




 AC自动机是一种用于字符串搜索的算法,尤其适用于大量敏感词在长文本中的匹配。通过构建前缀树并设置fail指针,可以在遍历文本一次的情况下找出所有匹配的敏感词,避免了传统方法中的多次回溯,提高了效率。文章详细介绍了AC自动机的构建过程和匹配机制。
AC自动机是一种用于字符串搜索的算法,尤其适用于大量敏感词在长文本中的匹配。通过构建前缀树并设置fail指针,可以在遍历文本一次的情况下找出所有匹配的敏感词,避免了传统方法中的多次回溯,提高了效率。文章详细介绍了AC自动机的构建过程和匹配机制。
AC自动机
该模型应用场景是什么样的?假如有一篇很长的文章,然后有一个敏感词表单,请从这篇文章里找出包含了哪些敏感词。即便是用KMP进行快速匹配,那也只能每次遍历整篇文章才能找到一种敏感词,KMP只适用于单一子串匹配,并且原串不能太大。AC自动机可以做到只需要遍历一遍就可以找到文章里包含的所有表单中的词。AC自动机利用了前缀树结构设计了一种不回退技巧,使得多匹配变得十分高效。
在下面的流程中,大家肯定会疑惑,为什么要这么设置呢? 对于这样的疑惑一点也不奇怪,因为我刚开始时也是一脸雾水。但是这不影响理解,大家姑且先别管为什么这么做,先把流程熟悉了之后再去理解为什么要这么做。
前缀树结构
和经典前缀树几乎一模一样,只是多了一些属性来帮助完成不回退。前缀树是给敏感词用的,每一个敏感词都需要将其插入到前缀树中。
public static class Node{
// 如果一个node的end为null,说明该结点不是任意一个字符串的结尾,或者是已经收集过答案的敏感词,
// 我们不需要再重复收集了,所以将它设置为null
// 如果end不为空,表示这个点是某个敏感词的结尾,end的值就是这个字符串,并且该敏感词还没收集过
// 所以,非字符串结尾的结点的end也都是为null
public String end;
// 只有在上面的end变量不为空的时候,logged才有意义。logged表示这个字符串之前有没有加入过答案
// 因为一篇大文章里,同一个敏感词可能出现的次数不止1次,所以避免重复收集
public boolean logged;
// 这个fail域是最重要的属性,用它来帮助完成不回退。具体怎么设置下面会讲
public Node fail;
public Node[] nexts; // 这里默认所有都是由小写英文字母组成的字符串,a-->0 b-->1 z-->25
public Node() {
logged = false;
end = null;
fail = null;
nexts = new Node[26];
}
}
我们采取的策略是先统一把所有敏感词插入到前缀树中,然后再利用宽度优先遍历一层一层地设置每个结点的 fail . 接下来用实例来讲解该过程。
设置fail指针域
假设给的敏感词列表是 ["bcde", "abcde", "de", "cde"] 那么建立好的前缀树如下图所示(实线是next域,虚线是fail域)
