




 博客内容提及练习,但信息较少,未明确练习具体指向信息技术领域的哪方面。
博客内容提及练习,但信息较少,未明确练习具体指向信息技术领域的哪方面。
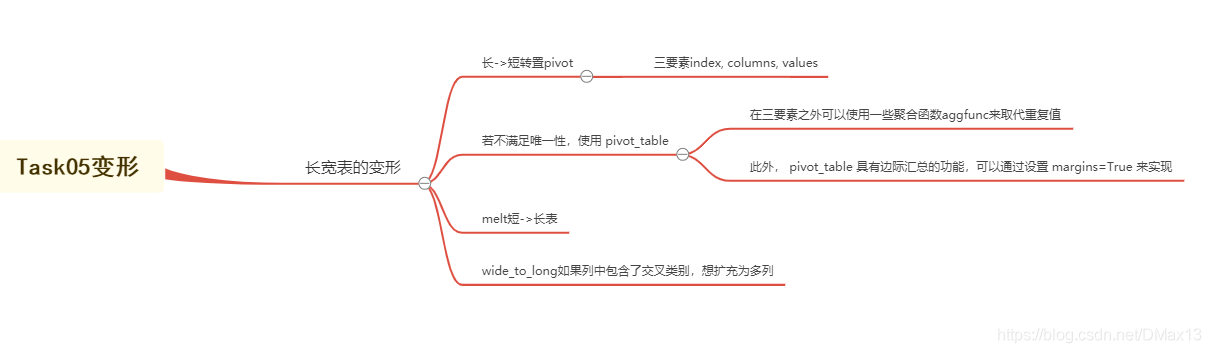

练习
1.
df = pd.read_csv('data/Drugs.csv',index_col=['State','COUNTY']).sort_index()
df.head()
result = pd.pivot_table(df,index=['State','COUNTY','SubstanceName']
,columns='YYYY'
,values='DrugReports',fill_value='-').reset_index().rename_axis(columns={'YYYY':''})
result.head()
#------------------#
result_melted = result.melt(id_vars=result.columns[:3],value_vars=result.columns[-8:]
,var_name='YYYY',value_name='DrugReports').query('DrugReports != "-"')
result2 = result_melted.sort_values(by=['State','COUNTY','YYYY'
,'SubstanceName']).reset_index().drop(columns='index')
result2.head()
#-----------------------#
#方法一
res = df.pivot_table(index='YYYY', columns='State', values='DrugReports', aggfunc='sum')
res.head()
#方法二
res = df.groupby(['State', 'YYYY'])['DrugReports'].sum().to_frame().unstack(0).droplevel(0,axis=1)
res.head()
df = pd.DataFrame({'Class':[1,2],
'Name':['San Zhang', 'Si Li'],
'Chinese':[80, 90],
'Math':[80, 75]})
df
#------------------------
df_melted=df.melt(id_vars = ['Class', 'Name'],
value_vars = ['Chinese', 'Math'],
var_name = 'Subject',
value_name = 'Grade')
df_melted
#----------------
# 使用 wide_to_long 生成 melt 一节中的 df_melted
df_wtl = df.rename(columns={'Chinese':'my_Chinese', 'Math':'my_Math'})
df_wtl = pd.wide_to_long(df_wtl,
stubnames=['my'],
i = ['Class', 'Name'],
j='Subject',
sep='_',
suffix='.+').reset_index().rename(columns={'my':'Grade'})
df_wtl

















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









