






原文链接 What Is Change Data Capture (CDC)? | Confluent
目录
Change Data Capture and Apache Kafka
CDC简介
更改数据捕获【Change data capture】(CDC)是指跟踪数据源(如数据库和数据仓库)中所有更改的过程,以便在目标系统中捕获这些更改。
事务日志( transaction logs)和数据库触发器(database triggers)等CDC方法允许组织跨多个系统和部署环境实现数据完整性和一致性。
此外,它们允许组织通过将数据从遗留数据库(legacy databases)移动到专门构建(purpose-built)的数据平台(如文档或搜索数据库或数据仓库)来为正确的工作使用正确的工具。
数据不断变化,这可能导致数据库、数据湖和数据仓库不同步。此外,组织越来越多地迁移到云,这增加了数据孤岛的可能性。CDC已经成为连接本地和云环境( bridge on-premises and cloud environments)的流行解决方案,允许企业按照自己的节奏迁移到云,或者继续在混合环境中运行。
为什么需要CDC?
最初,CDC作为批处理数据复制(batch data replication)的替代解决方案流行起来,用于为Extract Transform Load (ETL)作业填充数据仓库。近年来,CDC已经成为迁移到云的实际方法。
益处
消除批量加载更新(Eliminates Bulk Load Updates):
CDC支持增量加载或数据更改的实时流到目标存储库。不需要批量加载更新和不方便的批处理窗口。
基于日志的效率(Log-Based Efficiency):
基于日志的CDC通过直接从事务日志(transaction logs)中捕获更改来最小化对源系统的影响。这样可以减少系统资源的使用并维护源系统的性能。
零停机迁移(Zero-Downtime Migrations):
CDC促进的实时数据移动支持零停机数据库迁移。它确保了实时分析和报告的最新数据可用性。
跨系统同步:(Synchronization Across Systems)
CDC保持多个系统中的数据同步,这对于高速数据环境中时间敏感的决策至关重要。
针对云和流处理进行了优化(Optimized for Cloud and Stream Processing):
CDC有效地跨广域网移动数据,使其成为云部署的理想选择,并将数据与Apache Kafka等流处理解决方案集成。
CDC工作流程
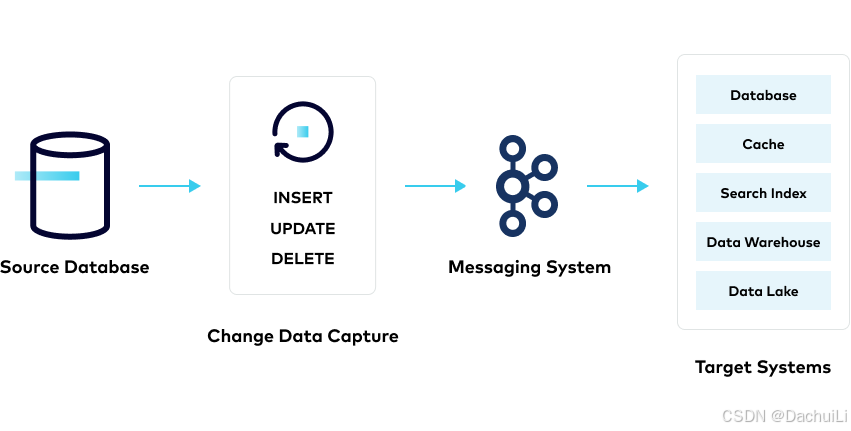
