



项目主页:https://github.com/opendatalab/OmniDocBench
Hugging Face:https://huggingface.co/datasets/opendatalab/OmniDocBench
论文:https://arxiv.org/abs/2412.07626
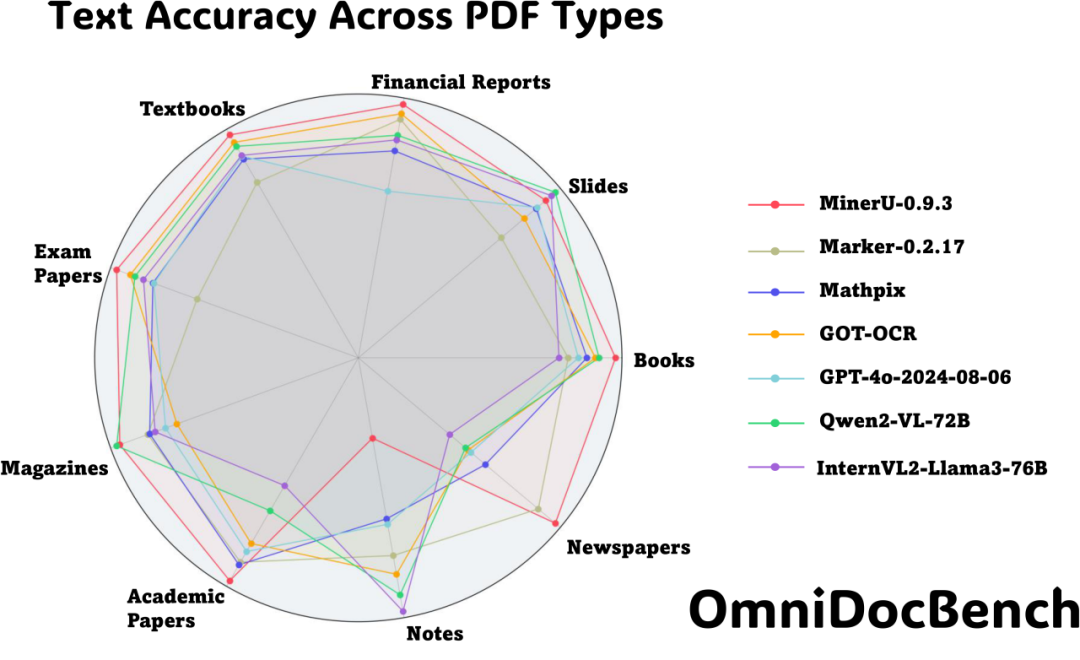
不同模型多种文本类型在OmniDocBench上的表现
文档内容提取作为计算机视觉的基础任务之一,在大语言模型训练数据获取和检索增强生成等技术中发挥着关键作用,然而我们发现LLM大量使用了论文期刊的数据,但是报纸、杂志等同样高质量但排版复杂的文件没有得到很好的利用。基于这一需求背景,上海人工智能实验室与2077AI等多家机构共同开源的OmniDocBench项目,通过构建覆盖九大类型 (学术论文、教科书、考试试卷、杂志、书籍、笔记、财报、报纸、幻灯片)的多源文档解析评测基准,成功解决了现有评测体系在文档类型多样性和评估维度完整性方面的不足。这一创新性的评测框架不仅为文档解析技术的发展提供了可靠的评估标准,更开创了文档智能评测的新范式。
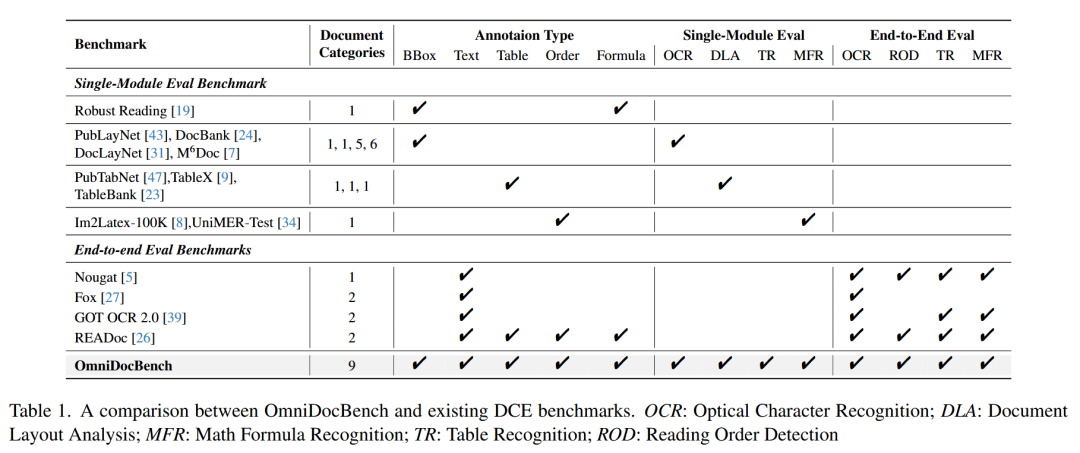
相关工作对比
深度解构与重构:全维度评测体系的精密设计
OmniDocBench通过系统化的数据构建流程开创了文档解析评测的新范式。
在数据获取阶段,项目团队从20万份初始PDF文档入手,运用ResNet-50与Faiss聚类采样出6000页数据,保证分布的合理且丰富,能够用最有"代表性"的数据构建评测数据集。这些页面经过专业标注人员的属性标注,最终经过严格筛选和平衡,形成了包含981页高质量样本的评测数据集,涵盖了从学术论文到考试试卷等九大类文档类型。
