







 本文深入介绍了电子罗盘的工作原理,包括磁力计、加速度计和陀螺仪的结合,以及卡尔曼滤波在姿态计算中的作用。讨论了电子罗盘的校准方法,如平面校准和椭球拟合,并广泛应用于农业机械、航空航天、水下勘探等多个领域。同时,文章阐述了电子罗盘在倾斜补偿和航偏角计算中的重要性,确保了在不同角度下的精度。
本文深入介绍了电子罗盘的工作原理,包括磁力计、加速度计和陀螺仪的结合,以及卡尔曼滤波在姿态计算中的作用。讨论了电子罗盘的校准方法,如平面校准和椭球拟合,并广泛应用于农业机械、航空航天、水下勘探等多个领域。同时,文章阐述了电子罗盘在倾斜补偿和航偏角计算中的重要性,确保了在不同角度下的精度。
1 概述及应用
基本介绍
电子罗盘,也叫数字指南针,是利用地磁场来定北极的一种方法,作为导航仪器或姿态传感器已被广泛应用。古代称为罗经,现代利用先进加工工艺生产的磁阻传感器为罗盘的数字化提供了有力的帮助。现在一般由用磁阻传感器或磁通门等芯片加工而成的电子罗盘。
可应用在水平孔和垂直孔测量、水下勘探、飞行器导航、科学研究、教育培训、建筑物定位、设备维护、导航系统等领域。

基本原理
地球的磁场像一个条形磁体一样由磁南极指向磁北极。在磁极点处磁场和当地的水平面垂直,在赤道磁场和当地的水平面平行,所以在北半球磁场方向倾斜指向地面。用来衡量磁感应强度大小的单位是Tesla或者Gauss(1Tesla=10000Gauss)。
随着地理位置的不同,通常地磁场的强度是0.4-0.6 Gauss。需要注意的是,磁北极和地理上的北极并不重合,通常他们之间有11度左右的夹角。

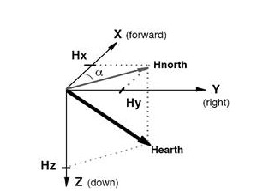
因为地磁场是一个矢量,对于一个固定的地点来说,这个矢量可以被分解为两个与当地水平面平行的分量和一个与当地水平面垂直的分量。如果保持电子罗盘和当地的水平面平行,那么罗盘中磁力计的三个轴就和这三个分量对应起来。
实际上对水平方向的两个分量来说,他们的矢量和总是指向磁北的。罗盘中的航向角(Azimuth)就是当前方向和磁北的夹角。由于罗盘保持水平,如果加入地球磁偏角,只需要用磁力计水平方向两轴(通常为X轴和Y轴)的检测数据就可以计算出航向角。当罗盘水平旋转的时候,航向角在0°- 360°之间变化。