当通过INSERT、UPDATE或DELETE在源数据库(通常是关系数据库,如MySQL、Microsoft SQL、Oracle或postgresql)中更改数据时,需要将其传播到下游系统,如缓存、搜索索引、数据仓库和数据湖。更改数据捕获(CDC)跟踪源数据集中的更改,并将这些更改传输到目标数据集。
传统上,团队使用批处理(batch processing)来同步数据,这意味着数据不能立即同步,生产数据库在分配资源时速度变慢,数据复制只在指定的批处理窗口期间发生。CDC确保实时同步更改,从而消除了与传统批处理相关的延迟。CDC持续跟踪变化并立即更新目标数据库,确保数据始终是最新的。
CDC通常使用两种主要方法实现:
推和拉(push and pull):源数据库将更新推送到下游服务和应用程序,或者下游服务和应用程序以固定的间隔轮询(poll)源数据库以提取更新的数据。每种方法都有自己的优点和缺点。在您自己的用例上下文中考虑所有这些方面是很重要的。
Push vs. Pull
Push:在这种方法中,源数据库完成了繁重的工作。它捕获数据库中的更改,并将这些更新发送到目标系统,以便它们能够采取适当的操作。
该方法的优点是目标系统可以近乎实时地更新最新数据。但是,如果目标系统不可访问或脱机,则更改的数据可能会丢失。
为了减轻这些风险,通常在源系统和目标系统之间实现消息传递系统,以缓冲更改,直到它们可以提交到最终目的地。
Pull:在此方法中,源数据库的任务比push方法轻。源数据库不主动发送更新,而是记录每个表上特定列中的数据更改。目标系统有责任不断地轮询源数据库以检索更改并对其采取正确的操作。
与推送方法一样,在源系统和目标系统之间需要一个消息传递系统,以确保在目标系统不可用时不会丢失更改的数据。
拉式方法的缺点是,如果数据发生变化,目标系统不会立即得到通知。由于更改是在拉取请求之间批处理的,因此在目标系统了解这些更改之前存在延迟。
如果您的应用程序需要实时数据,您应该使用push方法:它可以确保更改的即时传播。但是,它需要健壮的消息传递系统来处理目标系统的潜在停机时间。
如果您希望持续传输大量数据,并且您的应用程序不需要实时数据,则应该选择pull方法。但是,由于批处理,会有延迟。
CDC模式和方法
CDC使用不同的方法检测数据的变化。以下是最常用的方法:
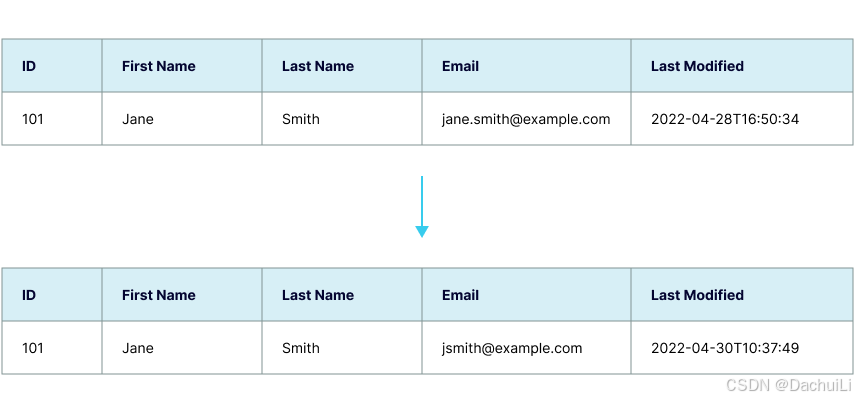
基于时间戳的(Timestamp-based):
最近的更改。该列可以称为LAST_MODIFIED、LAST_UPDATED等。下游应用程序或系统可以查询此字段并获取自上次执行时间以来已更新的记录。
优点:
使用和实现起来简单。
提供一种直接的方法来跟踪随时间变化的情况。
缺点:
只能处理软删除,不能处理DELETE操作。
增加了源系统的计算开销,因为目标系统必须扫描表中的每一行来识别最后更新的值。
