




 本文深入解析Android系统中BufferQueue模块的功能,包括BufferQueue如何管理与消费surface,不同应用如何通过BufferQueue分配和使用内存,以及Buffer的状态变迁流程。详细探讨了Buffer内存的来源、BufferQueue与应用之间的互斥操作机制,以及BufferQueue与SurfaceFlinger之间的交互关系,揭示了BufferQueue在UI刷新过程中的关键作用。
本文深入解析Android系统中BufferQueue模块的功能,包括BufferQueue如何管理与消费surface,不同应用如何通过BufferQueue分配和使用内存,以及Buffer的状态变迁流程。详细探讨了Buffer内存的来源、BufferQueue与应用之间的互斥操作机制,以及BufferQueue与SurfaceFlinger之间的交互关系,揭示了BufferQueue在UI刷新过程中的关键作用。
6 BufferQueue
上一篇已经说到,BufferQueue是SurfaceFlinger管理和消费surface的中介,我们就开始分析bufferqueue。
每个应用 可以由几个BufferQueue?
应用绘制UI 所需的内存从何而来?
应用和SurfaceFlinger 如何互斥共享资源的访问?
6.1 Buffer的状态

const char* BufferSlot::bufferStateName(BufferState state) {
switch (state) {
case BufferSlot::DEQUEUED: return "DEQUEUED";
case BufferSlot::QUEUED: return "QUEUED";
case BufferSlot::FREE: return "FREE";
case BufferSlot::ACQUIRED: return "ACQUIRED";
default: return "Unknown";
}
}
状态变迁如下:FREE->DEQUEUED->QUEUED->ACQUIRED->FREE
BufferQueue的状态迁移图:
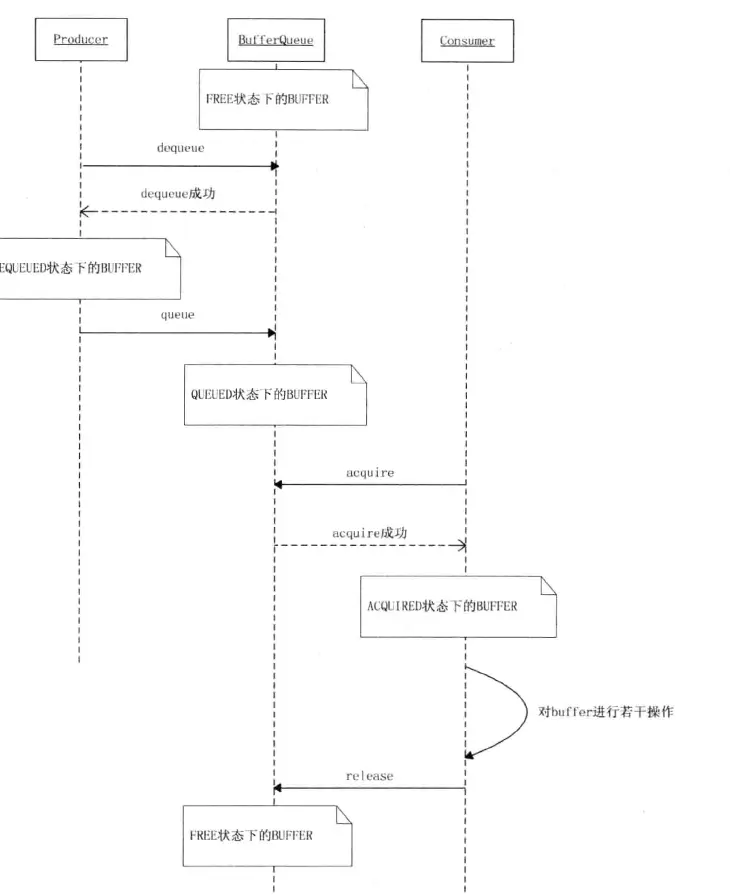
我们先来看,producer & comsumer 分别是什么?
应用程序需要刷新UI,所以就会产生surface到BufferQueue,so,producer 可以认为就是应用程序,也可以是上一篇里面介绍的ISurfaceComposerClient。
comsumer不用看也知道,就是SurfaceFlinger。所以可以明确一个大致的流程就是,
1)应用需要刷新UI,获取一个buffer的缓冲区,这个操作就是dequeue。经过dequeue以后,该buffer被producer锁定,其他Owner就不能插手了。
2)然后把surface写入到该buffer里面,当producer认为写入结束后,就执行queue的操作,把buffer 归还给bufferqueue。Owner也变成为bufferqueue。
3)当一段buffer里面由数据以后,comsumer就会收到消息,然后去获取该buffer。
void BufferQueue::ProxyConsumerListener::onFrameAvailable(
const android::BufferItem& item) {
sp<ConsumerListener> listener(mConsumerListener.promote());
if (listener != NULL) {
listener->onFrameAvailable(item);
}
}
bufferqueue里面就是comsumerlistener,当有可以使用的buffer后,就会通知comsumer使用。
// mGraphicBuffer points to the buffer allocated for this slot or is NULL
// if no buffer has been allocated.
