




上周六,Databend Meetup·北京站圆满举办。本次线下活动聚焦“迈向 AI 驱动的数据平台”,汇聚了国内数据库领域多位一线专家,以及来自各行各业的技术负责人、DBA、开发与运维工程师,围绕“AI Ready 数据平台”的主题,共同探讨了大模型时代数据库和数据平台的创新演进与实战应用。
Databend 数据库研发工程师白珅以《Databend 向量索引:加速 AI 应用的数据引擎》为主题,系统梳理了向量数据、向量检索与索引技术在 Databend 平台上的最新实践与技术挑战,并以具体案例直观展示了产品在 AI 时代的能力进展与不足。
Databend 数据库研发工程师白珅
近年来,随着 AI 和大模型技术的发展,向量数据在各个领域的应用日益广泛。如何高效地存储、索引和查询向量数据,已成为一个重要的挑战。
Databend 作为一款云原生的 OLAP 数据库,也在积极拥抱向量数据。本文重点介绍 Databend 最近开发的向量数据类型和向量分析技术,帮助用户深入了解 Databend 在向量数据处理方面的能力。
一、向量索引的实践与性能优化
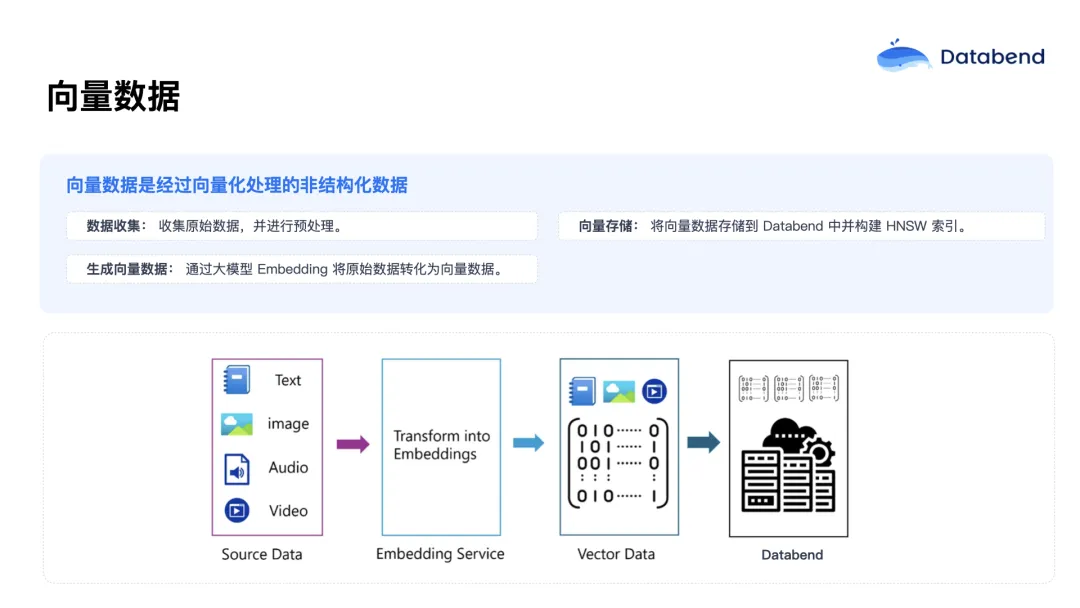
向量数据是将非结构化数据经过 embedding 向量化处理后得到的一种数据。非结构化数据包括图像、视频、文本、音频等,这些数据不像传统表格数据那样规整,而是以更加自由、多样化的形式存在,蕴含着巨大的价值。例如,通过分析用户的浏览记录和购买行为,我们可以构建更为精准的推荐系统。
为了将这些非结构化数据转化为计算机可处理的形式,通常需要使用大模型对数据进行处理,将其转换为数字化的向量。这些向量能够捕捉原始数据的各个维度信息,为后续分析和应用奠定基础。然而,传统数据库主要针对结构化数据设计,对于向量数据的处理能力有限,无法高效地存储和索引。为满足新需求,越来越多的数据库开始支持向量数据,并通过索引技术加速相关查询。Databend 同样支持向量数据,能够实现高性能的检索。
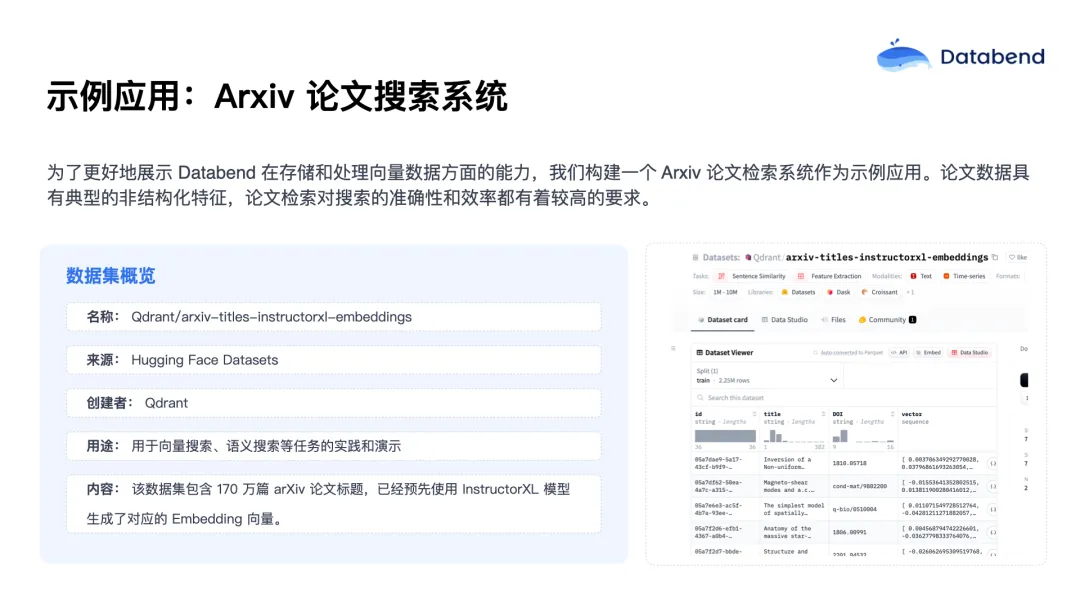
下面通过一个 Arxiv 论文检索系统的示例应用,展示 Databend 在向量数据存储和处理方面的能力。之所以选择论文检索系统,是因为其数据具备典型的非结构化特征,论文的标题和摘要都是文本,需要经过 embedding 技术转换成向量数据。同时,论文检索对搜索的准确性和效率要求很高,能够充分体现向量索引技术的优势。
这里选用了一个公开的数据集——托管在 Hugging Face Datasets 的 arxiv-titles-instructorxl-embeddings 数据集,包含 170 多万篇论文的标题,并已通过训练生成了对应的向量,可直接用于存储和查询,无需额外 embedding 处理。这让我们可以更专注于向量数据存储和检索能力的展示。

构建该搜索系统主要分三步:
第一步、表结构设计。 得益于 Databend 原生支持向量类型,我们可以直接将向量数据定义为 vector 字段,同时增加如 ID、title 等描述性字段,以提升数据可观测性。此外,还需要选择合适的索引类型,并通过参数调优优化性能。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