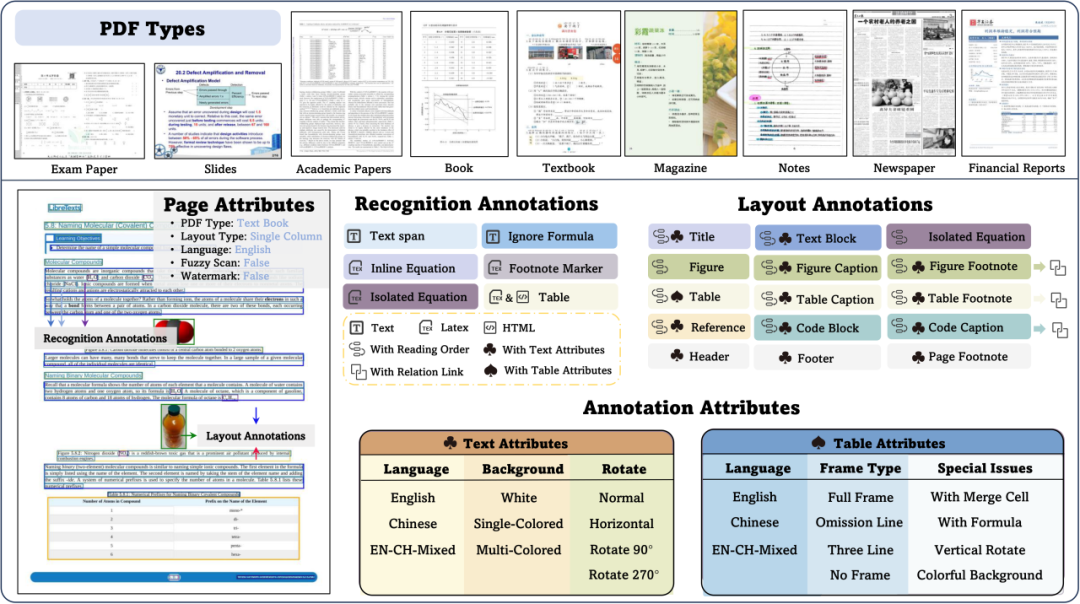
OmniDocBench类型与标注信息概览


OmniDocBench涵盖的九大文本类型一览
在标注体系的设计上,OmniDocBench构建了一个前所未有的多层级标注框架。在布局检测层面,项目不仅完成了19种区域类型的边界框标注,还创新性地引入了布局属性标注、阅读顺序标注和从属关系标注。这种立体化的标注体系使得数据集能够全面评估模型在不同场景下的表现。特别是在内容识别标注方面,针对不同类型的内容区域采用了差异化的标注策略:纯文本内容采用直接文本标注,公式内容使用LaTeX格式标注,而表格则同时提供HTML和LaTeX两种格式的标注,确保了评测的全面性和准确性。
为确保标注质量,OmniDocBench实施了一套严密的三重质控机制。首先利用先进的人工智能模型进行智能预标注,包括使用微调后的LayoutLMv3进行布局检测,以及采用PaddleOCR、UniMERNet和GPT-4o分别处理文本、公式和表格的识别。随后,专业的标注团队对预标注结果进行全面校正,不仅精细化修正每个检测框,还补充了阅读顺序和从属关系的标注。在最后的专家质检环节,项目创新性地引入CDM渲染技术识别不可渲染元素,并由三位领域专家进行最终审核,确保了数据集的极致可靠性。
创新评估方法与深度性能分析
创新性和系统性是OmniDocBench的评估框架突出优势。