sp<GraphicBuffer> mGraphicBuffer;
可以看到注释,bufferqueue的mSlot[64],并不是都有内容的,也就是mSlot存的是buferr的指针,如果没有,就存null
slot的个数在andorid5.0 里面定义在BufferQueueDefs.h里面,
enum { NUM_BUFFER_SLOTS = 64 };
6.2 Buffer内存的出处
既然producer是主动操作,所以如果在dequeue的时候,已经获取了内存,后面的操作也就不需要分配内存了。

status_t BufferQueueProducer::dequeueBuffer(int *outSlot,
sp<android::Fence> *outFence, bool async,
uint32_t width, uint32_t height, uint32_t format, uint32_t usage) {
ATRACE_CALL();
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
mConsumerName = mCore->mConsumerName;
} // Autolock scope
BQ_LOGV("dequeueBuffer: async=%s w=%u h=%u format=%#x, usage=%#x",
async ? "true" : "false", width, height, format, usage);
if ((width && !height) || (!width && height)) {
BQ_LOGE("dequeueBuffer: invalid size: w=%u h=%u", width, height);
return BAD_VALUE;
}
status_t returnFlags = NO_ERROR;
EGLDisplay eglDisplay = EGL_NO_DISPLAY;
EGLSyncKHR eglFence = EGL_NO_SYNC_KHR;
bool attachedByConsumer = false;
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
mCore->waitWhileAllocatingLocked();
if (format == 0) {
format = mCore->mDefaultBufferFormat;
}
// Enable the usage bits the consumer requested
usage |= mCore->mConsumerUsageBits;
int found;
status_t status = waitForFreeSlotThenRelock("dequeueBuffer", async,
&found, &returnFlags);
if (status != NO_ERROR) {
return status;
}
// This should not happen
if (found == BufferQueueCore::INVALID_BUFFER_SLOT) {
BQ_LOGE("dequeueBuffer: no available buffer slots");
return -EBUSY;
}
*outSlot = found;
ATRACE_BUFFER_INDEX(found);
attachedByConsumer = mSlots[found].mAttachedByConsumer;
const bool useDefaultSize = !width && !height;
if (useDefaultSize) {
width = mCore->mDefaultWidth;
height = mCore->mDefaultHeight;
}
mSlots[found].mBufferState = BufferSlot::DEQUEUED;
const sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);
if ((buffer == NULL) ||
(static_cast<uint32_t>(buffer->width) != width) ||
(static_cast<uint32_t>(buffer->height) != height) ||
(static_cast<uint32_t>(buffer->format) != format) ||
((static_cast<uint32_t>(buffer->usage) & usage) != usage))
{
mSlots[found].mAcquireCalled = false;
mSlots[found].mGraphicBuffer = NULL;
mSlots[found].mRequestBufferCalled = false;
mSlots[found].mEglDisplay = EGL_NO_DISPLAY;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
returnFlags |= BUFFER_NEEDS_REALLOCATION;
}
if (CC_UNLIKELY(mSlots[found].mFence == NULL)) {
BQ_LOGE("dequeueBuffer: about to return a NULL fence - "
"slot=%d w=%d h=%d format=%u",
found, buffer->width, buffer->height, buffer->format);
}
eglDisplay = mSlots[found].mEglDisplay;
eglFence = mSlots[found].mEglFence;
*outFence = mSlots[found].mFence;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
} // Autolock scope
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
status_t error;
BQ_LOGV("dequeueBuffer: allocating a new buffer for slot %d", *outSlot);
sp<GraphicBuffer> graphicBuffer(mCore->mAllocator->createGraphicBuffer(
width, height, format, usage, &error));
if (graphicBuffer == NULL) {
BQ_LOGE("dequeueBuffer: createGraphicBuffer failed");
return error;
}
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
if (mCore->mIsAbandoned) {
BQ_LOGE("dequeueBuffer: BufferQueue has been abandoned");
return NO_INIT;
}
mSlots[*outSlot].mFrameNumber = UINT32_MAX;
mSlots[*outSlot].mGraphicBuffer = graphicBuffer;
} // Autolock scope
}
if (attachedByConsumer) {
returnFlags |= BUFFER_NEEDS_REALLOCATION;
}
if (eglFence != EGL_NO_SYNC_KHR) {
EGLint result = eglClientWaitSyncKHR(eglDisplay, eglFence, 0,
1000000000);
// If something goes wrong, log the error, but return the buffer without
// synchronizing access to it. It's too late at this point to abort the
// dequeue operation.