要求对现有数据库模式进行更改。
示例显示了创建新记录时对表的快照,以及更新ID=101的记录时对表的快照。
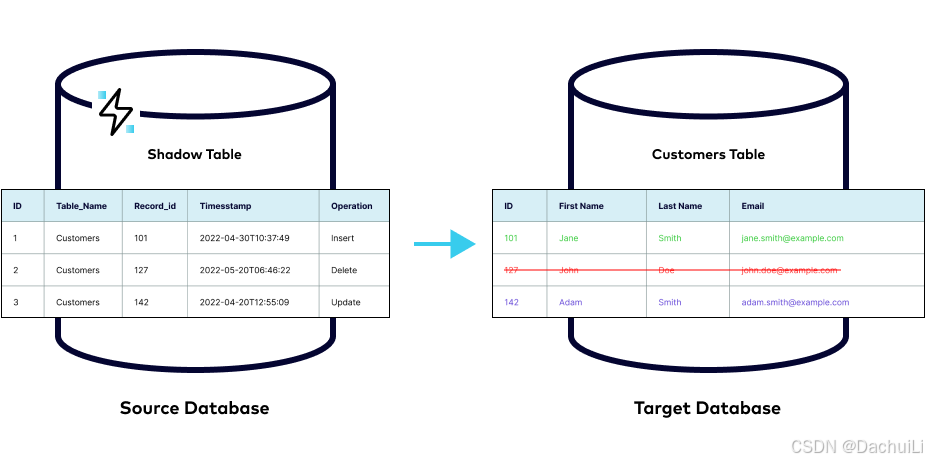
基于触发器的(Trigger-based):
大多数数据库支持触发器(trigger functions)。这些存储过程是在表上发生特定事件(例如INSERT、UPDATE或DELETE记录)时自动执行的。每个表的每个操作都需要一个触发器来捕获任何数据更改。这些数据更改存储在同一数据库中的单独表(通常称为“影子表”【“shadow table”】或“事件表”【“event table”】)中。此外,开发人员还可以包括消息传递系统,以便将这些数据更改发布到队列中,相关的目标系统将在队列中订阅这些更改。
优点:
能够检测和捕获对记录的所有类型的更改(INSERT、UPDATE和DELETE)。
触发器被广泛使用,并且被大多数数据库所支持。
启用无需轮询的实时数据捕获。
缺点:
对源数据库性能有负面影响,因为更新记录需要多次写操作。
要求对源数据库模式进行更改。
如果有大量的触发器,管理起来会变得很复杂。
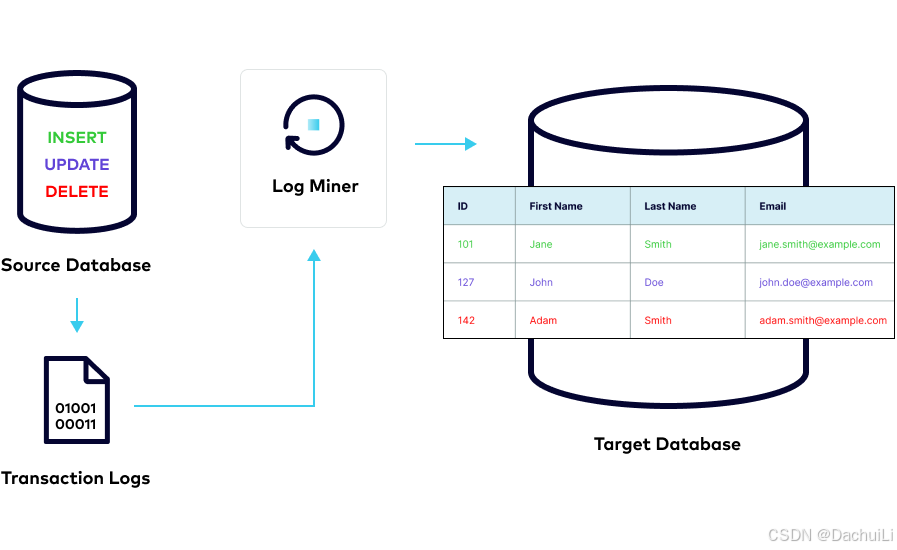
基于日志的:(Log-based: )
事务数据库将针对数据库提交的所有更改(INSERT、UPDATE和DELETE)及其相应的时间戳记录到称为事务日志的文件中(transaction logs)。这些日志主要用于备份和灾难恢复目的,但它们也可用于将更改传播到目标系统。实时捕获数据更改。由于目标系统可以从事务日志中读取,因此该方法不会对源数据库造成计算开销。
优点:
不会增加源数据库的计算开销。
能够检测和捕获对记录的所有类型的更改(INSERT、UPDATE和DELETE)。
不需要更改源数据库的模式。
缺点:
事务日志的格式没有标准化。这意味着每个供应商选择实现他们自己的方法,这可能在未来的版本中发生变化。
目标系统必须识别并消除写入源数据库但随后回滚的任何更改。
CDC用例
变更数据捕获(CDC)用于现代数据集成系统,以确保合规性并启用实时分析。通过持续捕获和复制数据变化,CDC支持无缝数据迁移、与微服务集成和云采用。
CDC有很多用例。让我们回顾下面的几个例子。
连续数据复制(Continuous Data Replication)
在以批处理模式将整个源数据库复制到目标系统时,源数据库不能接受新的写入,包括模式更改(schema changes),直到该过程完成。复制过程越长,延迟对源代码进行重要更改的风险就越大。在将更改传递给目标时,进一步延迟的可能性也更大。
这两种情况都是不可接受的,因为消费者需要现代应用程序的实时体验。CDC通过不断地将更改的数据(整个数据库的一个子集)复制到下游消费者来解决这些挑战。
