override def compute(theSplit: Partition, context: TaskContext): InterruptibleIterator[(K, V)] = {
val iter = new NextIterator[(K, V)] {
val split = theSplit.asInstanceOf[HadoopPartition]
logInfo("Input split: " + split.inputSplit)
val jobConf = getJobConf()
val inputMetrics = context.taskMetrics.getInputMetricsForReadMethod(DataReadMethod.Hadoop)
// Sets the thread local variable for the file's name
split.inputSplit.value match {
case fs: FileSplit => SqlNewHadoopRDDState.setInputFileName(fs.getPath.toString)
case _ => SqlNewHadoopRDDState.unsetInputFileName()
}
// Find a function that will return the FileSystem bytes read by this thread. Do this before
// creating RecordReader, because RecordReader's constructor might re








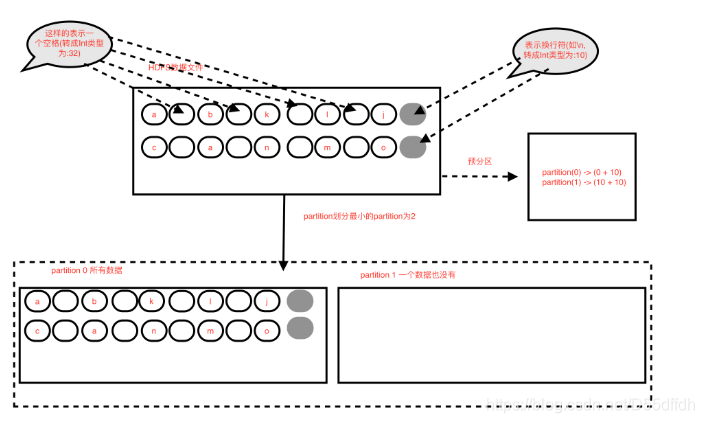
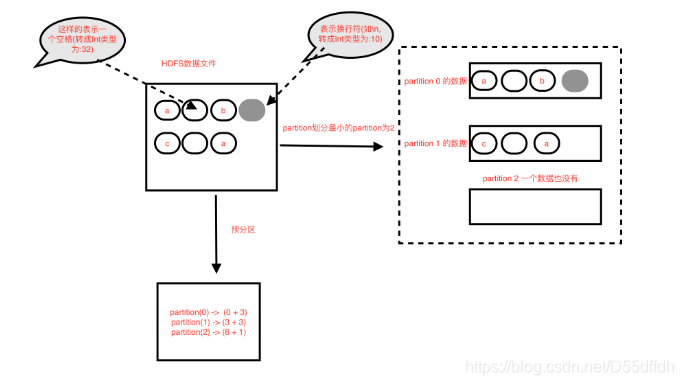
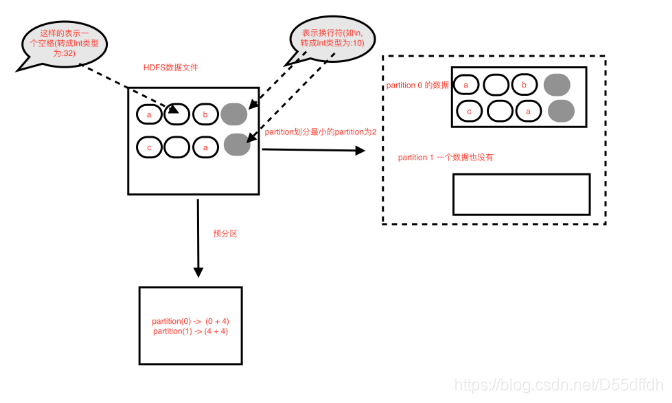
 本文详细分析了Spark HadoopRDD如何读取HDFS文件,包括HadoopRDD的预分区计算方式、分区划分原理以及可能遇到的特殊情况,如非首个partition可能分不到数据的情况,并提供了源码分析链接。
本文详细分析了Spark HadoopRDD如何读取HDFS文件,包括HadoopRDD的预分区计算方式、分区划分原理以及可能遇到的特殊情况,如非首个partition可能分不到数据的情况,并提供了源码分析链接。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2315
2315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









