




 SECOND是VoxelNet的升级版,主要改进在于引入稀疏3D卷积以提高运算效率和内存使用,解决了VoxelNet训练时的问题。此外,它采用了FocalLoss处理正负样本不平衡,以及新的方向回归损失函数,优化了物体方向的估计。文章详细解释了稀疏卷积的工作原理和方向回归的建模方法。
SECOND是VoxelNet的升级版,主要改进在于引入稀疏3D卷积以提高运算效率和内存使用,解决了VoxelNet训练时的问题。此外,它采用了FocalLoss处理正负样本不平衡,以及新的方向回归损失函数,优化了物体方向的估计。文章详细解释了稀疏卷积的工作原理和方向回归的建模方法。
1.前言
在AVOD的论文解析中,我们提到了AVOD(2018)其实是MV3D(2017)论文的升级版。
相似地,本文要介绍的SECOND(2018)其实就是VoxelNet(2017)论文的升级版。
SECOND的全称是Sparsely Embedded Convolutional Detection。
论文的地址
代码的地址
论文提出的主要动机为:
(1)考虑到VoxelNet论文在运算过程中运算量较大,且速度不佳。作者引入了稀疏3D卷积去代替VoxelNet中的3D卷积层,提高了检测速度和内存使用;
(2)VoxelNet论文有个比较大的缺点就是在训练过程中,与真实的3D检测框相反方向的预测检测框会有较大的损失函数,从而造成训练过程不好收敛。
顺带着动机,作者又提出了一些其他的创新点:
(1)比如数据增强这块,作者使用了数据库采样的操作;
(2)对于正负样本数量的极度不平衡问题,作者借鉴了RetinaNet中采用的Focal Loss。
这篇文章有关稀疏卷积部分稍微有些难懂,我找遍了全网有关SECOND的解读,大家都跳过了稀疏卷积这块,这确实让人头大。
关于稀疏卷积
2. 网络的结构
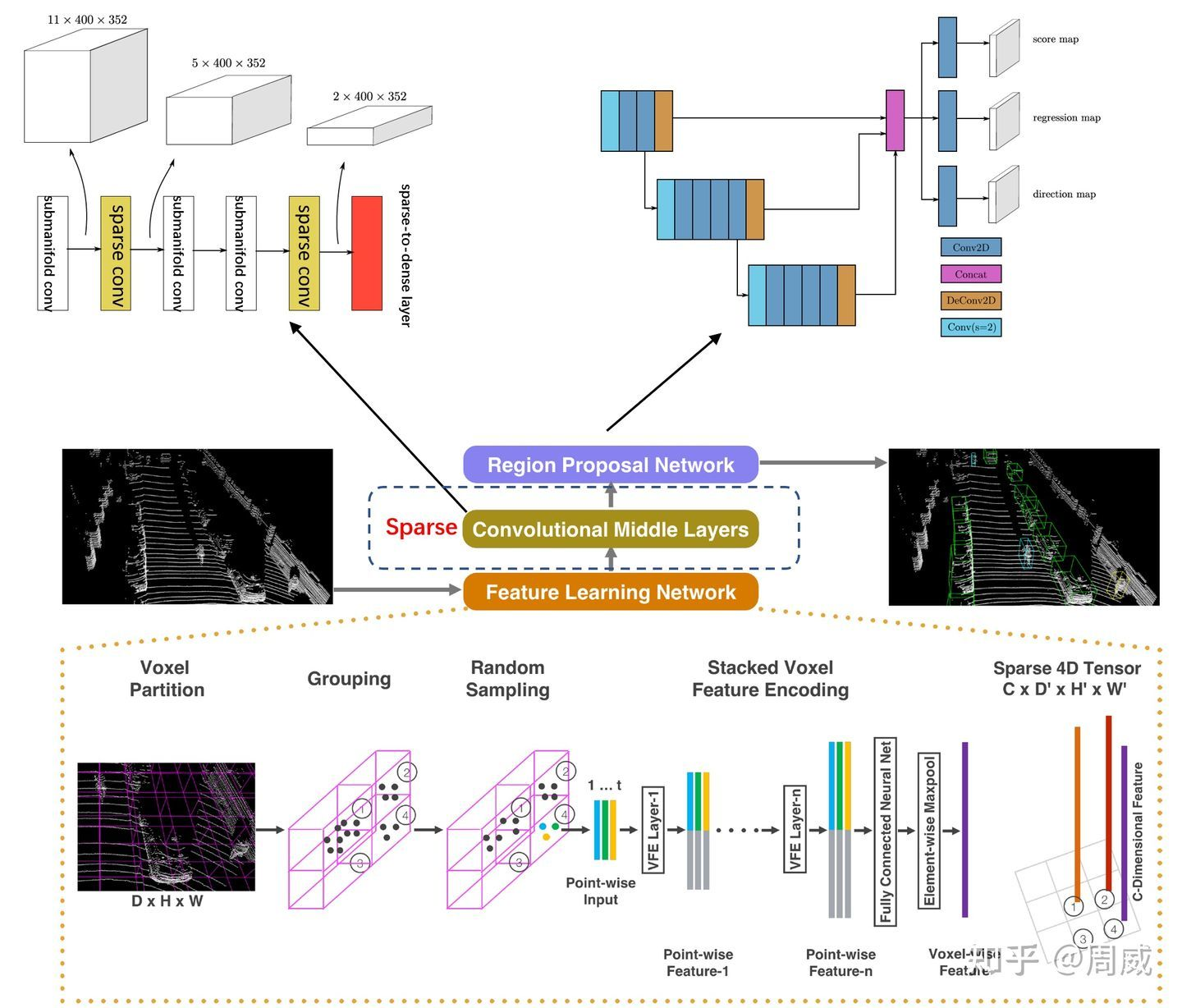
考虑到VoxelNet通过Feature Learning Network后获得了稀疏的四维张量,而采用3D卷积直接对这四维的张量做卷积运算的话,确实耗费运算资源。SECOND作为VoxelNet的升级版,用稀疏3D卷积替换了普通3D卷积。
这里我们直接给出VoxelNet的结构图,然后再此基础上进行修改,获得SECOND的网络结构图,分别如下两张图所示。


2.1 稀疏卷积
作者在VoxelNet的Convolutional Middle Layers的基础上引入了Sparse Convolutional Middle Layers,稀疏卷积就用在这个模块里面。
作者在论文中提到:
We need to gather the necessary input to construct the matrix, perform GEMM, and then scatter the data back. In practice, we can gather the data directly from the original sparse data by using a preconstructed input–output index rule matrix.
如下图所示,可以归纳为:
- 将稀疏的输入特征通过gather操作获得密集的gather特征;
- 然后使用GEMM对密集的gather特征进行卷积操作,获得密集的输出特征;
- 通过预先构建的输入-输出索引规则矩阵,将密集的输出特征映射到稀疏的输出特征。
这个输入-输出索引规则矩阵很明显就是稀疏卷积的关键所在了。

这里简单说一下输入-输出索引规则矩阵的生成规则。作者在原文中提到:
A more direct approach to rule generation is to iterate over the input points to find the outputs related to each input point and store the corresponding indexes into the rules. During the iterative process, a table is needed to check the existence of each output location to decide whether to accumulate the data using a global output index counter.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3082
3082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