if (result == EGL_FALSE) {
BQ_LOGE("dequeueBuffer: error %#x waiting for fence",
eglGetError());
} else if (result == EGL_TIMEOUT_EXPIRED_KHR) {
BQ_LOGE("dequeueBuffer: timeout waiting for fence");
}
eglDestroySyncKHR(eglDisplay, eglFence);
}
BQ_LOGV("dequeueBuffer: returning slot=%d/%" PRIu64 " buf=%p flags=%#x",
*outSlot,
mSlots[*outSlot].mFrameNumber,
mSlots[*outSlot].mGraphicBuffer->handle, returnFlags);
return returnFlags;
}
step1:BufferQueueProducer::waitForFreeSlotThenRelock 循环的主要作用就是查找可以使用的slot。
step2:释放不需要的buffer,并且统计已分配的内存。
// Free up any buffers that are in slots beyond the max buffer count
for (int s = maxBufferCount; s < BufferQueueDefs::NUM_BUFFER_SLOTS; ++s) {
assert(mSlots[s].mBufferState == BufferSlot::FREE);
if (mSlots[s].mGraphicBuffer != NULL) {
mCore->freeBufferLocked(s);
*returnFlags |= RELEASE_ALL_BUFFERS;
}
}
for (int s = 0; s < maxBufferCount; ++s) {
switch (mSlots[s].mBufferState) {
case BufferSlot::DEQUEUED:
++dequeuedCount;
break;
case BufferSlot::ACQUIRED:
++acquiredCount;
break;
case BufferSlot::FREE:
// We return the oldest of the free buffers to avoid
// stalling the producer if possible, since the consumer
// may still have pending reads of in-flight buffers
if (*found == BufferQueueCore::INVALID_BUFFER_SLOT ||
mSlots[s].mFrameNumber < mSlots[*found].mFrameNumber) {
*found = s;
}
break;
default:
break;
}
}
如果有合适的,found 就是可以使用的buffer编号。
如果dequeue too many,but comsumer还来不及消耗掉,这个时候,有可能会导致OOM,所以,判断是否在队列里面有过多的buffer。
等待comsumer消耗后,释放互斥锁。
if (tryAgain) {
// Return an error if we're in non-blocking mode (producer and
// consumer are controlled by the application).
// However, the consumer is allowed to briefly acquire an extra
// buffer (which could cause us to have to wait here), which is
// okay, since it is only used to implement an atomic acquire +
// release (e.g., in GLConsumer::updateTexImage())
if (mCore->mDequeueBufferCannotBlock &&
(acquiredCount <= mCore->mMaxAcquiredBufferCount)) {
return WOULD_BLOCK;
}
mCore->mDequeueCondition.wait(mCore->mMutex);
}
在返回dqueueBuffer这个方法:如果没有找到free的slot,就直接返回错误。当然正常情况下是不会发生的。
// This should not happen
if (found == BufferQueueCore::INVALID_BUFFER_SLOT) {
BQ_LOGE("dequeueBuffer: no available buffer slots");
return -EBUSY;
}
mSlots[found].mBufferState = BufferSlot::DEQUEUED;
把找到的buffer的状态设为DEQUEUE。
在判断了mSlot[found]的属性以后,它可能是空的,也有可能不符合当前需要的buffer的size,就给mSlot[found]分配新的属性和内存
if ((buffer == NULL) ||
(static_cast<uint32_t>(buffer->width) != width) ||
(static_cast<uint32_t>(buffer->height) != height) ||
(static_cast<uint32_t>(buffer->format) != format) ||
((static_cast<uint32_t>(buffer->usage) & usage) != usage))
{
mSlots[found].mAcquireCalled = false;
mSlots[found].mGraphicBuffer = NULL;
mSlots[found].mRequestBufferCalled = false;
mSlots[found].mEglDisplay = EGL_NO_DISPLAY;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
returnFlags |= BUFFER_NEEDS_REALLOCATION;
}
if (CC_UNLIKELY(mSlots[found].mFence == NULL)) {
BQ_LOGE("dequeueBuffer: about to return a NULL fence - "
"slot=%d w=%d h=%d format=%u",
found, buffer->width, buffer->height, buffer->format);
}
eglDisplay = mSlots[found].mEglDisplay;
eglFence = mSlots[found].mEglFence;
