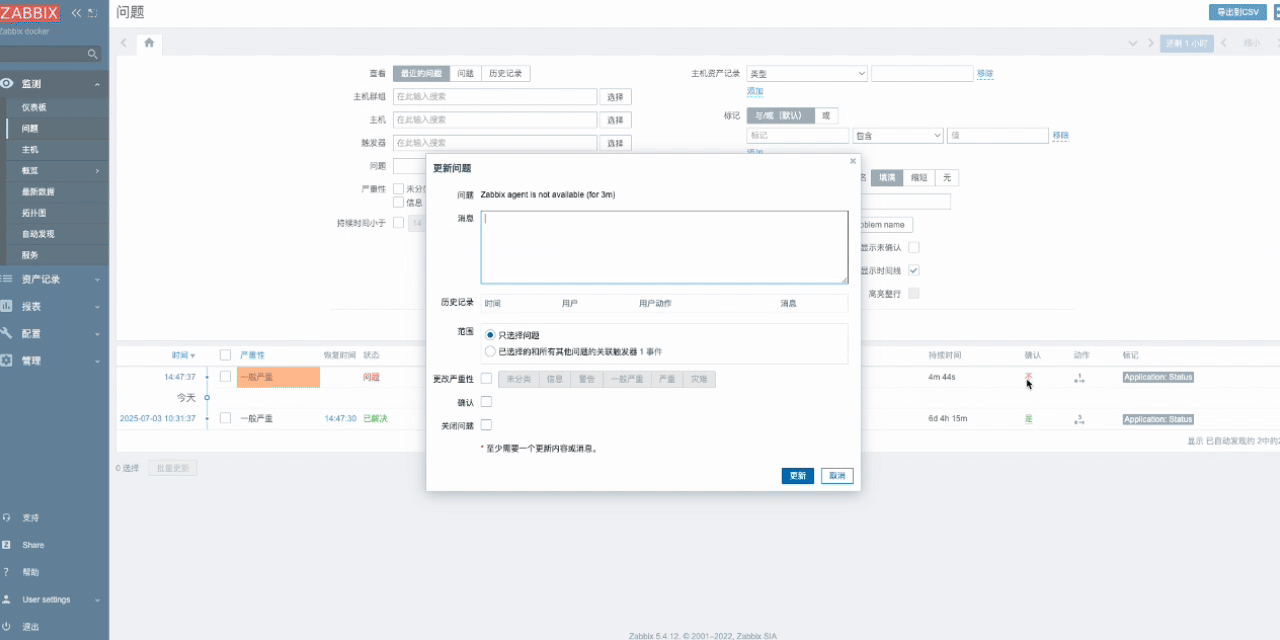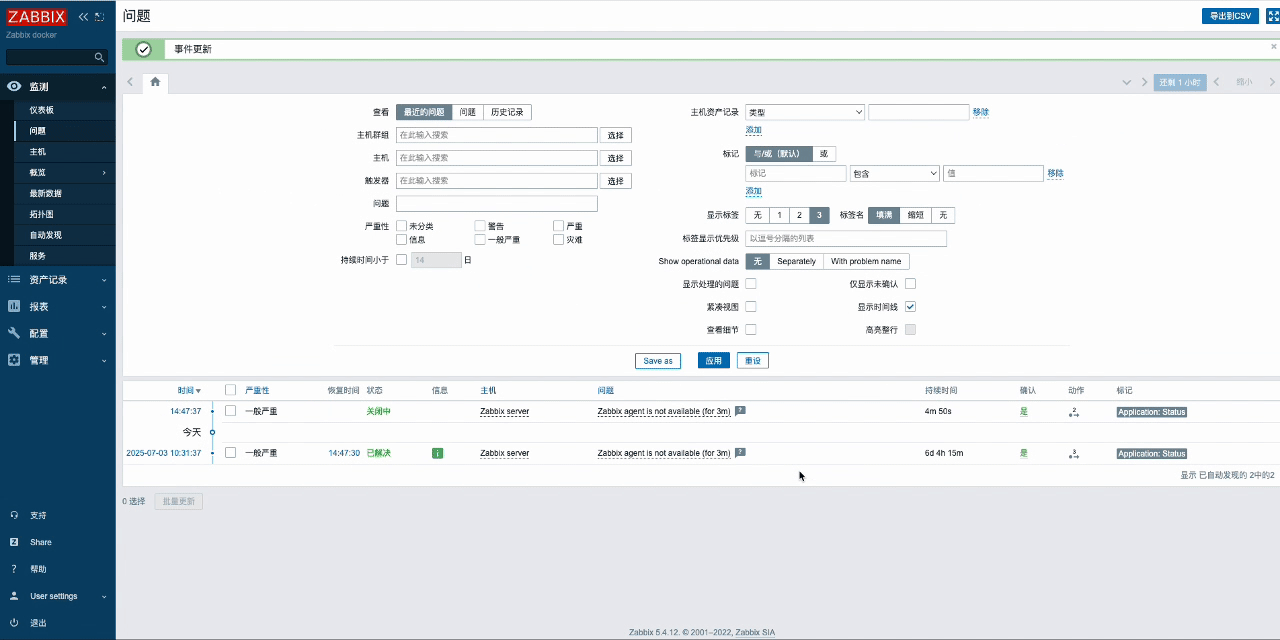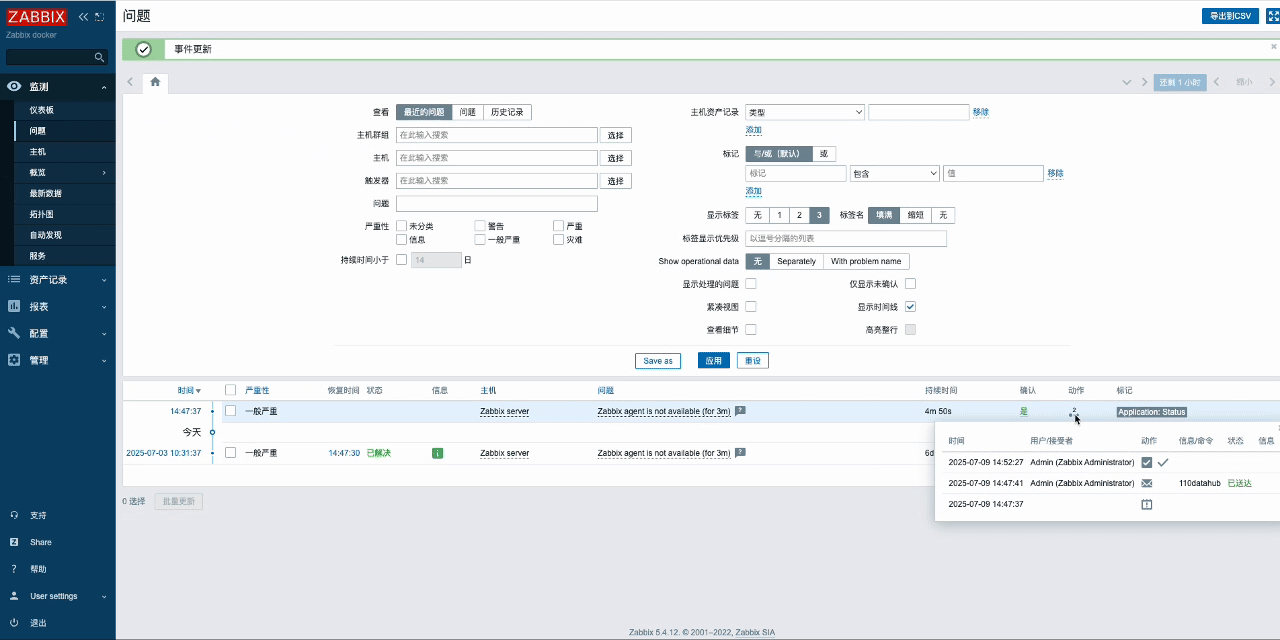
7.2.2 数据处理流程解析
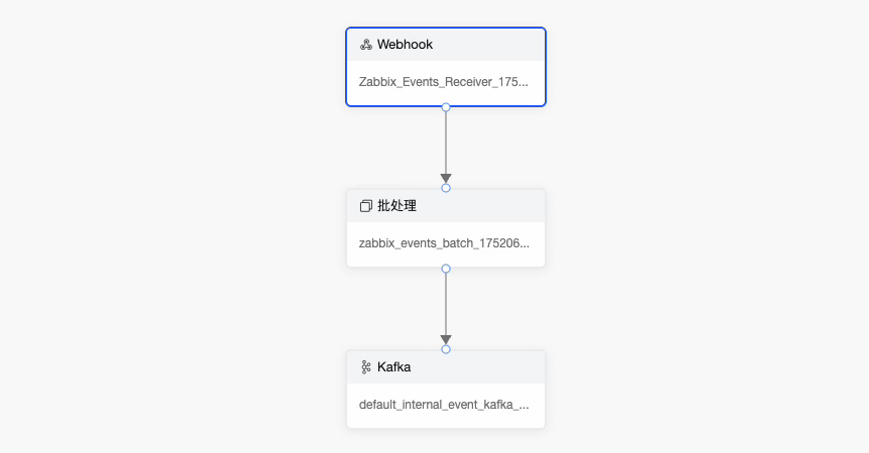
上面步骤中管道使用的三个算子:
- Webhook 算子
接受通过webhook 方式发送过来的数据。
- 批处理 算子
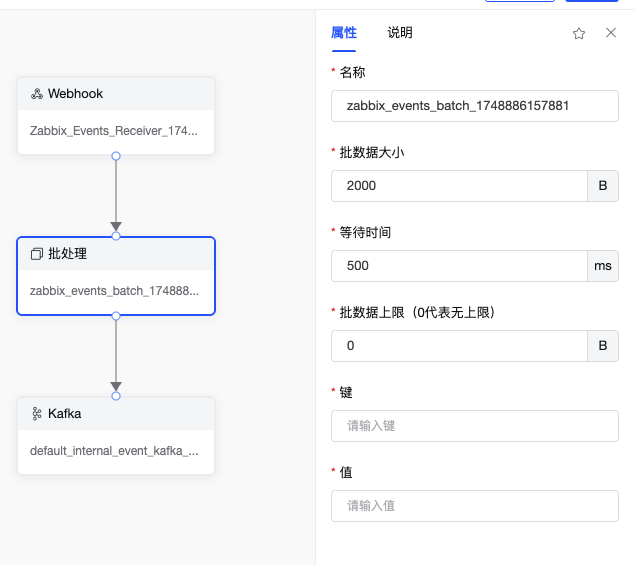