在提取模块中,项目设计了一套完整的处理流程,从预处理开始就注重细节的标准化,包括移除图片、规范化markdown标签等基础工作。在特殊组件提取方面,采用了精心设计的提取顺序,确保不同类型的内容能够准确识别和提取。特别是在行内公式的处理上,创新性地采用统一的Unicode格式转换方案,解决了不同模型输出格式不一致的问题。
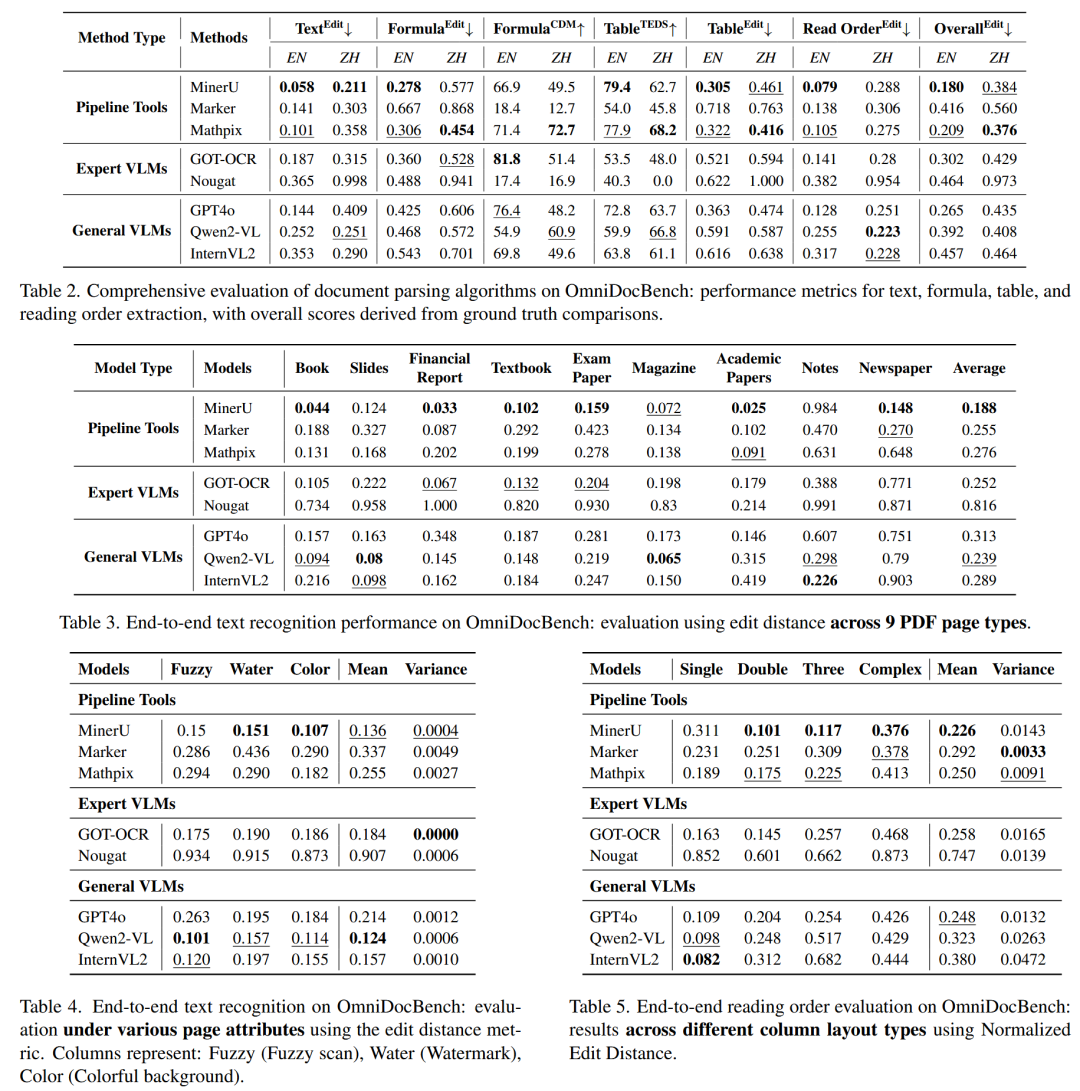
基于 OmniDocBench 对多种文档解析和识别方法的性能评估
在实际评测中,OmniDocBench展现出了优秀的模型区分能力。在具体任务上,不同模型展现出各自的优势:DocLayout-YOLO在多样化文档的布局检测中表现突出,RapidTable在表格识别的语言适应性方面独树一帜,而PaddleOCR则在传统OCR任务中保持领先地位。特别是在公式识别这一极具挑战性的任务中,GPT-4o、Mathpix和UniMERNet三个模型在CDM指标上的优异表现,展示了当前技术在特定领域的突破性进展。
作为开源社区的重要成员,2077AI深度参与了OmniDocBench项目的开发过程,在数据集构建、评测框架设计和结果验证等多个环节做出了重要贡献。未来,OmniDocBench将继续扩展其评测维度和应用场景。通过引入参数化规则生成、深化推理层次评估等创新方法,进一步提升评测体系的完备性。同时,随着多模态评测能力的发展,OmniDocBench有望在更广泛的领域发挥其评估价值。2077AI将继续携手开源社区,推动文档智能技术的进步,为构建更强大的人工智能系统贡献力量。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









