




倒排索引是一种用于全文搜索的数据结构。它的主要功能是将文档中的单词作为索引项,映射到包含该单词的文档列表。通过倒排索引,可以快速准确地定位到与查询词相匹配的文档列表,从而大幅提高查询性能。倒排索引在搜索引擎、数据库和信息检索系统中被广泛应用。
倒排索引的基本原理
倒排索引的概念
假设我们有如下的一个数据表:
CREATE TABLE test(id INT, title STRING);
INSERT INTO test VALUES
(1, 'Index helps search words'),
(2, 'Search articles quickly'),
(3, 'Index speeds up searches')为了查找数据表中包含某个单词或词组的行,数据库通常会使用 like 语句来进行查找。例如,查找出标题中包含单词 "search" 的行,可以使用如下的 SQL 语句进行查询。
SELECT * FROM test WHERE title like '%search%';
┌────────────────────────────────────────────┐
│ id │ title │
│ Nullable(Int32) │ Nullable(String) │
├─────────────────┼──────────────────────────┤
│ 1 │ Index helps search words │
│ 3 │ Index speeds up searches │
└────────────────────────────────────────────┘这种方式虽然可以满足一些场景的使用需求,但是也存在几个问题:
- 需要进行全表数据扫描再进行过滤,当数量较大时通常会比较耗时。
- 只能进行简单的单词匹配,无法支持复杂的查询逻辑,如「查找单词 "search" OR "quickly" 」等。
- 无法根据数据与查询词的相关性进行排序。
倒排索引通过为文档中的词语(Term)与文档标识符(DocId)建立映射关系来实现高效的全文检索。这里我们可以使用 test 表中的 id 列作为 DocId 。
生成倒排索引主要有如下三个步骤:
-
首先对数据进行分词,根据语义拆分为一个个的单词,我们采用了 jieba 对中文进行分词。
-
对拆分后的单词进行过滤,将单词转为统一的 Term,主要包括如下几种:
- 字母都转为小写字母。
- 去除停用词 (stop word),如 a、the 等。
- 提取单词的词干,例如将 quickly 转为 quick。
-
将 Term 作为索引词,与对应的 DocIds 建立一个映射关系。
经过以上处理之后,我们可以得到 Term 与 DocIds 映射的倒排索引。
| Term | DocIds |
|---|---|
| index | 1,3 |
| help | 1 |
| search | 1,2,3 |
| word | 1 |
| article | 2 |
| quick | 2 |
| speed | 3 |
| up | 3 |
有了倒排索引,在查询的时候我们就能够根据关键词快速、准确地找到对应的数据。
倒排索引的结构
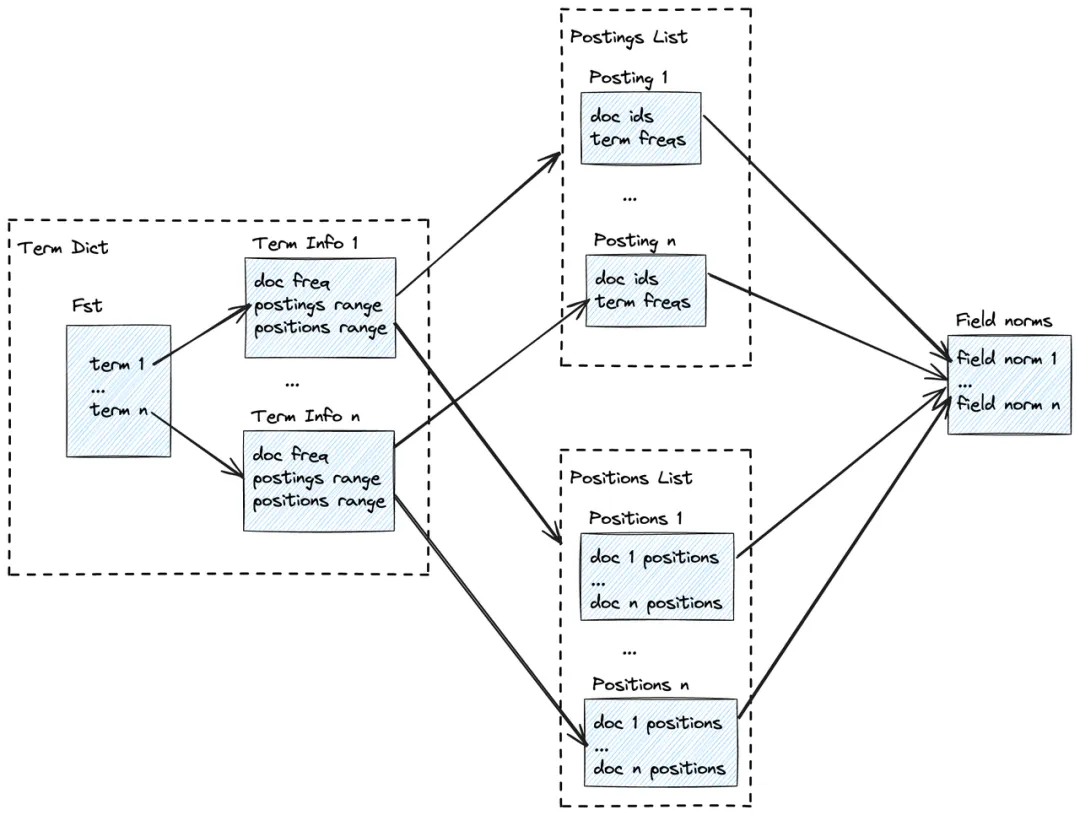
倒排索引的最主要功能是通过一个查询词(Term)找到相关的信息(TermInfo),通常使用 FST(Finite-State Transducer) 构建倒排词典(Term Dict)来实现这个功能。在构建倒排 FST 时,为每个 Term 创建一个状态,并将 TermInfo 作为输出符号附加到该状态。在查询时,给定一个 Term ,可以在 FST 中找到与之对应的最终状态,并从该状态中提取出相应的 TermInfo。关于 FST 更详细的原理可以参考这篇文章的介绍。
相比其它 key-value 类型的数据结构,例如 HashMap,Trie 等,FST 具有如下的优点:
- 快速查询:FST 利用其确定性的状态转移特性,可以在非常短的时间内完成查询操作。相比于其它数据结构,FST 的查询速度更快,特别是对于大规模的索引和复杂的查询条件。
- 小内存占用:FST 可以对倒排索引进行压缩,占用的内存空间很少,这对于大规模数据集尤为重要,可以节省存储成本并提高索引的加载和查询效率。
- 高效的前缀和模糊匹配:FST 支持前缀匹配和模糊匹配,可以快速找到以给定前缀开头的关键词,或者根据模糊匹配规则查找相似的关键词。
倒排索引除了根据查询词查找匹配的数据行之外,还需要计算查询词与数据的相关性,用于根据相关性进行排序。除了存储倒排词典(Term Dict)之外,还需要存储如下的一些数据:
- 文档标识符(DocId):使用数据表中一行数据的 RowId 来表示,用于过滤后查找原始数据。
- 词语(Term):数据分词并过滤处理后的一个词,用作索引词进行存储在 FST 结构中,每个 Term 会映射到一个 TermInfo。
- 词频(Term freq):Term 在一行数据中出现的次数。
- 文档频率(Doc freq):包含一个 Term 的行数。
- 字段长度(Field norm):每一行数据包含的 Term 数,即文档的长度。
- 位置(Position):记录 Term 在每一行中出现的位置,用于词组搜索。
以上数据中,文档标识符(DocId)和词频(Term freq)存储在倒排列表(Posting list)中,位置(Position)存储在位置列表(Position list)中。TermInfo 包含三部分信息:
- 文档频率(Doc freq)。
- 倒排列表范围(Postings Range):用于在倒排列表(Posting list)中找到查询词 Term 对应的信息。
- 位置列表范围(Positions Range):用于在位置列表(Position list)中找到查询词 Term 对应的信息。
查询时,首先通过 FST 找到 Term 对应的 TermInfo,再通过 TermInfo 找到文档标识符(DocId)列表,确定匹配的数据行。如果需要排序,可以使用词频(Term freq)、文档频率(Doc freq)、字段长度(Field norm)等计算出每一行的评分( Score)。此外,如果是词组搜索,还需要使用位置(Position)判断词组中的 Term 是否相邻。
倒排索引数据的整体结构如下图所示:
Score 算法
相关性评分( Score )的计算采用广泛使用的 BM25(Best Matching 25)算法。BM25 算法的核心思想是根据查询词频率(Term freq, TF)和逆文档频率(Inverse document freq, IDF)来计算文档的相关性,将文档和查询表示为向量,然后计算两个向量之间的余弦相似度。
BM25 算法的基本公式如下:
$$Score(D,Q)= {\textstyle \sum_{i=1}^{n}} IDF(q_{i})\times \frac{f(q_{i},D)\times(k_{1} + 1)}{f(q_{i},D) + k_{i}\times(1-b+b\times\frac{\left | D \right | }{avg(dl)}))} $$
其中:
- Score(D,Q) 是文档 D 与查询 Q 的相关性得分。
- $$q_{i}$$ 是查询中的第 i 个词。
- f($$q_{i$$, D)是词 qi 在文档 D 中出现的频率。 词频(Term freq)是衡量一个词在文档中重要性的基本指标。词频越高,这个词在文档中的重要性通常越大。
- IDF($$q_i$$) 是词 $$q_i$$ 的逆文档频率。逆文档频率是衡量一个词对于整个文档集合的独特性或信息量的指标。它是由整个文档集合中包含该词的文档数量决定的。一个词在很多文档中出现,其 IDF 值就会低,反之则高。这意味着罕见的词通常有更高的IDF值,从而在相关性评分中拥有更大的权重。
- |D| 是文档 D 的字段长度(Field norm)。用于调整词频的影响,因为较长的文档可能仅因为它们的长度就有更高的词频。