应用领域
农业机械,车载装备,航天航空, 水下勘探,工程机械,地质监测等等需要测量方向方位的应用。
2 运用原理
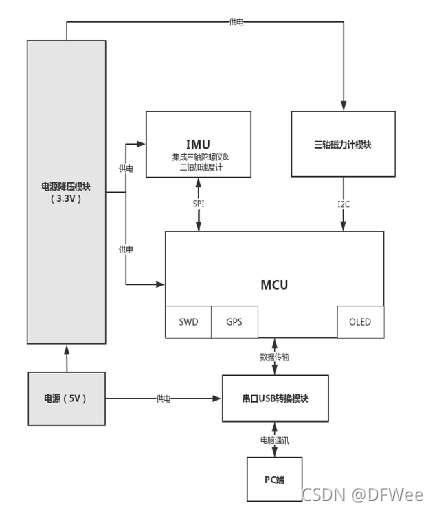
罗盘硬件的主要构成分为五部分,一是磁力计模块(测量罗盘周围的磁场),二是加速度计模块(测量罗盘的加速度),三是陀螺仪模块(测量罗盘的角速度),四是MCU模块(接收信号后进行角度计算,坐标转换,系统误差补偿等,从而得出罗盘的姿态参数,并将数据输出到上位机),五是串口转换模块(可将信号转换成RS-232接口模式与电脑通讯)。以下对部分硬件及原理进行介绍。
1)磁力计
由于地磁场是矢量,在某一地点时,这个矢量可以被分解为两个与当地水平面平行的分量和一个与当地水平面垂直的分量。那么如果保持罗盘模块和当地的水平面平行其中的磁力计的三个轴就可以与这三个分量相对应。
目前是通过倾角补偿来实现对模块与水平面平行,进而通过补偿后数据进行航向角计算。
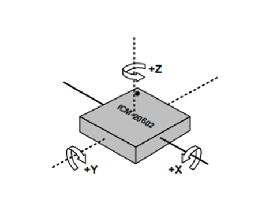
2)加速度计和陀螺仪
加速度: 加速度可以通过三轴数据求出姿态角,虽然静态稳定性有优势,但是动态效果就比较差;
陀螺仪:陀螺仪可以通过角速度积分求出姿态角,虽然动态响应有优势,但是静态稳定性差。
所以基于卡尔曼滤波对加速度、陀螺仪进行融合计算,得出最优估计姿态角对倾角进行补偿。同时因为采用陀螺仪和加速度进行融合,所以可实现动态和静态角度的测量,从而实现罗盘可以满足动态和静态情况下的使用。
3)卡尔曼滤波
卡尔曼滤波(Kalman filtering)是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程。
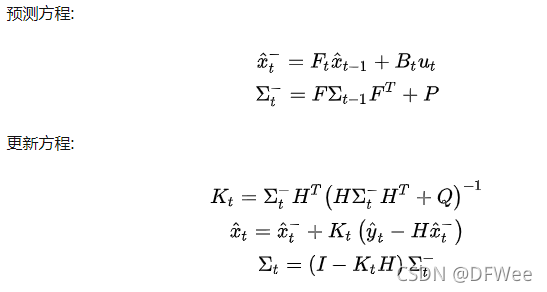
在卡尔曼滤波中假设:
a 其状态转移是线性的,因此我们可以直接用矩阵F表示其线性特征。
b 其状态和观测都是高斯分布(实际生活中一大部分都是高斯分布的,并且高斯分布计算相对简单)。
由于假设b,在多维高斯分布概率密度函数中,最为重要的两个量分别为均值和协方差矩阵 。
因此卡尔曼滤波本质就是将预测方程和观测方程的高斯分布的概率密度融合得到新的高斯分布的概率密度函数作为最优估计,并不断迭代。
总结出以下几点:
① 卡尔曼滤波是一个算法,它适用于线性、离散和有限维系统。每一个有外部变量的自回归移动平均系统(ARMAX)或可用有理传递函数表示的系统都可以转换成用状态空间表示的系统,从而能用卡尔曼滤波进行计算。
② 任何一组观测数据都无助于消除x(t)的确定性。增益K(t)也同样地与观测数据无关。
③ 当观测数据和状态联合服从高斯分布时用卡尔曼递归公式计算得到的是高斯随机变量的条件均值和条件方差,从而卡尔曼滤波公式给出了计算状态的条件概率密度的更新过程线性最小方差估计,也就是最小方差估计。
卡尔曼滤波的一个典型实例是从一组有限的,对物体位置的,包含噪声的观察序列中预测出物体的坐标位置及速度。在很多工程应用(雷达、计算机视觉)中都可以找到它的身影。同时,卡尔曼滤波也是控制理论以及控制系统工程中的一个重要话题。
比如,在雷达中,人们感兴趣的是跟踪目标,但目标的位置、速度、加速度的测量值往往在任何时候都有噪声。卡尔曼滤波利用目标的动态信息,设法去掉噪声的影响,得到一个关于目标位置的好的估计。这个估计可以是对当前目标位置的估计(滤波),也可以是对于将来位置的估计(预测),也可以是对过去位置的估计(插值或平滑)。
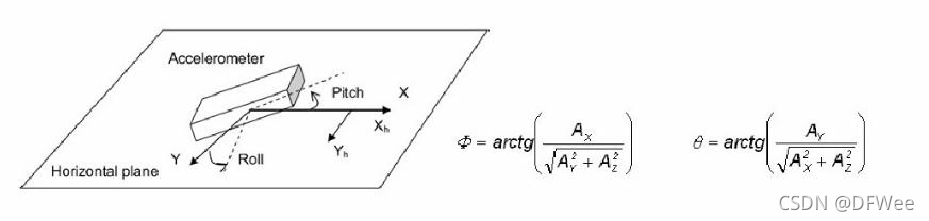
4)倾斜补偿及航偏角计算
电子罗盘一般通电后在水平面上就可以正常使用。但是更多的时候并不是保持水平的,通常它和水平面都有一个夹角。这个夹角会影响航向角的精度,需要通过加速度传感器进行倾斜补偿。具体算法讲解我们放到校准方法部分。
3 逻辑框架
功能逻辑描述
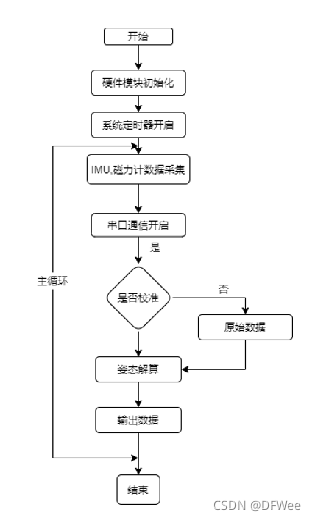
