



L1G4000 InternLM + LlamaIndex RAG 实践
基础任务
基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 浦语 API 不会回答,借助 LlamaIndex 后 浦语 API 具备回答 A 的能力。
配置相关环境
conda create -n llamaindex python=3.10
conda activate llamaindex
# 安装python依赖包
pip install einops==0.7.0 protobuf==5.26.1
# 安装Llamaindex
pip install llama-index==0.11.20
pip install llama-index-llms-replicate==0.3.0
pip install llama-index-llms-openai-like==0.2.0
pip install llama-index-embeddings-huggingface==0.3.1
pip install llama-index-embeddings-instructor==0.2.1
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu121
下载Sentence Transformer模型
cd ~
mkdir llamaindex_demo
mkdir model
cd ~/llamaindex_demo
touch download_hf.py
cd /root/llamaindex_demo
conda activate llamaindex
python download_hf.py
下载NLTK相关资源
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
可以看到已经下载成功。
是否使用Llamaindex前后对比
未使用Llamaindex RAG
模型对于问题的问答是不对的
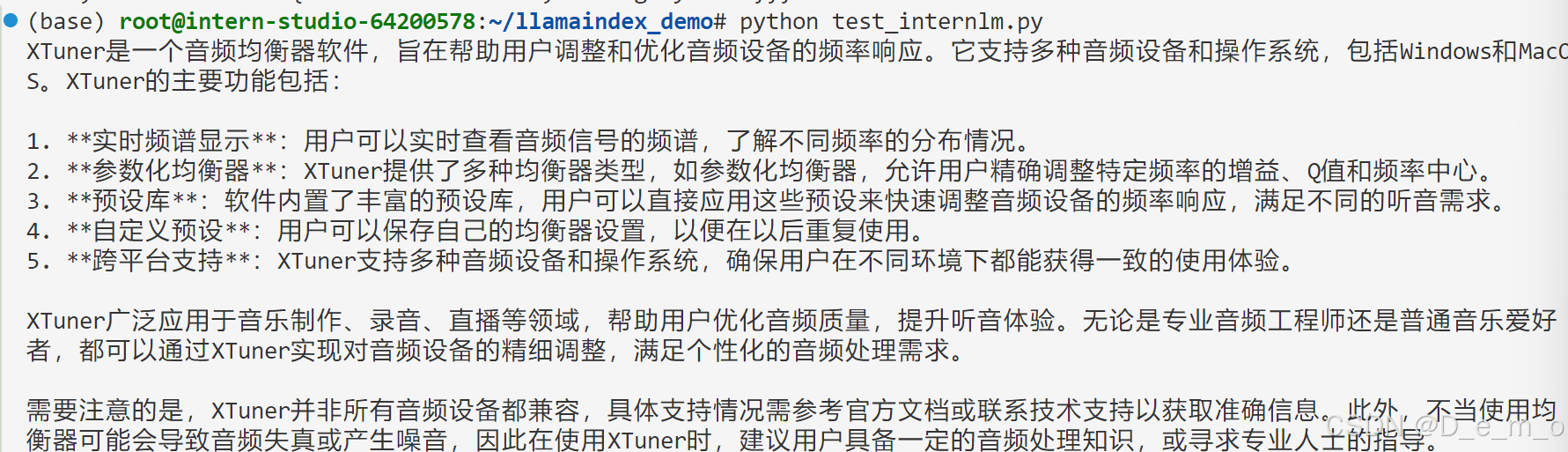
使用API+Llamaindex
可以看到模型正确读取了新的知识,在没有更改模型权重的情况下,模型的输出有了更加好的正确性。

在配置环境过程中,教程中用到的是cuda12.0镜像,不过创建开发机只有cuda12.2和11.7镜像,这里的不一致,似乎在安装Llamaindex和相关的包一步时出现版本不一致的问题,出现重复安装确认版本、卸载重新安装。耗时较长。

















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