*outFence = mSlots[found].mFence;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
} // Autolock scope
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
status_t error;
BQ_LOGV("dequeueBuffer: allocating a new buffer for slot %d", *outSlot);
sp<GraphicBuffer> graphicBuffer(mCore->mAllocator->createGraphicBuffer(
width, height, format, usage, &error));
if (graphicBuffer == NULL) {
BQ_LOGE("dequeueBuffer: createGraphicBuffer failed");
return error;
}
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
if (mCore->mIsAbandoned) {
BQ_LOGE("dequeueBuffer: BufferQueue has been abandoned");
return NO_INIT;
}
mSlots[*outSlot].mFrameNumber = UINT32_MAX;
mSlots[*outSlot].mGraphicBuffer = graphicBuffer;
} // Autolock scope
}
这样buffer对应的内存就是在producer,dequeue操作的时候分配内存的。(if need)
6.3应用程序和BufferQueue的关系
首先看一张surface各类之间的关系:
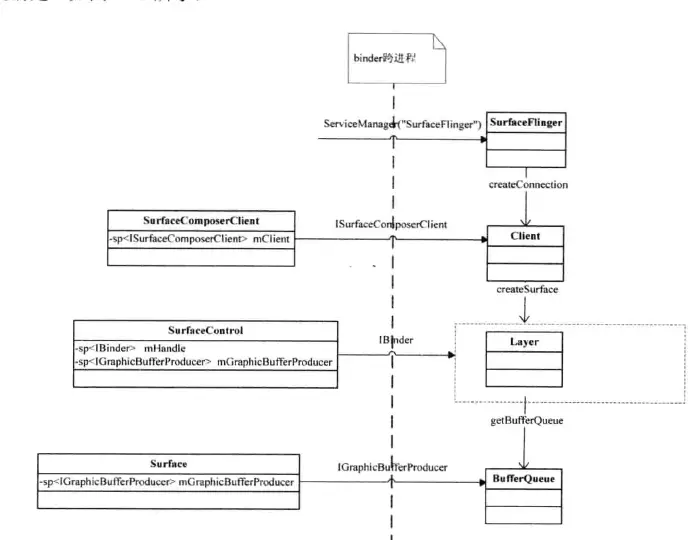
这里多了一个Layer的东西,Layer代表一个画面的图层(在android app的角度以前是没有图层的概念的,虽然framework有)。
SurfaceFlinger混合,就是把所有的layer做混合。
我们先来看createlayer:
status_t SurfaceFlinger::createLayer(
const String8& name,
const sp<Client>& client,
uint32_t w, uint32_t h, PixelFormat format, uint32_t flags,
sp<IBinder>* handle, sp<IGraphicBufferProducer>* gbp)
这里关键是handler & gbp这2个参数。
我们看下去代码:layer 是从createNormalLayer里面来的
status_t SurfaceFlinger::createNormalLayer(const sp<Client>& client,
const String8& name, uint32_t w, uint32_t h, uint32_t flags, PixelFormat& format,
sp<IBinder>* handle, sp<IGraphicBufferProducer>* gbp, sp<Layer>* outLayer)
{
// initialize the surfaces
switch (format) {
case PIXEL_FORMAT_TRANSPARENT:
case PIXEL_FORMAT_TRANSLUCENT:
format = PIXEL_FORMAT_RGBA_8888;
break;
case PIXEL_FORMAT_OPAQUE:
format = PIXEL_FORMAT_RGBX_8888;
break;
}
*outLayer = new Layer(this, client, name, w, h, flags);
status_t err = (*outLayer)->setBuffers(w, h, format, flags);
if (err == NO_ERROR) {
*handle = (*outLayer)->getHandle();
*gbp = (*outLayer)->getProducer();
}
ALOGE_IF(err, "createNormalLayer() failed (%s)", strerror(-err));
return err;
}
producer跟踪源代码可以看到:
class MonitoredProducer : public IGraphicBufferProducer
通过bind机制,可以认为就是BufferQueue的一个子类。
所以,每一个bufferqueue对应的都是一个layer。
看下handler:
sp<IBinder> Layer::getHandle() {
Mutex::Autolock _l(mLock);
LOG_ALWAYS_FATAL_IF(mHasSurface,
"Layer::getHandle() has already been called");
mHasSurface = true;
/*
* The layer handle is just a BBinder object passed to the client
* (remote process) -- we don't keep any reference on our side such that
* the dtor is called when the remote side let go of its reference.
*
* LayerCleaner ensures that mFlinger->onLayerDestroyed() is called for
* this layer when the handle is destroyed.
*/
class Handle : public BBinder, public LayerCleaner {
wp<const Layer> mOwner;
public:
Handle(const sp<SurfaceFlinger>& flinger, const sp<Layer>& layer)
: LayerCleaner(flinger, layer), mOwner(layer) {
}
};
return new Handle(mFlinger, this);
}
没有什么东西,就是LayerCleaner,
它的设计目的就是SurfaceFlinger来清除图层。
所以我们可以得出结论
1)一个app对应一个surfaceFlinger,可以有多个layer,从而对应多个bufferqueue
2)surface的缓冲区内存是BufferQueue在进行dequeue的时候分配的,属于client端。
3)App & SurfaceFlinger都通过bufferQueue来分配和使用缓冲区,所以互斥操作是由BufferQueue来实现。
参考:
《深入理解android内核设计思想》 林学森


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









