






在浏览器打开 月光社 武器大全 按下F12或检查
点击第一个选项卡 双枪
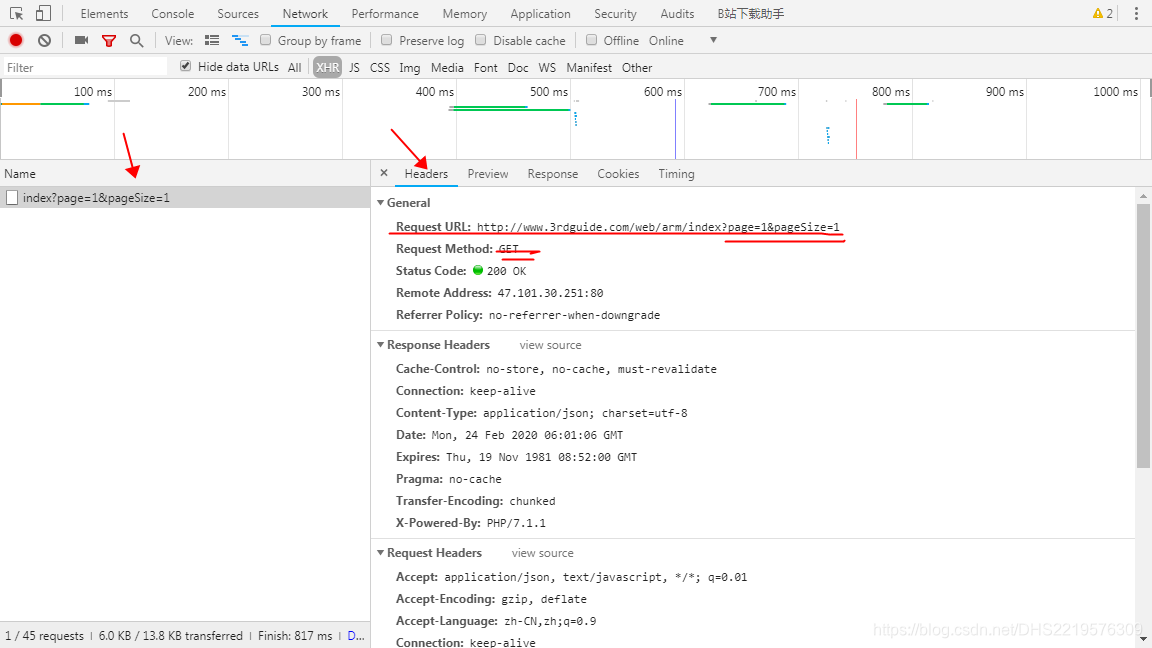
可以看到这个请求的方式是:GET
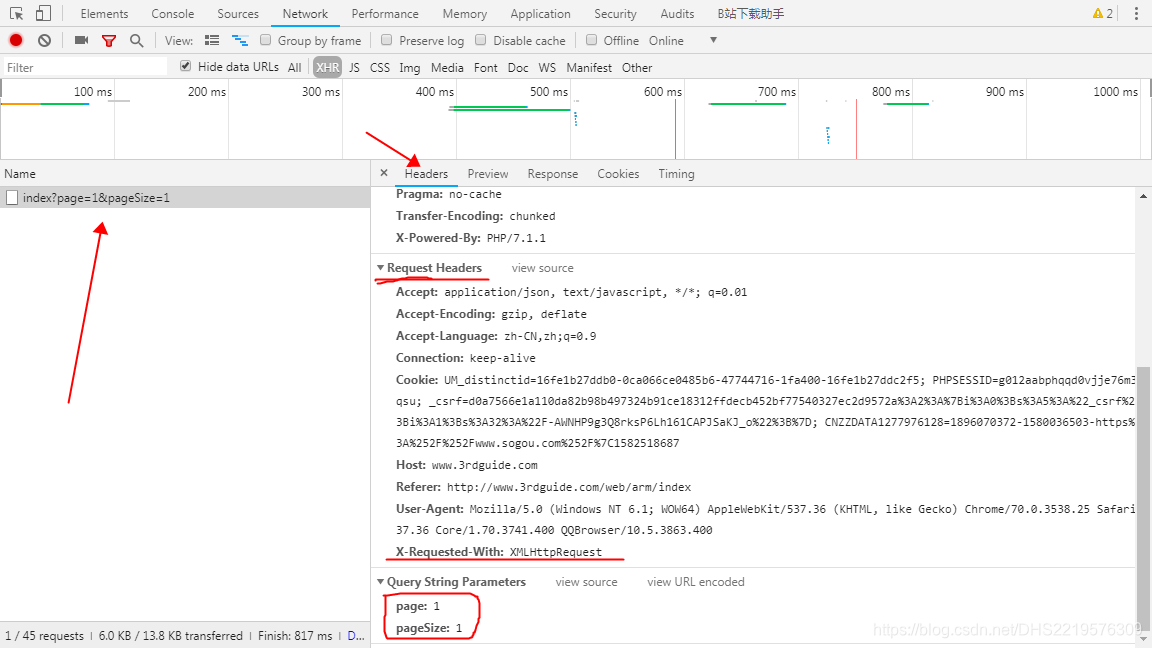
X-Requested-With: XMLHttpRequest
只有ajax异步请求才会有这个参数
Request URL: http://www.3rdguide.com/web/arm/index?page=1&pageSize=1
page: 1
pageSize: 1