与微服务架构的集成(Integration with Microservices Architecture)
随着组织继续打破他们的单片架构(monolithic architectures) 并采用微服务,他们需要从源数据库传输数据,并可能将其定向到多个目标系统。由于这些转换需要时间,因此CDC可用于在此过程中保持源数据存储和目标数据存储同步。
云采用(Cloud Adoption)
组织越来越多地迁移到云,以降低TCO,提高敏捷性和弹性。通过利用云原生服务,公司可以专注于构建新的数字体验,而不是花费时间和资源来配置、维护和管理数据库和基础设施。
CDC支持这种迁移,并确保数据在本地和云环境中保持一致和最新。这种无缝的数据集成可帮助企业在不中断的情况下充分利用云功能。
Change Data Capture and Apache Kafka
CDC允许您捕获源数据库中的数据更改,但是您仍然需要将这些更改通信并传播到下游系统。这就是Apache Kafka and Kafka Connect 的亮点所在。
Apache Kafka是一个开源的事件流平台,可以持久地编写和存储streams of events,并实时或回顾性地(retrospectively)处理它们。Kafka是一个分布式的服务器和客户端系统,提供可靠和可扩展的性能。
Kafka Connect API是Apache Kafka的核心组件,在0.9版本中引入。Kafka Connect为Kafka与其他系统提供了可扩展和弹性的集成,既可以发送数据,也可以从它们接收数据。Kafka Connect是配置驱动的(configuration-driven),这意味着你不需要编写任何代码来使用它。它完全由配置文件驱动,并为开发人员提供了一个简单的集成点。
Kafka Connect的一个流行用例是数据库更改数据捕获。您可以利用Confluent的JDBC或Debezium CDC连接器将Kafka与数据库集成,并轻松地将数据流式传输到Confluent中。
JDBC连接器根据更新时间戳列轮询源数据库以查找新的或更改的数据。Confluent Cloud为Microsoft SQL Server、PostgreSQL、MySQL和Oracle提供完全托管的源连接器。
此外,Confluent还为Microsoft SQL Server、PostgreSQL、MySQL和Oracle提供基于日志的CDC源连接器。这些连接器在启动时获取现有数据的快照,然后监视并记录所有后续的行级更改。

















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









