




 本文回顾了人们对PostgreSQLAUTOVACUUM的误解,指出尽管早期可能存在问题,但现在它是关键组件。文章强调了正确配置和使用AUTOVACUUM的重要性,包括工作内存、并发执行器数量,以及针对大表的定制策略。
本文回顾了人们对PostgreSQLAUTOVACUUM的误解,指出尽管早期可能存在问题,但现在它是关键组件。文章强调了正确配置和使用AUTOVACUUM的重要性,包括工作内存、并发执行器数量,以及针对大表的定制策略。
很多PG的老用户都对AUTOVACUUM存有不好的印象,因为VAVCUUM导致的系统问题也让运维人员对PG有十分不好的印象,甚至认为PostgreSQL 不适合于7*24的高并发负载场景。实际上,任何数据库技术都会有不堪的童年,就算是现在的王炸Oracle,当年也让DBA痛恨不已。二十多年前,我从使用RDB数据库转向使用ORACLE的时候,第一印象是,这是个什么玩意,咋这么难用呢。等用惯了Oracle之后回头再看看RDB,就会对RDB百般看不惯了。记得二十年前,Oracle OPS刚出来的时候,也让好多人吃过苦头,甚至很多人十多年过去了,还不太敢用ORACLE RAC。记得差不多15年前,Oracle 负责售前的总监还多次和我探讨在国内,如何去推广Oracle RAC,让客户的核心系统敢于迁移到Oracle RAC上,为此,我还写了《Oracle RAC日记》这本书。
针对PostgreSQL的VACUUM,十多年前我和一个客户还一起写过一篇关于MVCC实现技术对PG应用场景限制的论文,其主要问题也是因为VACUUM存在的问题。不过如果现在有人问我要不要启用AUTOVACUUM的时候,我会毫不犹豫地说,一定要用AUTOVACUUM,而且只有用好了AUTOVACUUM,才算你用好了PG数据库。
有些朋友担心VACUUM会锁定数据库表,影响DML操作,实际上VACUUM并不会阻塞SELECT/INSERT/UPDATE/DELETE等操作,它只会在表上获取一个SHARE UPDATE EXCLUSIVE锁,这个锁只会阻塞一些特殊情况的操作。比如:
- 其他的SHARE UPDATE EXCLUSIVE锁请求,比如一个执行VACUUM FULL操作、ANALYZE或者CREATE INDEX CONCURRENTLY, REINDEX CONCURRENTLY, CREATE STATISTICS或者ALTER TABLE、ALTER INDEX等操作的会话;
- 其他是由SHARE锁的操作,比如CREATE INDEX;
- SHARE ROW EXCLUSIVE锁请求,CREATE TRIGGER和部分ALTER TABLE操作;
- EXCLUSIVE锁请求,比如执行 REFRESH MATERIALIZED VIEW CONCURRENTLY的会话;
- ACCESS EXCLUSIVE 锁请求,比如执行DROP TABLE, TRUNCATE, REINDEX, CLUSTER, VACUUM FULL、REFRESH MATERIALIZED VIEW 。以及一些需要这个锁级别的 ALTER INDEX 和 ALTER TABLE操作。
除此之外,如果系统中存在长时间的事务或者大查询,MVCC也需要访问一些老版本的数据,这样也会导致VACUUM执行时跳过对一些死元组的清理。从而引起一些很长时间以前的死元组无法正常清理。
从上面的情况分析来看,VACUUM对实际的应用影响并没有想象的那么大,对于绝大多数应用场景来说都是可以接受的。虽然如此,很多吃过AUTOVACUUM苦头的DBA出于惯性,都会选择关闭AUTOVACUUM而采用手工VACUUM,等业务不忙的时候去手工执行VACUUM操作,这是因为业务高峰期的VACUUM会导致大量的元组被锁定,整个系统的负载变大,交易性能急剧下降。
这种关闭AUTOVACUUM的做法,一般来说是通过设置一个定时任务,在晚上业务比较少的时候统一做VACUUM。这种做法对于一些应用场景有一定的作用,可以避免不确定的VACUUM操作在特殊高并发场景下引起严重的性能问题。但是在应用系统的场景中,这样操作容易引发一些更为严重的问题,这是因为VACUUM不仅仅是做死元组的回收工作,还会做表分析操作。
