




 本文介绍了在MapReduce自定义类中设置中文属性时遇到的乱码问题。从重写write和readFields方法,到map方法设置中文属性值,本地测试正常,但在集群上运行时出现乱码。经过排查,发现是由于maven打包时配置问题导致,日志显示GBK编码。解决方法是修改pom.xml文件相关配置,确保使用UTF-8编码,重新打包后,乱码问题得到解决。
本文介绍了在MapReduce自定义类中设置中文属性时遇到的乱码问题。从重写write和readFields方法,到map方法设置中文属性值,本地测试正常,但在集群上运行时出现乱码。经过排查,发现是由于maven打包时配置问题导致,日志显示GBK编码。解决方法是修改pom.xml文件相关配置,确保使用UTF-8编码,重新打包后,乱码问题得到解决。
自定义类中重写write和readFields方法
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.name);
out.writeUTF(this.course);
}
@Override
public void readFields(DataInput in) throws IOException {
this.name = in.readUTF();
this.course = in.readUTF();
}
map方法中设置中文属性值
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
if (split.length == 6) {
k.setName(split[0]);
k.setCourse("语文");
v.set(Double.parseDouble(split[3].trim()));
context.write(k, v);
k.setCourse("数学");
v.set(Double.parseDouble(split[4].trim()));
context.write(k, v);
k.setCourse("英语");
v.set(Double.parseDouble(split[5].trim()));
context.write(k, v);
}
}
打开本地结果文件,发现也都正常
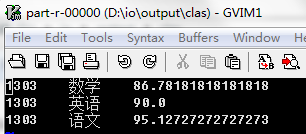
maven打包到集群上运行查看结果

这时候发现乱码了!!!
开始检查数据文件UTF8结果文件也是UTF8,整个项目工程也是UTF8,就是设置的中文属性输出后变成乱码,真是奇怪了,后来在我第二次打包过程中发现日志中写了GBK,哦!原来是maven的配置问题。修改pom.xml
<encoding>utf8</encoding>
再次打包到集群上运行查看结果


















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