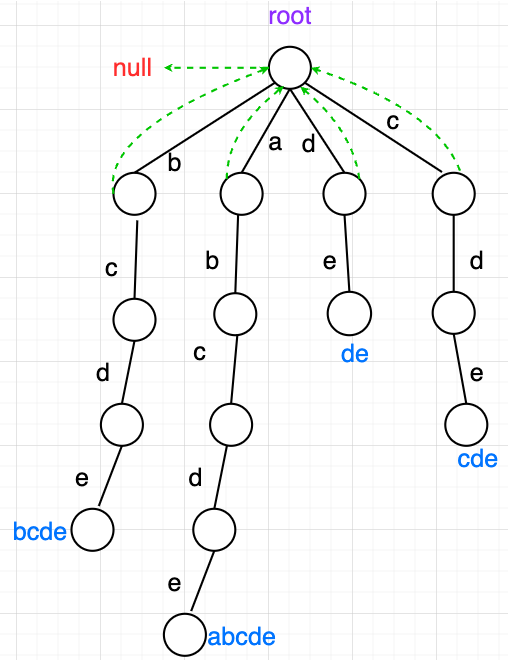
规定:根结点的fail指向null,根结点的直接后继结点的fail指向根。也就是说第1层和第2层的fail都设置好了,接下来就是一层一层设置了。
- 当我们来到第一条链的C结点时,我们需要看他的父结点的fail指针指向的结点是否有自己的这条路。C的父结点是通过C这条路来到C的,所以C看父结点的fail指向root,便问root是否也有C的路,一看发现有,于是C的fail就指向了第4条链的第一个结点C。如果父结点的fail指向的结点没有去C的路,那就继续从父结点的fail指向的结点再顺着fail跳一步,如果都来到了根结点还没找到的话,那么C的fail就指向根。
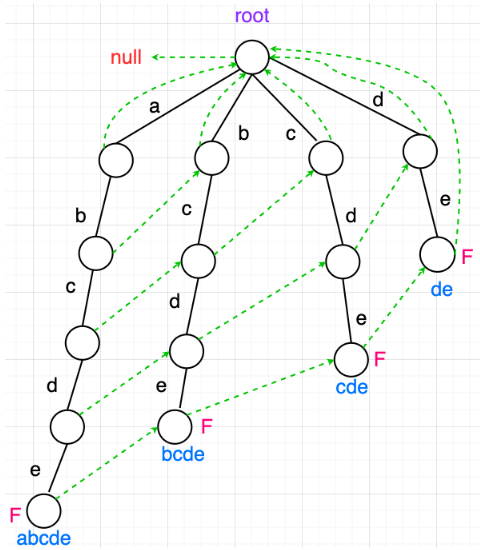
这就是设置fail指针的所有规则了,下面的图是设置好所有的fail指针后对位置稍微调整后的状态,因为不调整的话线条有点乱。蓝色内容就是每个结尾处字符记录的完整字符串,其余中间结点是没有的。F就表示当前敏感词是否被收集过,因为一开始都没收集过,所以都是false
下面是给整棵前缀树设置fail域的代码
public void build(){
Queue<Node> queue = new LinkedList<>();
queue.add(root);
Node cur = null;
Node cFail = null;
while (!queue.isEmpty()){
// 弹出某个结点,我们要处理的是它所有的孩子 我们没办法做到自己给自己设置fail,
// 因为需要依靠父结点,而在层次遍历中,来到cur时,cur的父结点早就出队列了。所以我们只能
// 通过cur为其孩子设置fail
cur = queue.poll();
for (int i = 0; i < 26; i++) { // 排查所有孩子
if (cur.nexts[i] != null){ // 如果有i号儿子
// 我们采用的逻辑是:先全部指向root,再单独处理那些有其他指向的
cur.nexts[i].fail = root;
cFail = cur.fail;
// 根结点的孩子是不会执行该循环的,因为在第二层时,cur就是根,根的fail==null
while (cFail != null){ // 顺着fail循环一周去寻找 ==null 说明已经来到根结点的fail
if (cFail.nexts[i] != null){
cur.nexts[i].fail = cFail.nexts[i];
break;
}
cFail = cFail.fail;
}
queue.add(cur.nexts[i]);
}
}
}
}
至此,整棵前缀树才彻底完成,接下来就是用给定的大文章在这棵前缀树上玩匹配了,接下来的流程才体现了AC自动机的绝妙之处!!!!