一些老Oracle dba可能还有印象,当时从Oracle 8i升级到9i之后,很多SQL的执行计划都出错了。分析了好长时间才定位,这是因为表的统计数据不够准确,或者部分表没有做统计,导致了一些SQL的执行计划出现了问题。PG数据库的CBO优化器也类似与Oracle ,不过因为PG的优化器在算法上还是无法与Oracle媲美,因此PG优化器对统计信息的准确性依赖度很高。一旦某些表的统计数据不够新了,无法反映出数据的实际情况,那么很可能会出现执行计划错误。每天定时做一次VACUUM存在两个弊端,第一个是,如果VACUUM操作进行时,如果出现了前面我们讨论过的集中锁冲突的情况,那么就会跳过这张表的VACUUM操作,从而没有完成死元组的清理。这样就会导致死元组积压,下一次VACUUM的时候,需要处理的时间更长,对系统的影响更大。而如果使用AUTOVACUUM,那么VACUUM操作会被分散在一天的任何时段中,当表中的数据变化积累到一定量的时候,AUTOVACUUM就自动触发了,这种VACUUM比积累了大量变更数据时更为轻便,完成的时间也更短,对应用系统的影响也会越低。
AUTOVACUUM的另外一个好处是,表上的统计信息可以得到更为迅速的更新,表统计信息也会更为准确。PostgreSQL的CBO优化器十分依赖于精准的表统计信息,如果统计信息更为精准,那么SQL的执行计划也会更为准确。在Oracle 9i时代,我经常处置的就是因为统计信息不准确而导致的执行计划错误问题。甚至在给一个快递公司做一个执行计划稳定的优化的时候,我发现因为每天有几次大批量的数据写入,经常会导致某些时段中的表统计数据必然会导致错误的执行计划出现,因为应用中存在应用中动态拼凑SQL,导致所需的执行计划无法通过HINT固定,而白天业务高峰期经常对超大型的表做分析又风险太大。最后我只能通过白天定期通过估算值写入估算的统计信息,晚上业务不忙时再做一次分析的方式解决了这个问题。
类似这个问题的情况,在PostgreSQL数据库中也会出现,而AUTOVACUUM可以在表的数据变化达到某个阈值的时候自动触发VACUUM和ANALYZE操作,从而让表的统计信息得到纠正,从而确保执行计划的合理。
既然AUTOVACUUM如此重要,那么如何做好AUTOVACUUM就更为重要了。实际上,现在的服务器硬件水平和经常出VACUUM事情时代的PG 8/9时代已经不一样了,VACUUM的算法也得到了极大的改善,因此现在的AUTOVACUUM的风险已经大大降低了。虽然如此,对于AUTOVACUUM仍然需要优化。
优化AUTOVACUUM的第一步是未VACUUM操作分配足够的工作内存,maintenance_work_mem参数对应VACUUM的性能有着至关重要的作用,对应较大型的数据库系统,拥有超过10GB的单表的数据库,我们一般至少要给这个参数1GB以上的值。对物理内存比较充裕的系统,将maintenance_work_mem设置为2GB是我比较常用的。另外一个和VACUUM操作相关的参数autovacuum_work_mem可以设置为-1,这样这个参数就会参考maintenance_work_mem参数。
第二个十分重要的参数是autovacuum_max_workers,这取决于有多少张表的VACUUM操作可以并行执行,如果你的系统中有大量的小表,那么就建议把这个参数设置大一些。当然如果你的CPU资源不是很多,那么就不要设置太大的值了。
今天篇幅有限,对于AUTOVACUUM的其他一些参数就不一一讨论了,最后我再谈一个VACUUM的使用心得。那就是对于大型或者超大型的系统,不能仅仅采用全局统一的AUTOVACUUM,对于某些特殊的大表,要采取特殊的AUTOVACUUM策略,也就是说需要设置表级的AUTOVACUUM策略。这一点和我们在运维ORACLE数据库的时候,也会经常遇到,对于一些大表的表分析,不能采用系统默认的方式,而要采取特殊的自定义分析方式,否则很容易出问题。
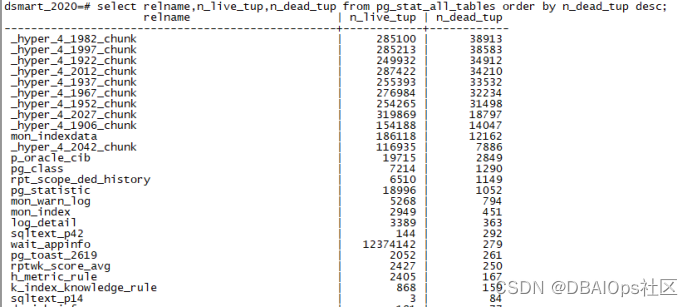
我们可以看到,一个系统中的有些表的死元组比例十分高,有些表则很低。对于一些死元组比例比较高的大表,我们需要根据其业务特点来设置独立的策略。一个比较简单和常用的做法是,首先列出你的系统中的超过1GB的大表(这个阈值根据你的系统的特点去调整,我这里只是举例),然后分析其行数和死元组的数量,比例。同时监控其上次表分析和VACUUM的时间,看看是否合理。如果经常出现某张表很长时间没有做VACUUM和ANALYZE,那么这张表的默认AUTOVACUUM参数有可能不够合理,需要调整表上的这些参数。另外如果你确实反省自动VACUUM导致了某些业务不正常,那么也有可能是相关表上的AUTOVACUUM参数设置不合理导致的,那么你可以通过调整这些参数来解决这个问题,而不要不分青红皂白就关掉AUTOVACUUM。

















 1989
1989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