1)电子罗盘通上电,内部就开始运行。先是内部的磁力计,加速度计,陀螺仪等芯片开始采集数据,同时读取校准保存在掉电保存区的补偿值,将补偿值添加入采集的原始数据中实现补偿修正功能。
2)补偿后的数据使用频域或时域滤波,滤除杂质数据。
3)通过卡尔曼滤波融合算法得roll,pitch,yaw数值。
4)子罗盘开始360°平面校准,把校准后的值再串口通讯给上位机。
罗盘硬件框架图:
罗盘软件框架图:
4 校准方法
校准原因
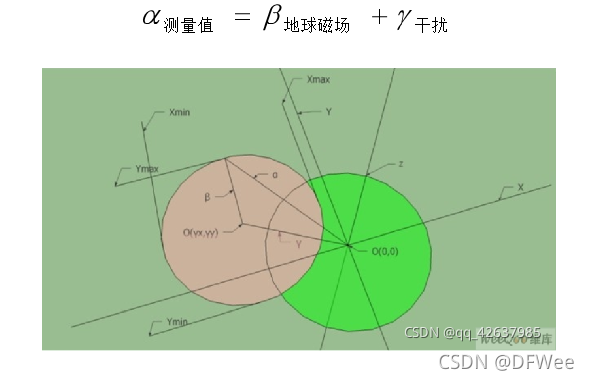
电子罗盘主要是通过感知地球磁场的存在来计算磁北极的方向。然而由于地球磁场在一般情况下只有微弱的0.5高斯,而一个普通的手机喇叭当相距2厘米时仍会有大约4高斯的磁场,一个手机在相距2厘米时会大约6高斯的磁场,这一特点使得电子罗盘测量表面地球磁场时很容易受到电子设备本身的干扰。磁场干扰是指由于具有磁性物质或者可以影响局部磁场强度的物质存在,使得磁传感器所放置位置上地球磁场发生了偏差。
如图所示,在磁传感器的XYZ坐标系中,绿色的圆表示地球磁场矢量绕Z轴圆周转到过程中在XY平面内的投影轨迹,再没有外界任何磁场干扰的情况下,此轨迹将会是一个标准的以O(0,0)为中心的圆。当存在外界磁干扰的情况时,测量得到的磁场强度矢量α将为该点地球磁场β与干扰磁场γ的矢量和。记作:
校准方法类型
1)平面校准法
针对XY轴的校准,将电子罗盘在XY平面内自转,等价于将地球磁场矢量绕着过点O(γx,γy)垂直与XY平面的法线旋转,而红色的圆为磁场矢量在旋转过程中在XY平面内投影的轨迹。这可以找到圆心的位置为((Xman+Xmin)/2,(Ymax+Ymin)/2)同样将设备在XY平面内旋转可以得到地球磁场在XY平面上的轨迹圆,这可以求出三维空间中的磁场干扰矢量γ(γx,γy,γz).
这也是最常用的一种方法,快捷简便。
2)椭球拟合校准方法
对于给定平面上的一组样本点,寻找一个椭圆,使其尽可能靠近这些样本点。也就是说到,将图像中的一组数据以椭圆方程为模型进行拟合,使某一椭圆方程尽量满足这些数据,并求出该椭圆方程的各个参数。最后确定的最佳椭圆的中心即是我们要确定的靶心。
这是另一种可选校准方法,除此之外其实还有好多种校准方法,但是因为博主智力有限(其实就是太懒了哈哈)这里就不多列举了,有兴趣的朋友可以去自行搜索学习。
以下详细介绍平面校准法是如何校准补偿的。
平面校准法
如果磁力计在含有附加的局部磁场的环境中进行操作,磁力计的输出做附加的修正将是必要的。 在没有任何本地磁场的影响下,可以通过旋转设备360°产生的平面 。
使用方法:修正的输出可以根据下面的方法来计算:
1) 在磁场干扰的条件下进行, 数据收集设备被旋转360°。
2)数据进行分析,以产生偏差的偏移和灵敏度的比例因子,以补偿所述干扰。
举个例子:
从数据中发现的X和Y磁强计的最大输出:
X min = -0.284gauss X max = +0.402gauss
Ymin = -0.322gauss Ymax = +0.246gauss
从中可以看出X轴的数据,X具有更大的反应,我们设置其比例系数为1
X s = 1
再计算其他比例系数:
( X max - X min )
Y s = ————————
( Y max - Y min )
对于偏置补偿:
X b = X s[1/2( X max - X min ) - X max ]
Y b = Y s[1/2( Y max - Y min ) - Y max ]
正确的输出: X out = X in*X s + X b Y out = Y in*Y s + Y b
5 结语
好了,电子罗盘的介绍就到这里了,博主能力有限,有不够详细或者说的不对的地方请多多包涵,想更多了解电子罗盘或者对这个传感器有兴趣有需求的话可以咨询博主,一起交流一下~
未经博主允许不准私自转载或抄袭,侵权必究。


















 3558
3558





 到【灌水乐园】发言
到【灌水乐园】发言







