









一直一来我都浅显的认为指针是一个地址,指向了一块内存区域,但是最近突然想到几个问题:
1 malloc申请内存的时候传入和内存的大小参数,但是调用free释放内存的时候并没有传入内存快的大小,操作系统是如何知道要释放多大的内存呢。
2 delete和delete[]的区别,两个最终的调用都是调用free释放内存,free函数并没有内存大小参数只有内存地址,按照这个来分析delete和delete[]其实释放的内存大小是一样的。
3 我们通过指针修改内存时,从写内存到内存发生变化具体流程是什么
1第一个问题
需要从glibc的源码中找答案,malloc世界上调用了malloc_internal
void *
malloc (size_t size)
{
lock ();
void *result = malloc_internal (size);
unlock ();
return result;
}struct __attribute__ ((aligned (__alignof__ (max_align_t)))) allocation_header
{
size_t allocation_index;
size_t allocation_size;
};
/* Array of known allocations, to track invalid frees. */
enum { max_allocations = 65536 };
static struct allocation_header *allocations[max_allocations];
static size_t allocation_index;
static size_t deallocation_count;
static void *malloc_internal (size_t size)
{
if (allocation_index == max_allocations)
{
errno = ENOMEM;
return NULL;
}
size_t allocation_size = size + sizeof (struct allocation_header);
if (allocation_size < size)
{
errno = ENOMEM;
return NULL;
}
size_t index = allocation_index++;
void *result = mmap (NULL, allocation_size, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (result == MAP_FAILED)
return NULL;
allocations[index] = result;
*allocations[index] = (struct allocation_header)
{
.allocation_index = index,
.allocation_size = allocation_size
};
return allocations[index] + 1;
}我们可以看到实际上我们申请内存的时候实际上申请了size + sizeof (struct allocation_header)大小的内存,比我们申请的要大一点,用来保存内存快的信息(内存块的索引+内存块的大小),可以看到函数的返回值:return allocations[index] + 1,返回的地址只是把头部跳过,返回给我们可用的内存地址的位置了。
重点看free函数
static struct allocation_header *get_header (const char *op, void *ptr)
{
struct allocation_header *header = ((struct allocation_header *) ptr) - 1;
if (header->allocation_index >= allocation_index)
fail ("%s: %p: invalid allocation index: %zu (not less than %zu)",
op, ptr, header->allocation_index, allocation_index);
if (allocations[header->allocation_index] != header)
fail ("%s: %p: allocation pointer does not point to header, but %p",
op, ptr, allocations[header->allocation_index]);
return header;
}
void free (void *ptr)
{
if (ptr == NULL)
return;
lock ();
struct allocation_header *header = get_header ("free", ptr);
free_internal ("free", header);
unlock ();
}
static void free_internal (const char *op, struct allocation_header *header)
{
size_t index = header->allocation_index;
int result = mprotect (header, header->allocation_size, PROT_NONE);
if (result != 0)
fail ("%s: mprotect (%p, %zu): %m", op, header, header->allocation_size);
/* Catch double-free issues. */
allocations[index] = NULL;
++deallocation_count;
}
答案揭晓了,当我们调用free的时候,会把指针会退到内存块真正的头部,取出头部信息,获取内存块的长度,然后回收内存。还有一个非常有意思的东西可以看到,调用malloc的时候通过mmap在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。当我们调用free的时候内存并没有真正释放,只是把内存块的读写权限设置成了不可读不可写(此时如果我们再次访问这块内存区域系统就会抛出SIGEGV信号),并没有调用munmap返还内存。这么做的原因是方便cpu可以重用这块内存,提高频繁内存申请的效率。
因为进程向OS申请和释放地址空间的接口 sbrk/mmap/munmap 都是系统调用,频繁调用系统调用都比较消耗系统资源的。并且, mmap 申请的内存被 munmap 后,重新申请会产生更多的缺页中断。例如使用 mmap分配 1 M 空间,第一次调用产生了大量缺页中断 ( 1 M/ 4 K 次 ) ,当munmap 后再次分配 1 M 空间,会再次产生大量缺页中断缺页中断是内核行为,会导致内核态CPU消耗较大。另外,如果使用 mmap 分配小内存,会导致地址空间的分片更多,内核的管理负担更大。同时堆是一个连续空间,并且堆内碎片由于没有归还 OS ,如果可重用碎片,再次访问该内存很可能不需产生任何系统调用和缺页中断,这将大大降低 CPU 的消耗。因此, glibc 的 malloc 实现中,充分考虑了 sbrk 和 mmap 行为上的差异及优缺点,默认分配大块内存 ( 128 k) 才使用 mmap 获得地址空间,也可通过 mallopt(M_MMAP_THRESHOLD, <SIZE>) 来修改这个临界值。
2第二个问题
// Created by 杜国超 on 21/12/25.
// Copyright © 2019年 杜国超. All rights reserved.
//
#include <iostream>
#include <stdlib.h>
#include <cstdio>
class Master
{
public:
Master()
{
printf("Master() \n");
}
~Master()
{
printf("~Master() \n");
}
};
int main()
{
printf("===================\n");
Master* p = new Master[3];
delete[] p;
p = 0;
printf("===================\n");
int* pint = new int[10];
delete pint;
printf("===================\n");
Master* pp = new Master[3];
delete pp;
printf("===================\n");
}运行结果
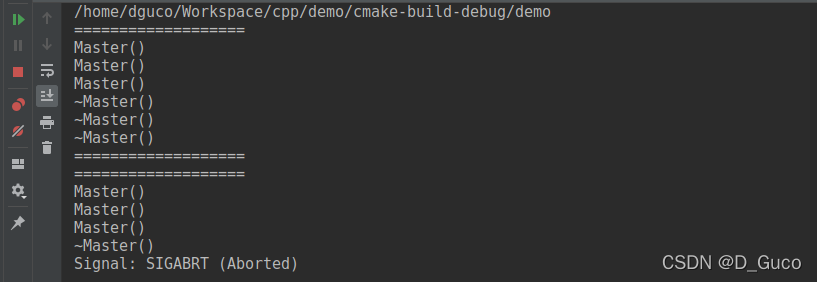
报错堆栈信息