- avg(dl)是所有文档的平均长度。用于标准化不同文档的长度,以便可以公平比较不同长度的文档。
- $$k_1$$ 和 b 是可调的参数, $$k_1$$ 用于控制词频的饱和度,较高的 $$k_1$$ 值意味着词频对评分的影响更大,通常 $$k_1$$ 在 1.2 到 2 之间。 b 用于控制文档长度对评分的影响的参数,取值在 0 到 1 之间,通常设为 0.75。
IDF 计算公式如下:
$$IDF(q_{i})= \ln_{}{(\frac{N-n(q_{i})+0.5}{n(q_{i})+0.5} + 1)} $$
其中
- N 是文档集合中的文档总数。
- n($$q_i$$) 是包含词 $$q_i$$ 的文档数量,即文档频率(Doc freq)。
查询时,通过 BM25 算法可以为每一行数据计算出一个相关性的评分(Score),这个评分表示该行数据与用户查询的相关程度,可以用于对搜索结果进行排序,将最相关的数据显示在前面。
倒排索引在 Databend 的实现
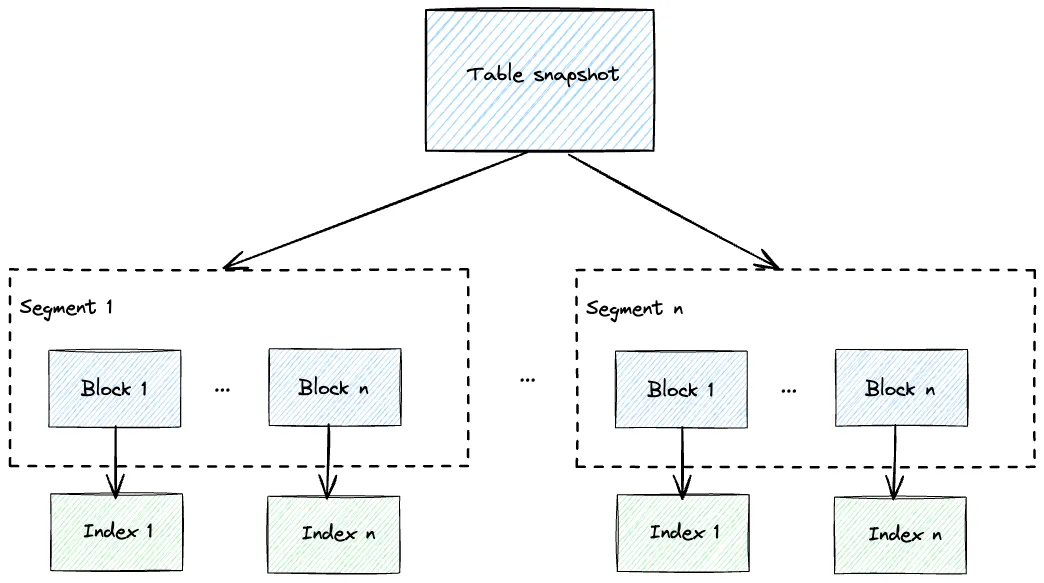
Databend 一个表的数据会分为若干个 segments,并在每个 segment 内进一步分为多个 blocks,这样的设计有利于并行处理和查询数据,从而提高整体的处理速度和响应性能,使得 Databend 能够处理大规模数据集,提供高性能的数据处理和查询能力,并保证数据的可靠性和可用性。在生成索引数据时,我们会为每个 block 生成一个单独的索引文件,相比于包含多个 block 的大索引文件,单独索引的设计有如下的优点:
- 空间利用效率:将每个 block 生成一个单独的索引文件可以提高空间利用效率。由于每个索引文件仅包含一个 block 的数据信息,其大小相对较小。这种细粒度的索引文件设计可以减少索引文件的存储空间占用,特别适用于大规模数据集的情况。
- 并行处理查询:通过为每个 block 生成单独的索引文件,可以实现并行处理查询。在查询时,可以同时加载多个 block 的索引文件,并发地进行查询操作。这样可以充分利用多核处理器或分布式计算资源,加快查询的速度,提高系统的查询并发性能。
- 方便与其它索引结合:每个 block 原本就有 Range 索引和 Bloom 索引,可以快速的进行范围查询和点查询过滤,去掉不符合查询条件的 block,这样可以有效地减少需要加载的倒排索引文件数据,提高查询效率。
- 索引维护和更新效率:单独的索引文件设计有利于索引的维护和更新。当数据发生变化时,只需更新受影响的 block 的索引文件,而无需对整个表的索引文件进行操作。这样可以减少索引维护的开销,并支持实时数据的快速插入、更新和删除。
对于索引文件的内部数据结构,Databend 使用开源的 tantivy 库来实现倒排索引功能,主要有以下原因:
- 强大的功能:tantivy 是一个功能强大且成熟的全文搜索引擎库,具有完善的的功能和高效的查询速度。同时提供了丰富的查询语法和搜索选项,能够满足各种类型的查询需求。
- 可扩展性和灵活性:tantivy 的设计具有良好的可扩展性和灵活性。通过 tokenizer-api 可以实现自定义的分词算法,方便接入不同的分词库来实现对多种语言的支持。
- 社区支持和活跃度:tantivy 是一个开源项目,拥有活跃的社区和广泛的用户群体。这意味着可以从社区中获取技术支持、文档资源,并且能够与其他使用 tantivy 的开发者进行交流。这对于 databend 来说是一个重要的因素,可以借鉴和共享倒排索引的最佳实践。
Databend 倒排索引的整体结构如下图所示:
倒排索引的使用
为了使用倒排索引,我们需要首先创建倒排索引,以文章开头的测试表为例:
CREATE INVERTED INDEX idx1 ON test(title);