多匹配
假设给的大文章是
abcde一开始cur指向前缀树根结点
- 每次遍历一个字符,我们要做的第一步就是安置好cur的去向,让cur去到了该去的位置后,第二步才是收集答案。所以现在第一步我们先安排cur的去向。我们发现cur有去往
a的路,于是cur就往下跳到了a,完成了cur的设置,因为这里直接有路,所以就设置比较方便,当没路的时候cur的设置就有点麻烦了。 - cur跳好了,
现在开始收集答案,这是整个模型最重要的机制!!!用一个follow复刻此时cur的指向,然后让follow顺着cur的fail域所连接的链绕一圈,直到到了root才停止,在沿途一圈收集答案,cur的位置依然保持在原位。 但此时follow很轻易就跳到了root,根本没有答案。 - 遍历到大文章的1位置的字符b,cur此时在前缀树第一条链的a结点上,此时有去往b的路,然后跳到b,收集答案,也没收集到…
- 直接让cur加速来到d吧,因为上面都收集不到答案,所以略过。此时大文章的字符是e,而cur有去往e的路,于是来到了e,此时让follow==cur去收集答案,发现此时姐弟的logged域为False,并且其end域有内容,于是将
abcde这个答案收集,并且将该结点的logged域设为True,然后follow顺着fail来到了第二条链的e结点,并且同意符合可以收集答案的条件,于是将bcde这个答案收集,并且将该结点的logged域设为True;再次顺着fail来到了第三条链的e结点,于是将cde这个答案收集,并且将该结点的logged域设为True;再次顺着fail来到了第四条链的e结点,于是将de这个答案收集,并且将该结点的logged域设为True;再次顺着fail来到root,至此循环结束。
有没有发现,我们只是遍历到了大文章的e位置,就将里面可能包含的所有敏感词全部找出来了,而且我们甚至都没有回退,根本不需要从头再遍历!!!而且如果大文章后面还有字符,那么cur就会沿着自己的位置继续遍历,这里需要注意,收集答案的时候cur是原地不动的。
再举一个例子,来充分体现AC自动机的机制。假设大文章是 abcdtbce
abcd就不讨论了,cur已经来到了第一条链的d结点,遍历下一个字符是t,而cur没有去t的路,所以我们沿着fail指针来寻找cur的去向,注意,此时还是处于给cur寻找位置的阶段,还没到收集答案的时候。一定要记住,只有让cur跳完了,才能收集答案!!! cur此时来到了第二条链的d结点,发现它也没有去往t的结点,于是又顺着这个d的fail来到了第三条链的d结点,也没有去t的路,于是来到了第四条链的d结点,也没有,于是顺着fail来到了根结点root,至此宣告了:cur一开始从根结点到此时的根结点所对应的大文章的这批字符对所有的敏感词匹配的彻底失败,也就是说abcdt匹配不出任何敏感词,才致使cur又重回到了根,是不是很奇妙,因为cur又可以重新匹配接下来的字符串了,并且是以开头的位置来匹配。
现在大家是不是对fail指针有一点感觉了。其实fail指针顾名思义就是,当匹配失败时应该走的路。回想一下,当我们用大文章匹配敏感词,匹配成功了若干个字符后,突然某个字符匹配不上了,这时候我们应该怎么做?是让遍历前缀树的指针重新回到根结点继续匹配吗?如果这样的话,那就是说我们彻底放弃了前面那些匹配成功的字符里是否包含其他敏感词的可能性,而是从失败的字符开始重新匹配,虽然失败了,但是只能说明匹配某个敏感词失败了,而不能说明匹配所有的敏感词失败了。
就像abcdt.....去匹配 abcde 这个敏感词时,来到t失败了,这只能说明匹配这个敏感词失败了,但是万一前面成功的字符还包含其他敏感词呢?如果此时让指针重新回到了前缀树根,那就是说我们放弃了以b、c、d开头去匹配敏感词的可能性。所以fail指针就是告诉你,我们不可以这么冲动地舍弃这么多可能性,而是尽可能地小心地舍弃可能性。 就像在树中那样,如果t失败了,指针会来到第二条链的d结点,因为bcd和abcd的共同后缀最长,这样我们就只舍弃了以a开头的可能性,并且在寻找以b开头的可能性,
下面是AC自动机的多匹配代码
public List<String> involvedWords(String content){
char[] chars = content.toCharArray();
Node cur = root;
Node follow = null;
int path = 0;
List<String> res = new ArrayList<>();
for (char c : chars) {
// 虚线包围的代码其实就是给cur寻找要跳的位置,等cur跳好了之后,就让follow绕一圈收集答案。
// -------------------------------------------------------------------------------
path = c - 'a';
// 如果当前字符在这条路上没配出来,就随着fail方向走向下条路径
// 为啥要加一个cur != root 因为cur==root时再往fail走就到null了,我们的意思是最后最差也是回到根重新配
while (cur.nexts[path] == null && cur != root)
cur = cur.fail;
// 跳出while时有两种可能
cur = cur.nexts[path] == null ? root : cur.nexts[path];
// 到这里时,cur就有两种情形:
// 1) 现在来到的路径,是可以继续匹配的
// 2) 现在来到的节点,就是前缀树的根节点
// -------------------------------------------------------------------------------
follow = cur;
while (follow != root) { // 如果是第2种情形,那么该while不会执行,不影响后续
if (follow.logged) // 如果已经加过,直接跳出,因为后续的循环肯定也走过
break;
if (follow.end != null) {
res.add(follow.end);
follow.logged = true;
}
follow = follow.fail;
}
}
return res;
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