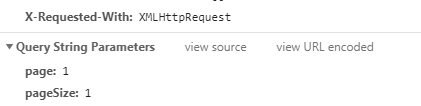
可以直观的看到请求链接的构建需要用到Query String Parameters中的参数,我们现在回过头去尝试点击其他的选项卡


查看这个新请求的Query String Parameters
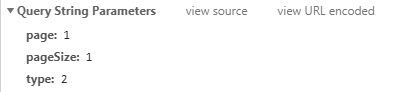
现在我们已经发现了选项卡之间的关联type
回到武器大全,滑动滚轮抵达页面的最底下
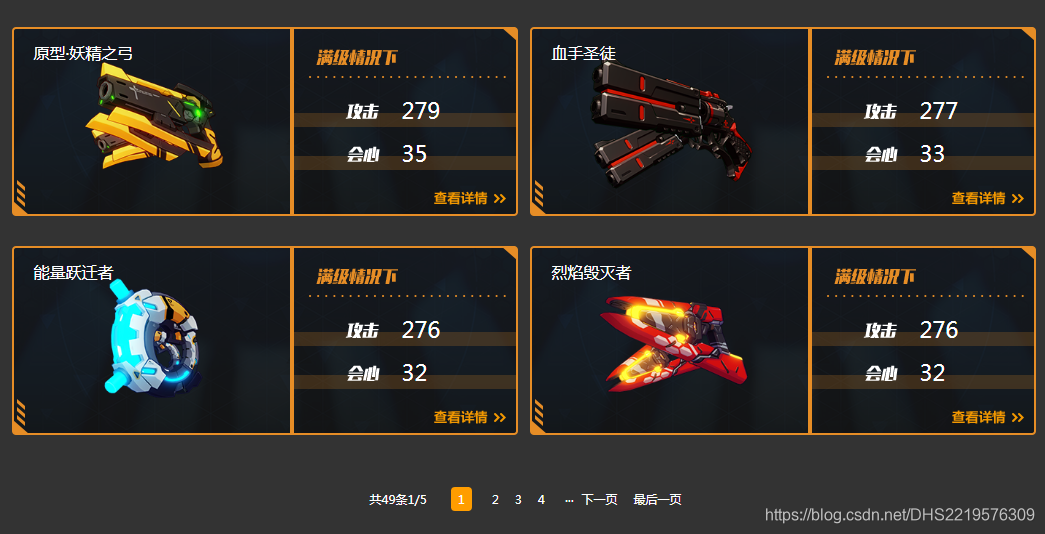
可以发现,这些信息不止一页,关于双枪的信息就有5页,点击页码2,来分析规律
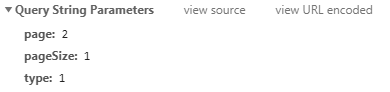
page的值由1变成了2
到此步请求链接的规律已经分析完成 type控制武器类别选项卡,page控制信息的页码,pageSize是与我们的主线无关的键
现在开始编写爬虫,来直接请求这些链接,但是同时不要忘了编写爬虫头,我们直接从Request Headers中复制请求头,来模拟浏览器访问
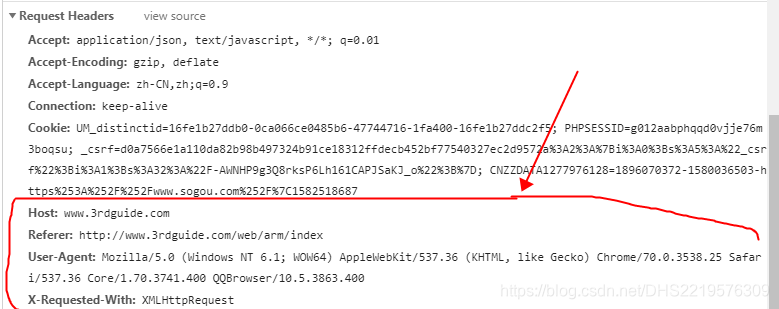
这些就是爬虫的请求头,请求头很重要,如果请求头出错,在爬取ajax异步加载网页时就有可能不会返回或返回错误信息
def get_type_index(page_number,type_number):
data = {
'page':page_number,
'pageSize':'1',
'type':type_number
}
head = {
'Host': 'www.3rdguide.com',
'Referer': 'http://www.3rdguide.com/web/arm/index',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400',
'X-Requested-With': 'XMLHttpRequest'
}
url = 'http://www.3rdguide.com/web/arm/index?'+urlencode(data) #构建成page=1&pageSize=1形式
response = requests.get(url,headers = head)
json = response.json()
return json
我们用这些代码请求一下,获取信息 get_type_index(1,1)