用于将传入的观测数据(跟踪、指标、日志)进行批量聚合和缓冲,减少数据处理的频率和资源消耗。其核心功能包括:
批量聚合:将单个数据项累积到指定数量或时间阈值后,以批量形式传递给下游组件(如导出器)。
缓冲控制:通过配置队列大小和超时时间,平衡内存占用与数据传输延迟。
兼容性:支持跟踪(Traces)、指标(Metrics)、日志(Logs)三种信号类型,可与任意上游接收器(如 Receiver)和下游导出器组合使用。
- Kafka 算子
将数据发送到DataBuff内置的事件渠道,便于后期告警压缩合并。
7.2.3 数据展示效果
登录DataBuff平台-智能告警,查看zabbix发送的事件
其他接入
- DataHub还支持符合Open telemetry,Prometheus,Kafka,Zipkin ,Jaeger,Fluentd,RabbitMQ等各平台和组件的数据推送,以及内置Pipeline处理模版,可以快速平滑对接到DataBuff 平台。
八、结语
在数据驱动的时代,企业的竞争力越来越依赖于数据的“实时性、准确性、关联性”。DataHub通过重构数据Pipeline,让分散的数据“可汇聚、可关联、可复用”,为企业的监控告警、业务分析、故障诊断提供坚实的数据基础。

















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









