







 本文详细解析了OpenCV中基于Harr的训练数据结构,包括AdaBoost和HAAR训练方式,正样本尺寸,弱分类器数量及特征参数,揭示了数据文件如何影响应用效率。
本文详细解析了OpenCV中基于Harr的训练数据结构,包括AdaBoost和HAAR训练方式,正样本尺寸,弱分类器数量及特征参数,揭示了数据文件如何影响应用效率。
OpenCv中有一些自带的已经训练好的数据,那么接下来大致的对部分数据信息进行讲解。
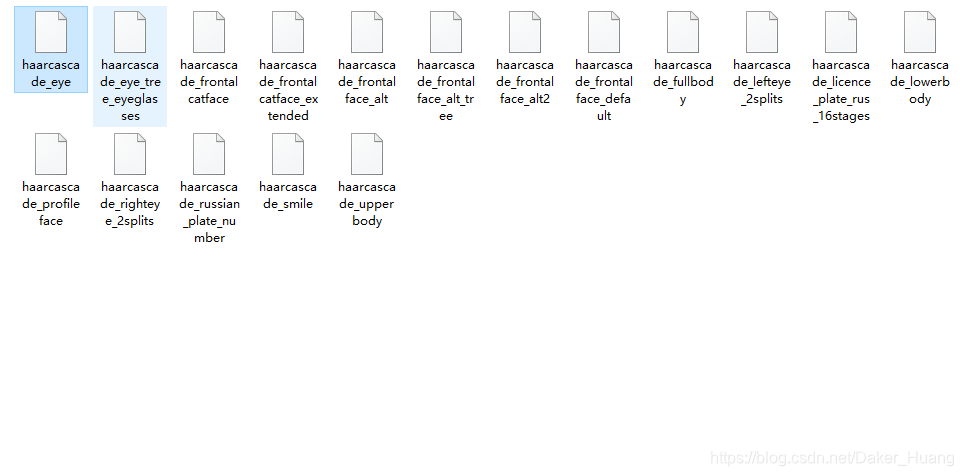
上图是基于Harr的训练数据,我在VS2017中打开一个文件,比如第一个文件:haarcascade_eye.xml。
先来看看第45-49行:

PS:第一眼看到这种结构我觉得跟Html有点像。
46:BOOST表示分类器是基于AdaBoost的结构进行训练的。
47:HAAR则是基于HAAR的方式进行训练的。
48-49:表示正样本的大小是Size(20,20)
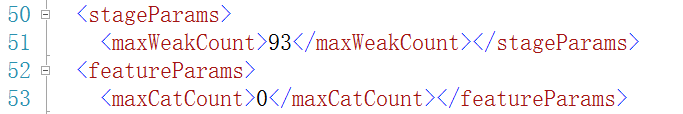
51:一个参数,属于stage的参数,总共用了弱分类器的个数为93个(级联分类器由多个强分类器组成,一个强分类器由多个弱分类器组成)。
52:一个参数,属于feature的参数
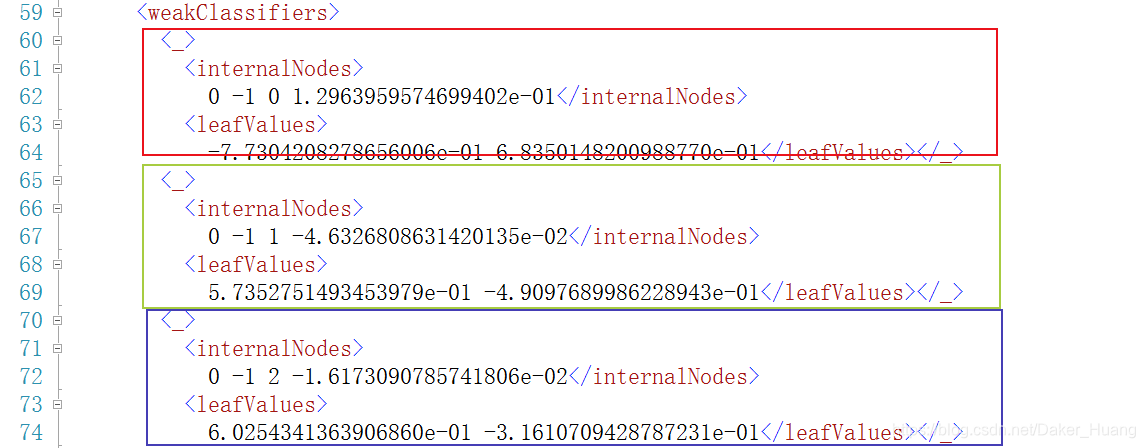
59-:每个圈出来的矩形框代表一个弱分类器。
后面很多都是:

越往后 X中的X值应该是越大的。
一直往下滑,弱分类器滑到了5000多行才结束:
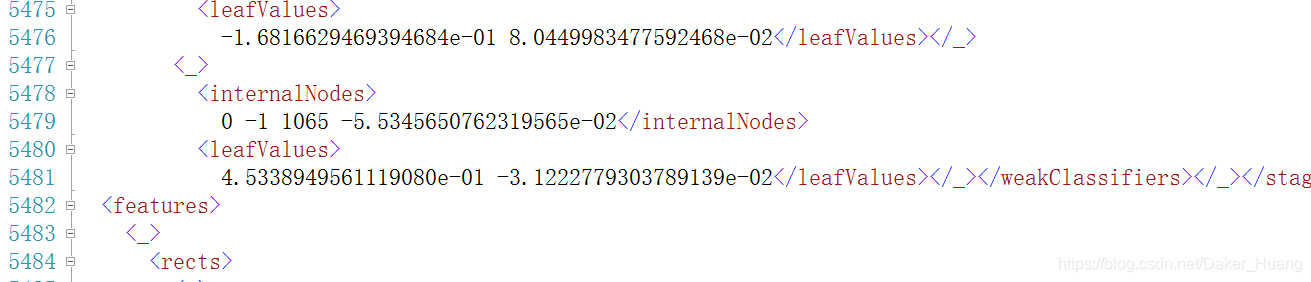
上面的特征通过SVM(支持向量机)来进行分类,我们就得到了下面的矩形数据:

5486:这里面的数据应该是权重,具体还要看代码中的要求。
一直拉到底都是矩形数据:

以上就是数据部分的讲解,由此我们可以大致上来判断自己训练的数据是不是正确且合法的。
其实有些文件中的数据可以去掉,这样我们的数据文件会小很多,做应用时效率会更高,像这些数据就可以去掉:

去掉之后(比如只保留4位小数),相信运行效率一定会大幅度上升。

















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