从结果可以看出,返回的信息都储存在一个字典中,并且武器信息都储存在字典中名为data的键中
data = json['data']

现在就没有半点毛病了。可以清晰的看到我们需要的信息
armsImg储存图片链接
armsName储存武器名称
我们只需要图片,所以其他的信息就不搞了
def data_index(page_number,type_number):
json = get_type_index(page_number,type_number)
data = json['data']
for arm_data in data:
armsImg = 'http:' + arm_data['armsImg']
armsName = arm_data['armsName']
img_response = requests.get(armsImg)
if os.path.exists(os.getcwd()+'/Arms'): #判断该程序目录下是否含有名为 Arms 的文件夹
pass
else:
os.mkdir(os.getcwd()+'/Arms') #在该目录下创建名为 Arms 的文件夹
Format = armsImg[-4:]
open('./Arms/'+armsName+Format,'wb').write(img_response.content)
print('保存成功:'+str(armsName))
接下来构建函数入口
def main():
for i in range(1,8):
type_number = i
if type_number in (1,2,3):
page_number_max = 5
for I in range(1,page_number_max + 1):
page_number = I
data_index(page_number,type_number)
elif type_number == 4:
page_number_max = 4
for I in range(1,page_number_max +1):
page_number = I
data_index(page_number,type_number)
elif type_number == 5:
page_number_max = 3
for I in range(1,page_number_max +1):
page_number = I
data_index(page_number,type_number)
elif type_number in (6,7):
page_number_max = 2
for I in range(1,page_number_max +1):
page_number = I
data_index(page_number,type_number)
else:
pass
合并代码
import requests
from urllib.parse import urlencode
import re
import os
def get_type_index(page_number,type_number):
data = {
'page':page_number,
'pageSize':'1',
'type':type_number
}
head = {
'Host': 'www.3rdguide.com',
'Referer': 'http://www.3rdguide.com/web/arm/index',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400',
'X-Requested-With': 'XMLHttpRequest'
}
url = 'http://www.3rdguide.com/web/arm/index?'+urlencode(data)
response = requests.get(url,headers = head)
json = response.json()
return json
def data_index(page_number,type_number):
json = get_type_index(page_number,type_number)
data = json['data']
for arm_data in data:
armsImg = 'http:' + arm_data['armsImg']
armsName = arm_data['armsName']
img_response = requests.get(armsImg)
if os.path.exists(os.getcwd()+'/Arms'): #判断该程序目录下是否含有名为 Arms 的文件夹
pass
else:
os.mkdir(os.getcwd()+'/Arms') #在该目录下创建名为 Arms 的文件夹
Format = armsImg[-4:]
open('./Arms/'+armsName+Format,'wb').write(img_response.content)
print('保存成功:'+str(armsName))
def main():
for type_number in range(1,8):
if type_number in (1,2,3):
page_number_max = 5
for page_number in range(1,page_number_max + 1):
data_index(page_number,type_number)
elif type_number == 4:
page_number_max = 4
for page_number in range(1,page_number_max +1):
data_index(page_number,type_number)
elif type_number == 5:
page_number_max = 3
for page_number in range(1,page_number_max +1):
data_index(page_number,type_number)
elif type_number in (6,7):
page_number_max = 2
for page_number in range(1,page_number_max +1):
data_index(page_number,type_number)
else:
pass
if __name__ == '__main__':
main()
效果
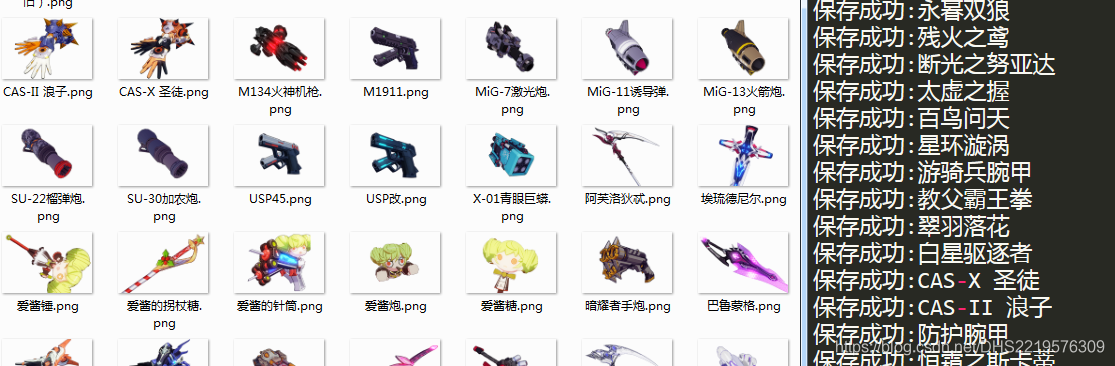
文章到这里就结束了,如果对我写的代码有疑问的可以在评论中提出来
时间 2020/2/24

















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