REFRESH INVERTED INDEX idx1 ON test;创建索引时可以指定一些配置项,例如是否支持中文分词,是否开启 stop words 过滤等。更多的详细信息可以查看 Databend 相关文档。REFRESH 命令主要用于刷新已有的数据生成索引,新插入的数据会自动生成倒排索引,不需要额外操作。
在查询语法方面,我们参考了 elasticsearch 的设计,提供了 match, query 和 score 函数。例如,可以通过下面的语法查询数据:
SELECT id, score(), title FROM test WHERE match(title, 'index');
┌─────────────────────────────────────────────────────────┐
│ id │ score() │ title │
│ Nullable(Int32) │ Float32 │ Nullable(String) │
├─────────────────┼────────────┼──────────────────────────┤
│ 1 │ 0.45315093 │ Index helps search words │
│ 3 │ 0.45315093 │ Index speeds up searches │
└─────────────────────────────────────────────────────────┘
SELECT id, score(), title FROM test WHERE query('title:"speeds up"');
┌────────────────────────────────────────────────────────┐
│ id │ score() │ title │
│ Nullable(Int32) │ Float32 │ Nullable(String) │
├─────────────────┼───────────┼──────────────────────────┤
│ 3 │ 1.8913201 │ Index speeds up searches │
└────────────────────────────────────────────────────────┘
SELECT id, score(), title FROM test WHERE query('title:words OR articles') ORDER BY score() DESC;
┌─────────────────────────────────────────────────────────┐
│ id │ score() │ title │
│ Nullable(Int32) │ Float32 │ Nullable(String) │
├─────────────────┼────────────┼──────────────────────────┤
│ 2 │ 1.0596459 │ Search articles quickly │
│ 1 │ 0.94566005 │ Index helps search words │
└─────────────────────────────────────────────────────────┘query 函数支持了多种查询语法,可以实现复杂的查询功能,相关语法可以查看 query 函数文档。
存在的问题和未来规划
Databend 的倒排索引在目前存在一些不足之处,主要问题是索引文件中的倒排列表(Posting list)和位置列表(Position list)占用空间过大,导致初次加载时速度较慢,并且占有较大的内存空间。为了解决这个问题,我们会考虑使用一些压缩算法或更紧凑数据结构来减小索引文件的存储需求,加快查询速度。另外,我们会进一步完善索引配置项和查询语法的支持,来满足更多的应用场景的使用需求。

















 2839
2839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