关于这个报错估计跟glibc的版本有关系,报错部分的代码如下
static void
munmap_chunk (mchunkptr p)
{
size_t pagesize = GLRO (dl_pagesize);
INTERNAL_SIZE_T size = chunksize (p);
assert (chunk_is_mmapped (p));
/* Do nothing if the chunk is a faked mmapped chunk in the dumped
main arena. We never free this memory. */
if (DUMPED_MAIN_ARENA_CHUNK (p))
return;
uintptr_t mem = (uintptr_t) chunk2mem (p);
uintptr_t block = (uintptr_t) p - prev_size (p);
size_t total_size = prev_size (p) + size;
/* Unfortunately we have to do the compilers job by hand here. Normally
we would test BLOCK and TOTAL-SIZE separately for compliance with the
page size. But gcc does not recognize the optimization possibility
(in the moment at least) so we combine the two values into one before
the bit test. */
if (__glibc_unlikely ((block | total_size) & (pagesize - 1)) != 0
|| __glibc_unlikely (!powerof2 (mem & (pagesize - 1))))
malloc_printerr ("munmap_chunk(): invalid pointer");
atomic_decrement (&mp_.n_mmaps);
atomic_add (&mp_.mmapped_mem, -total_size);
/* If munmap failed the process virtual memory address space is in a
bad shape. Just leave the block hanging around, the process will
terminate shortly anyway since not much can be done. */
__munmap ((char *) block, total_size);
}malloc_printerr ("munmap_chunk(): invalid pointer");这一句导致了报错,在低版本的glibc的版本中是没有这个判断的,有可能在低版本的glibc环境下是可以运行成功的(网上也的确有的人运行不会报错,是否成功跟自己的系统和glibc版本有关系)。不过看输出已经可以说明问题了,第一段输出我们正常调用了三次构造三次析构函数,第二段当我们new一个基础类型的数组调用delete时不会出问题(其实内存也正常释放了,并没有造成内存泄露,此时delete和delete[]的行为是一样的),但是第三段当我们调用new一个c++对象的数组时就会有问题,我们可以看到我们的构造函数调用了三次,析构函数只调用了一次(报错的堆栈信息显示已经开始调用mmunmap释放内存了,说明开始释放整个数组的内存空间了),正常情况下应该把所有的数组元素的析构函数都调用一遍才对。
所以不管调用delete和delete[]都会正常释放数组本身的内存,但是delete[]会调用数组每个元素的析构函数而delete只会调用首个元素的析构函数(数组元素是c++对象的时候),如果对象的析构函数中也需要释放一些内存,文件或者socket等资源就会造成资源泄露。这个其实很好理解看一下delete和delete[]的源码就很清楚了,释放数组本身的内存逻辑两者是一样的,只是在调用delete[]时编译器会生成数组每个元素的析构函数的调用,而delete[]只会生成一个。
void *operator new(size_t size, const char *file, unsigned int line) {
void *ptr = malloc(size);
return ptr;
}
void *operator new[](size_t size, const char *file, unsigned int line) {
void *ptr = malloc(size);
return ptr;
}
void operator delete(void *ptr) {
free(ptr);
}
void operator delete[](void *ptr) {
free(ptr);
}
3 第三个问题
CPU 是如何读写内存的?https://blog.youkuaiyun.com/zhying719/article/details/118687075 https://blog.youkuaiyun.com/zhying719/article/details/118687075mmap原理分析https://www.cnblogs.com/huxiao-tee/p/4660352.htmlhttps://www.cnblogs.com/huxiao-tee/p/4660352.html
https://blog.youkuaiyun.com/zhying719/article/details/118687075mmap原理分析https://www.cnblogs.com/huxiao-tee/p/4660352.htmlhttps://www.cnblogs.com/huxiao-tee/p/4660352.html
参考文章:
delete 和 delete []的真正区别https://www.cnblogs.com/whwywzhj/p/7905176.htmlhttps://www.cnblogs.com/whwywzhj/p/7905176.htmllinux下内存分配相关https://zhuanlan.zhihu.com/p/339798795https://zhuanlan.zhihu.com/p/339798795Linux源码分析之:malloc、freehttps://www.cnblogs.com/lit10050528/p/8619977.htmlhttps://www.cnblogs.com/lit10050528/p/8619977.html

















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









