




论文来源:arxiv 202306
论文地址:2306.04136.pdf (arxiv.org)
论文代码:未公布
Baek J, Aji A F, Saffari A. Knowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering[J]. arXiv preprint arXiv:2306.04136, 2023.
Abstract
LLM能够根据其在预训练过程中存储在参数中的内部知识进行零样本闭卷问答任务,但是这种内部知识可能是不正确的和过时的,导致LLM生成事实上错误的答案,此外,对LLM进行微调来更新其中的知识是昂贵的。为此,本文直接在LLM的输入中增加知识。具体来说,首先根据问题及相关事实之间的语义相似性从知识图谱中检索与输入问题相关的事实;然后,将检索到的事实以提示的形式与输入问题融合,并输入到LLM中,生成答案。KAPING框架不需要重新进行模型训练,因此可以适用于零样本场景。本文在KGQA任务上验证了KAPING框架的性能。
Introduction
尽管从KG中检索相关事实三元组作为提示输入到LLM中生成答案的方法看起来简单有效,但是会存在以下几个挑战:
① 大多数检索到的与问题实体相关的三元组都与回答给定的问题无关,这可能会误导模型产生错误的答案;
② 问题实体的三元组数量偶尔会很大,因此,对包括不必要的三元组在内的所有三元组进行编码会产生很高的计算成本,尤其是LLM。
为了克服上述挑战,本文基于与输入问题的语义相似性,过滤掉不必要的三元组。具体来说,首先在嵌入空间中表示问题及其相关的三元组;然后,检索少量与输入问题更相近的三元组。这样,可以在给定问题中添加更相关的三元组,以有效防止LLM以高计算效率生成不相关答案。值得注意的是,本文所采用的过滤方法是现成的句子嵌入模型,因此,模型的各个部分都不需要额外的训练。
Method
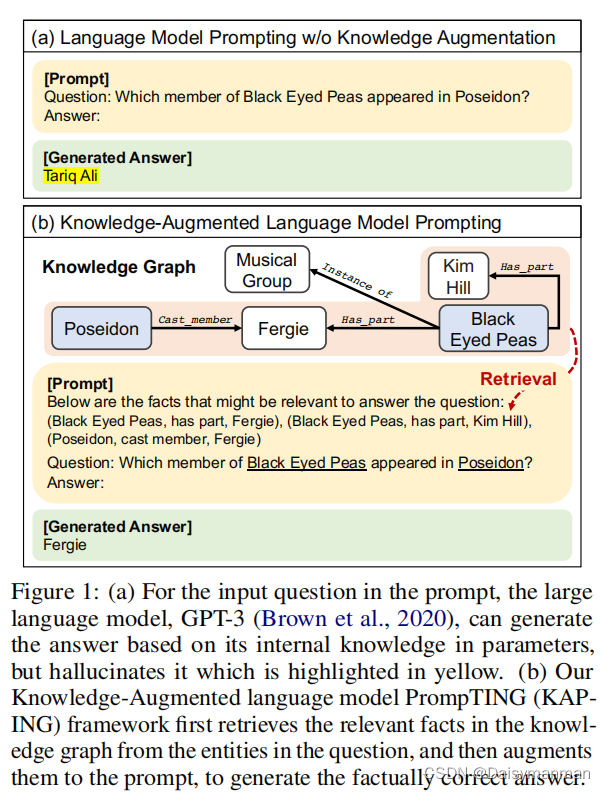
Knowledge-Augmented LM Prompting
Knowledge Access
首先提取问题中的实体,然后基于提取的实体,在KG中找到相应的实体(现有的实体链接技术),然后其事件三元组成为与输入问题相关的事实。
Knowledge Verbalization
在将KG中的符号事实输入到LLM之前,首先需要将三元组转化为文本字符串。在本文中,采用将三元组中的头实体、关系和尾实体进行拼接的方式。
Knowledge Inject
首先,枚举N个语言化的三元组,然后,在提示的顶部添加具体的指令:“Below are facts in the form of the triple meaningful to answer the question.”,之后,知识提示将加在问题提示之前,由知识和问题提示为条件的LLM将依次生成答案。
Question-Relevant Knowledge Retrieval
Knowledge Retriever
对于语言化的三元组和问题,我们首先将他们嵌入到现成的句子嵌入模型得表示空间中,进行文本检索,然后计算他们的相似性,之后使用前K个相似的三元组。

















 691
691



 到【灌水乐园】发言
到【灌水乐园】发言








